Numpy库的介绍及使用
Numpy库的介绍及使用
- 1. Numpy库入门
-
- 1.1 数据的维度
- 1.2 ndarray的优势
- 1.3 ndarray对象的属性
- 1.4 ndarray数组的创建和变换
-
- 1.4.1 ndarray数组的创建方法
- 1.4.2 ndarray数组维度的变换
- 1.5 ndarray数组的索引和切片
- 1.6 ndarray数组的运算
- 2. 数据存取与函数
-
- 2.1 CSV存取数据
- 2.2 多维数据的存取
- 2.3 numpy的便捷文件存取
- 2.4 numpy随机数函数
- 2.5 numpy统计函数
- 2.6 numpy梯度函数
1. Numpy库入门
Numpy是一个开源的Python科学计算基础库。
- 一个强大的N维数组对象ndarray
- 提供广播功能函数,用来在数组之间进行计算
- 整合C/C++/Fortran代码的工具
- NumPy是SciPy、Pandas等数据处理或科学计算库的基础
Numpy的引用:
import numpy as np
其中 as np 为引入模块的别名,可省略或者更改,但是建议使用上述约定的别名。
1.1 数据的维度
-
一维数据:一维数据由对等关系的有序或无序数据构成,采用线性方式组织。对应python中列表、集合类型。
-
二维数据:二维数据由多个一维数据构成,是一维数据的组合形式。表格是典型的二维数据,其中表头是二维数据的一部分,对应python中列表类型。
-
多维数据:多维数据由一维或者二维数据在新维度上的扩展,比如表格在时间维度上的扩展,对应python中列表类型。
-
高维数据:高维数据仅利用最基本的二元关系展示数据间的复杂结构,对应python中字典类型或数据表示格式(JSON、XML、YAML格式)。
dict = {
"firstName": "Richard",
"lastName" : "Lee",
"address" : {
"city" : "长沙",
"zipcode" : "100081"
}
}
1.2 ndarray的优势
python既然有列表数据类型了,并且可以表示一维数据、多维数据,为什么还需要一个ndarray数据对象(类型)呢?
举一个简单的例子:计算 A 2 + B 3 A^2 + B^3 A2+B3 ,其中 A 和 B 都是一维数组
- 不使用Numpy:
def pySum():
a = [0, 1, 2, 3, 4]
b = [9, 8, 7, 6, 5]
c = []
for i in range (len(a)): # 需要使用for循环
c.append(a[i]**2 + b[i]**3)
return c
print (pySum())
- 使用Numpy:
import numpy as np
def pySum():
a = np.array([0, 1, 2, 3, 4])
b = np.array([9, 8, 7, 6, 5])
c = a**2 + b**3 # 把一维数组a,b直接当作两个基本数据进行运算
return c
print (pySum())
- 数组对象可以去掉元素间运算所需的循环,使一维向量更像单个数据。
- 设置专门的数组对象,经过优化,可以提升这类应用的运算速度。
- ndarray是一个多维数组对象,由两部分组成:
- 实际的数据
- 描述这些数据的元数据(数据维度、数据类型等)
- ndarray数组一般要求所有元素类型是相同(同质)
ndarray实例
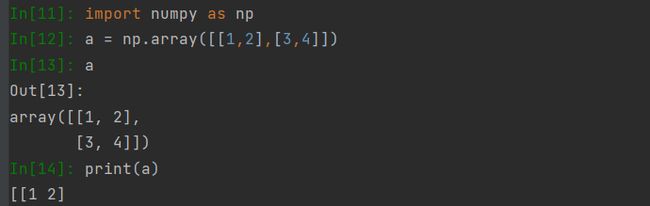
注意:在执行12行的时候不要少了个 [] ,
a = np.array([[1,2],[3,4]]) ✔
a = np.array([1,2],[3,4]) ❌ , 这里需要将整个列表 [[1,2],[3,4]] 转换成一个ndarray对象
1.3 ndarray对象的属性

举例如下:

1.4 ndarray数组的创建和变换
1.4.1 ndarray数组的创建方法
- 从Python中的列表、元组等类型创建ndarray数组
- 使用NumPy中函数创建ndarray数组,如:arange,ones,zeros等
- 从字节流(raw bytes)中创建ndarray数组
- 从文件中读取特定格式,创建ndarray数组
(1) 从Python中的列表、元组等类型创建ndarray数组
x = np.array(list/tuple)
x = np.array(list/tuple,dtype=np.float32)
当np.array()不指定dtype时,NumPy将根据数据情况关联一个dtype类型。
(2)使用NumPy中函数创建ndarray数组,如:arange,ones,zeros等,如下图:

举例如下:

注意:
- np.arange()默认生成的是元素是整数类型的
- np.ones()、np.zeros()、np.eyes()默认生成的是浮点类型的(可通过指定dtype改变数据类型)
np.ones((2,3,4))表示最外层有2个元素,每个元素有3个维度,每个维度下又有4个元素
在进行大规模的科学计算时常使用到的函数如下:


举例如下:

注意:
np.linspace(1,10,4,endpoint=False)中1表示起始的位置10表示的是结束的位置,4表示有几个数字 ,endpoint=False表示不包括结束的数据。- numpy大部分函数默认都生成浮点数,因为用于科学计算的数据很多都是浮点类型。
1.4.2 ndarray数组维度的变换
.reshape(shape):不改变数组元素,返回一个shape形状的数组,原数组不变.resize(shape):与.reshape()功能一致,但是修改原数组.flatten():对数组进行降维,返回折叠后的一维数组,原数组不变

.reshape() 和 .resize()相同点是都不改变数组元素,不同点是.reshape()不改变原数组,.resize()是修改了原数组。举例如下:

利用 .flatten() 函数对数组进行降维,返回折叠后的一维数组,原数组不变,举例如下:

利用astype() 函数对ndarray数组进行类型变换,astype()方法一定会创建新的数组(原始数据的一个拷贝),即使两个类型一致。举例如下:

ndarray数组向列表的转换,列表是python中最原始的数据类型,虽然运算速度比numpy慢很多,但是与原生的python语言相适应的程序中,这种转换也是十分常见的

1.5 ndarray数组的索引和切片
- 一维数组的索引和切片

- 多维数组的索引

- 多维数组的切片

注意:从左到右索引时起始位置是从0开始的,从右到左索引时起始位置是从-1开始的。
1.6 ndarray数组的运算
- 数组与标量之间的运算
数组与标量之间的运算作用于数组的每一个元素 - numpy一元函数
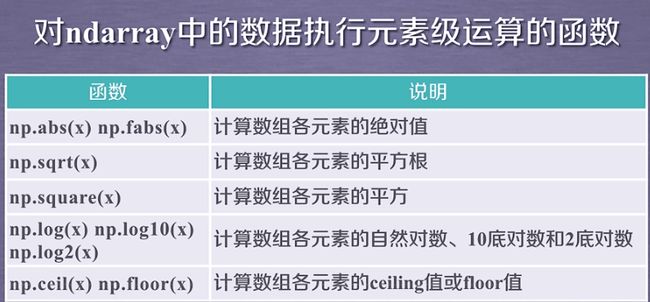

- numpy二元函数

2. 数据存取与函数
- CSV文件(Comma-Separated Value,逗号分隔值)

2.1 CSV存取数据
(1)CSV写入数据:np.savetxt()
np.savetxt(fname, array, fmt='%.18e', delimiter=None)
-
参数说明:
- fname:写入的文件、字符串或产生器,可以是.gz或bz.2的压缩文件
- array:存入文件的数组
- fmt:写入文件的格式,例如%d、%.2f、%.18e
- delimiter:分割字符串,默认是任何空格
-
CSV写入数据举例

(2)CSV读入数据:np.loadtxt()
np.loadtxt(fname, dtype=np.float, delimiter=None, unpack=False)
-
参数说明:
- fname:指定读入的文件来源,可以是文件、字符串或产生器,也可以是.gz或.bz2的压缩文件
- dtype:数据类型,可选
- delimiter:分割字符串,默认是任何空格
- unpack:如果是True,读入属性将分别写入不同变量
-
CSV读入数据举例

注意:CSV文件的局限性表现在只能有效存储一维和二维数组
2.2 多维数据的存取
(1)多维写入数据:tofile()
a.tofile(fname, sep='', format='%s')
-
参数说明:
- fname:文件、字符串
- sep:数据分割字符串,如果是空格,写入文件为二进制
- format:写入数据的格式
-
多维写入数据
tofile()举例

注意:tofile()方法只是将数组中的元素逐一列出并输出到这个文件中,而没有包含任何的维度信息
(2)多维读入数据:np.fromfile()
np.fromfile(fname, dtype=float, count=-1, sep='')
-
参数说明:
- fname:文件、字符串
- dtype:读取的数据类型
- count:读入元素个数,-1表示读入整个文件
- sep:数据分割字符串,如果是空串,写入文件为二进制
-
多维读入数据
np.fromfile()举例

注意:该方法需要读取时知道存入文件时数组的维度和元素类型; a.tofile()和np.fromfile()需要配合使用;可以通过元数据文件来存储额外信息(尤其针对大规模数据的存取)
2.3 numpy的便捷文件存取
- 写入数据
np.save()或np.savez()
np.save(fname,array)或np.savez(fname,array)
-
参数说明:
- fname:文件名,以
.npy为扩展名,压缩扩展名为.npz - array:数据变量
- fname:文件名,以
-
读入数据
np.load()
np.load(fname)
-
参数说明:
- fname:文件名,以
.npy为扩展名,压缩扩展名为.npz
- fname:文件名,以
-
np.save()和np.load()举例

2.4 numpy随机数函数
- np.random的随机数函数:
rand(d0,d1,...,dn) # 均匀分布
randn(d0,d1,...,dn) # 正态分布
randint(low[,high,shape) # 指定范围
seed(s) # 随机数种子

- seed(s)举例:

2.5 numpy统计函数
numpy直接提供的统计类函数,通过 np.* 来调用,比如 np.std()、np.average() 等
sum(a,axis=None) # 根据axis计算数组a相关元素之和
mean(a,axis=None) # 根据axis计算数组a相关元素的期望
average(a,axis=None,weights=None) # 根据axis计算数组a相关元素的加权平均值
std(a,axis=None) # 根据axis计算数组a相关元素的标准差
var(a,axis=None) # 根据axis计算数组a相关元素的方差

sum()、mean()、average()、std()、var() 函数举例:

2.6 numpy梯度函数
np.gradient(f) # 计算数组f中元素的梯度,当f为多维时,返回每个维度梯度
梯度函数 gradient() 举例:
