百亿级分布式文件系统之元数据设计
前言
在上一篇《如何实现支持百亿级文件的分布式文件存储》中,我们简单“鸟瞰”了实现支持海量文件的分布式文件存储的关键思路,本文我们开始讨论各个模块的设计思路和部分细节。先从元数据服务开始,元数据服务一般被简称为MDS,表示MetaData Service,或MetaData Server。
MDS数据在磁盘中如何管理
当我们说要做支持百亿文件的MDS时,我们要做什么?
我们先从业务需求说起。绝大多数业务,尤其是传统业务,都是习惯使用文件系统的,因为各种编程语言都提供了丰富的文件接口SDK,不同的业务根据数据规模使用本地文件系统或NAS。
我们先以本地文件系统ext4为例,来看一下ext4文件系统的特点。
- ext4是针对HDD设计的,基于内核VFS框架。为了实现更好的性能,ext4提供给用户使用的接口一般是buffered IO接口,读写都经过pagecache,写数据并不直接落盘,且元数据(inode)也不直接落盘。更进一步地,ext4使用了journal jbd2,默认模式是ordered,表示仅记录元数据的变动,这个journal也不是实时落盘的。ext4这么做是为了提供更好的IO性能,但在机器掉电时是可能丢数据的。
- 如上面提到的,ext4是HDD时代的产物,面对SATA SSD甚至是PCIe SSD时力有不逮,发挥不出硬件的全部性能。
- ext4会对硬盘预格式化,格式化后inode数量固定,能支持的文件数量也随之固定。当面对海量小文件场景时,inode率先耗尽,而硬盘实际仍有大量空余空间。
- ext4是没有“原子读写机制”的,即如果业务有一个操作,需要read file1, write file2, write file3都成功才认为成功,则业务需要自己去做这个组合的原子逻辑,ext4无法提供现成的回滚机制。
不少分布式文件系统是基于本地文件系统的,它们都将面临以上提及的这些问题。市面上大多分布式文件系统的MDS是基于本地文件系统的,例如ext4。而有的分布式文件系统则直接用本地文件表示业务文件,即用户视角的一个文件,对应MDS ext4里的一个或多个文件,这种方式要面对上面提到的所有问题。还有的分布式文件系统是在ext4之上有自己的封装,比如将文件信息抽象为KV,运行时在内存中用std::map之类的数据结构表示,并实现LRU机制,换入换出到底下ext4中,这种方式会面临上面问题的第1、2、4点,同时引入了不少工程复杂度,可以理解为这种方式做到极致就是RocksDB的特定实现。
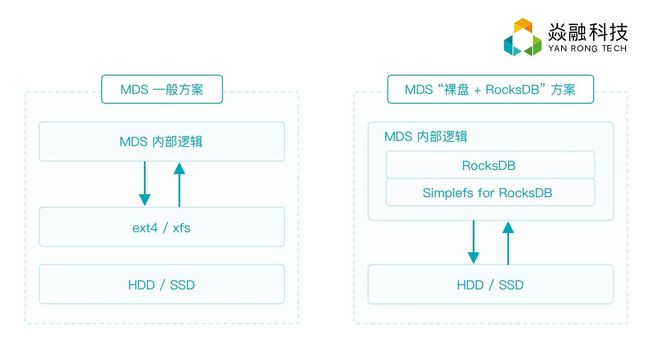
经过以上分析,设计MDS时,可以不使用本地文件系统,而是选择使用RocksDB。大家知道RocksDB也是基于文件模型的,如果MDS使用RocksDB,但RocksDB使用ext4,那么整个MDS仍然会受到ext4带来的性能限制。我们了解到RocksDB并不强依赖文件系统,因此理想的MDS并不使用ext4,而是直接管理裸盘,并提供一个薄层文件模型去满足RocksDB的运行需要。这块内容较多,我们在下一篇文章来专门讨论MDS基于裸盘的RocksDB方案的细节。
MDS如何切片
我们之所以讨论MDS的切片问题,实际上是探讨如何将整个文件系统的元数据通过一定逻辑放置在一台或多台MDS节点中。
当使用单台服务器做MDS时,基于裸盘使用RocksDB的方案,相比于直接使用本地文件系统,已经能管理更多的文件了,但单MDS仍有其限制,比如单MDS支持的文件数量始终存在上限,单MDS对并发请求的处理能力也存在上限。
所以为了设计和实现一个能承载百亿文件的MDS,必然要做元数据切片,使用多台服务器组成MDS集群,每个MDS节点管理部分元数据。
接下来,如何对元数据进行切片就成为核心问题。经过调研和积累,我们认为,理论上“静态”切片的方法是不能满足所有场景的需求的。直观上这非常好理解,正如上一篇提到的,我们做大型系统面临的都是抉择,不会有银弹式完美解法。这里“静态”切片方法是指不考虑动态均衡的切片方法,比如通过哈希将新目录定位到指定MDS节点。
我们先来讨论切片方案面临的挑战:
挑战1:每个切片的数据量是否均衡?
挑战2:每个切片的IO性能是否均衡?
挑战3:每个切片的访问量是否均衡?
挑战4:如何有效实现range query,如ls等常用文件系统操作?
对于挑战1,在实践中,我们认为元数据量是否严格地均衡并不那么重要,我们只要能做到不要让某个MDS空间被撑爆,而同时其余MDS节点剩余大量空间就行。但如果元数据节点的存储空间消耗差距大,可能会影响到MDS的访问性能,这主要是因为数据量大之后内存LRU的影响和数据索引的影响。
所以,我们尽量去保持元数据空间消耗的均衡。但元数据空间消耗是动态变化的,我们一般会按目录去定位以及分片,比如通过哈希将某个目录定位到指定的某个MDS,目录刚开始为空,但随着时间推移,该目录下的文件会逐步越写越多。
另一个麻烦的问题是如何处理访问热点。元数据切片固定之后,可能出现热点目录刚好都在同一MDS节点的情况,如果某个切片下的某个目录或某些目录被高频访问,就会形成热点,假如该MDS不能支持这么大的访问量,而其他MDS却十分空闲,这样既浪费资源,又影响性能。
至于挑战4,ls等操作是用户常见操作,当目录下文件很多时,ls操作耗时会很长,本地文件系统如此,一般分布式文件系统更甚之。如果我们的切片策略尽量让一个目录的元数据放置于单个MDS上,那么切片并不会带来更多的ls耗时。
那么理想的分布式文件系统应该采取什么样的元数据分片方案?我们深入思考上面的挑战,正如我们反复提到的一点,大型系统通常需要在各种问题和挑战之间寻找平衡点,或者做动态的平衡。因此我们给出的核心设计思路是,给定统一命名空间的目录树,以目录为单位,将目录树拆分到不同MDS上,这样保证了数据本地化。至于拆分时的策略是通过hash,还是通过指定,其实已经无所谓了,我们可以采取hash策略,即对于给定目录的元数据,通过hash为其指定一个所属MDS。
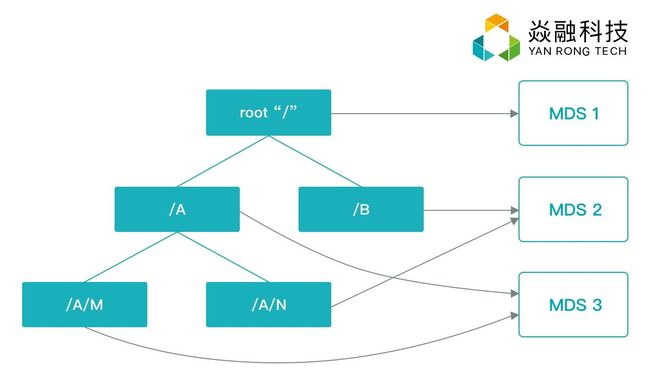
关于MDS切片这一主题,Ceph SC04发表的论文”Dynamic Metadata Management for Petabyte-scale File Systems”也做了讨论(关注本公众号,回复“SC04”获取论文),通过阅读这篇论文,并延展阅读它引用的一些论文,我们发现基于目录树并以目录为基本单位的切片方案,不失为一个直观的、合理的切片方案。这篇论文采取了相同的思路,但采用了不同的细节方法,也做了更为严谨的实验和分析,值得大家去扩展阅读。
当然采用hash的方式对元数据按照目录进行划分,也不是万能方案,我们还需要通过其他手段去处理这个方案带来的问题:
将每个MDS节点优化到极致,使得其能够支持足够多的数据,这样,即使单目录的元数据被hash到某个节点,元数据“静态”划分的方案,仍能支持海量文件。此外,通过对共享读写关键路径的lock critical section的优化,可以支持高并发访问,从而应对“热点”目录访问的挑战。这些都依赖于基于裸盘和RocksDB的设计,具体细节我们将在下一篇讨论。
手动触发的热点迁移、热点切分机制。支持百亿级别小文件的文件系统设计目标是被海量 (thousands of) 客户端共享访问的通用型文件系统,一般情况下,不会出现极端的热点场景,单个目录或几个目录的热点问题,通过单MDS的优化已经能够处理,但万一某个MDS管理的所有目录都是热点怎么办,我们需要设计通过命令触发的热点迁移机制,将热点迁移到空闲MDS。另外,如果万一某个MDS管理的所有目录下都有海量文件,那单MDS依然存在被撑爆的风险,我们还要设计热点切分机制,将该目录内部划分为多个虚拟子目录,将存放海量文件的目录或热点目录的元数据分摊到其他MDS上去。
MDS多副本机制
上面讨论了MDS设计中最重要的两大部分思路,MDS的数据放置和管理,以及元数据的切片方式。
除了这两大部分之外,作为一个分布式文件存储,肯定还要保证数据的可靠。我们使用的也是数据冗余机制,考虑到数据特点,我们推荐2副本,因为这在性能、功能和成本间有一个很好的折中。
使用副本机制有两大考虑点,一是副本放置策略,二是副本间数据一致性。
副本放置策略方面,结合MDS目录树切片方案,我们提供的是将MDS节点分组,每组根据副本数设置可以有多台服务器。每组MDS之间做副本冗余。这么做一是满足需求,二是设计和实现简单,三是可以起到物理隔离的作用,单台服务器故障的影响面更小。
副本间数据一致性是分布式领域常见的问题之一,业界有两大做法,分别是Paxos系和主从复制 (Primary Copy Replication)。Paxos系一般用于低频更新的核心数据的多副本机制,比如在一致性哈希系统中维护集群视图。MDS多副本这样的场景一般使用的是主从复制,这样既保证了一致性,也能保证一定的性能。IO先从client发给主MDS,主MDS写本地的同时,再发给从MDS,只有主从MDS都写成功,才认为本次IO成功并返回给client。
一样常见地,我们使用本地journal来保证本地的原子写,使用transaction log来保证故障下的主从恢复,同时基于transaction log我们也方便做主从同步写或是主从异步写的策略。
需要特别提出,相比使用ext4等本地文件系统,基于裸盘管理+RocksDB方案,实现本地journal和transaction log更为方便,效率也更高。
MDS设计要点总结
上一篇《如何实现支持百亿级文件的分布式文件存储》我们笼统地讨论了设计支持百亿级文件的分布式文件存储的思路,本文我们讨论了元数据集群MDS三大方面的设计思想:元数据管理方案、元数据切分方案和多副本机制。下一篇我们将讨论本地裸盘管理+RocksDB方案的设计和实现细节,后续我们还将不断地做其余组件的设计思路、方案和实现方面的讨论。
当然,文字表达不如当面讨论直观,文章再详细,也总会漏掉不少信息。我们主要讨论核心思路和模块,内部的各个小方面的实现选择和细节,不同实现都会有很多出彩之处,但出于篇幅和主旨,在文章里,我们就忽略了。我们非常欢迎有兴趣的朋友们留言讨论,也非常欢迎有兴趣的朋友们来实地面基,更是非常欢迎有兴趣的朋友们加入我们,一起去讨论、选择和实现更好的方案、更好的代码。
我们下一篇见。