用文本指导文本:基于文本的自监督可控文本生成模型

论文标题:
CoCon: A Self-Supervised Approach for Controlled Text Generation
论文作者:
Alvin Chan, Yew-Soon Ong, Bill Pung, Aston Zhang, Jie Fu
论文链接:
https://arxiv.org/abs/2006.03535
可控文本生成
过去的几年学界对可控文本生成(CTG)的研究逐渐开始增多,已经在情感控制、主题控制、写作风格控制等方面取得了较为突出的成就。
比如给定的控制变量是情感中的“积极”,给定的输入句子是“这个电影真难看”,那么模型就会生成满足变量的、在语义上和源句子保持一致的目标句子“这个电影真好看”。
和传统的语言模型相比,CTG显然有更好的应用场景:在小说创作中,可以给定人物、场景的一些变量然后让模型生成符合条件的文本,而不是凭空想象凭空捏造出一些剧情。
一个CTG模型可以看作是一个标准的Seq2seq模型,编码器编码源句子,解码器接受编码特征和给定条件,生成对应句子。
但现存的一大问题就在于“给定的条件”——当前的大多数模型研究的是一些简单的变量,比如从积极到消极情感控制,从科学到政治的主题控制,从书面语到口语的表述控制,这在实际应用中是非常受限的。
一方面,这些给定的变量范围非常狭隘,要么是情感,要么是主题;另一方面,现实中人们往往倾向用句子表达想要控制的内容而不是像机器一样用结构化的数据。
本文基于以上现状,提出以文本为控制变量实现CTG。本文所提出的模型称为CoCon,除了标准的编码器和解码器之外,还用了一个轻量级的CoCon模块用于融合控制文本与输入文本的信息。
由于文本生成的空间理论上是无穷大的,标注语料很难获取,所以CoCon采用了自监督的方式训练,提出三种自监督损失,在预训练的语言模型GPT2上继续训练,从而取得好的in-domain效果。
用文本指导文本的好处在于,文本不需要进行结构化,让模型自行学会控制,而且可以输入若干控制文本,只需要把它们拼接成一段文本即可,这比结构化的变量更加灵活。
总的来说,本文的贡献如下:
提出CoCon,一个基于文本变量的可控文本生成模型;
提出三个自监督学习损失,用于训练CoCon;
文本型CTG比结构化控制变量模型更加灵活和通用;
实验结果表明相比PPLM和CTRL,CoCon能生成高质量的文本。
模型:CoCon
模型结构
CoCon的基本流程是,给定一段引导文本 和一段控制文本 ,模型去生成和 保持流畅,内容上大致包含 的文本 ,和 一起形成一段完整的文本 ,其中 。这个过程可以用一个Seq2seq模型表达:

下图是CoCon的模型结构。首先用一个编码器(enc)分别编码给定的引导文本 和控制文本 ,得到它们的特征 和 ,然后把这两个送到CoCon模块中,通过自注意力让它们交互,得到对应的新的特征 ,然后再像语言模型一样通过去预测下一个词 。
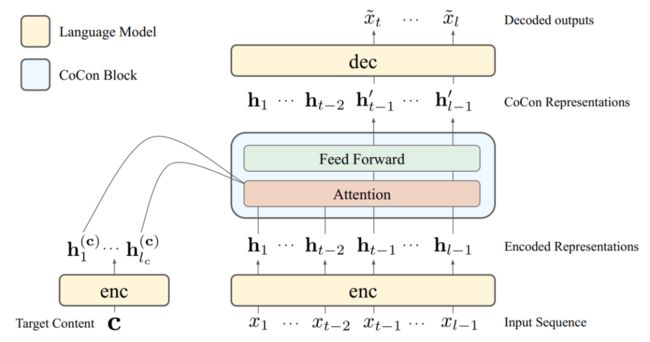
编码器和解码器我们在此不多赘述,主要介绍Cocon的实现。CoCon是一个单层Transformer Block,也就是Self-Attention->FFN的模式。首先得到引导文本和控制文本的Q,K,V:
![]()
然后把它们的K和V分别拼接起来,再经过自注意力:
![]()
注意到这里的 是引导文本产生的,因为控制文本只用于K和V。 是注意力矩阵的权重。在得到 之后,再经过一个FFN,就得到了CoCon的输出,再把这个输出作为解码器(dec)的输入,就可以像语言模型一样一个词一个词地生成了。
那么如果有多个控制文本 怎么办呢?只需要把它们拼接起来作为一个整体就好了。
最后,我们还可以在注意力权重矩阵 上加一些偏置项 ,以调整对控制文本 的关注程度。
损失函数
介绍了模型结构,下面就要考虑如何训练CoCon。显然,我们没有现成的监督语料,只能用无监督的方式完成。
下面假定任何一个句子 可以分为两部分 , 就可以当做引导文本, 就是要生成的文本,现在的问题是,控制文本 是什么。
自重构损失
自重构损失 就是让控制文本 ,之后要生成的就是 自己,这一步是为了让模型能够学习结合控制文本的内容。
无文本损失
第二个损失无文本损失 ,即令 ,这时候CoCon退化为一个简单的语言模型,这是为了能够生成流畅的文本。
循环重构损失
只有上面两个损失当然不过,循环重构损失 通过两个不同文本互为控制文本来生成质量更高的文本。假定现在有两个不同的文本 ,进行如下操作:
首先将 作为引导文本,将 作为控制文本,生成新文本 。显然, 的目的是在和 保持流畅,且尽可能包含 的内容;
再将 作为引导文本,将 作为控制文本,生成新文本 。这里想让 和 保持流畅,且尽可能包含 的内容;
既然 包含 的内容,而 又包含 的内容,要么就是要 包含 的内容,且要和 保持流程,这不 就是 本身吗!
所以, 就是以 为真值去优化 ,反过来也可以以 为真值去优化 。
对抗损失
最后是过去的工作都会用的对抗损失 ,即让生成的文本接近真实的文本:

这里 是原来的文本, 是生成的文本。
把上面四个损失合起来就是最后要优化的目标:

实验
任务
本文在三个可控文本生成任务上实验:情感可控生成,主题可控生成,文本可控生成。
模型
CoCon采用预训练的GPT2作为模型主干,前7层是编码器,后17层是解码器,固定所有参数,只训练CoCon模块;采用BPE编码, 的划分随机地在第8到第12个BPE位置产生。
默认使用 和 。由于GPT2的参数是固定的,所以训练CoCon仅需在单个V100上训练不到24小时。
其他实验设置详见原文。
文本引导文本生成
文本引导的文本生成评估指标有BLEU、NIST、METEOR、PPL和Dist-1/2/3。由于没有现成的该任务的数据集,故本文随机从预训练的GPT-2中采样3000个样本,均匀分为三组,每组的控制文本 的长度为5,10,20个BPE长度,所生成的句子 长度都是100。把它们作为测试集。
训练集则是随机从GPT-2所产生的句子中获取。此外,CoCon还在大小为250K的Webtext上训练,以探究不同训练数据来源的影响。
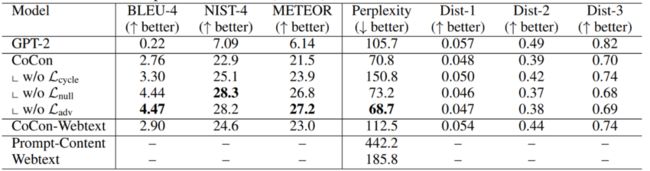
结果如下表所示。可以看到,CoCon在结合控制文本 上比GPT2好太多。在这个实验上,不加一些损失会有更低的PPL以及更高的BLEU、NIST、METEOR等值,比如去掉 或者 模型的BLEU值会更高,这是因为这两个损失相比之下更关注生成文本的流畅度而不是与控制文本 相结合。
主题可控文本生成
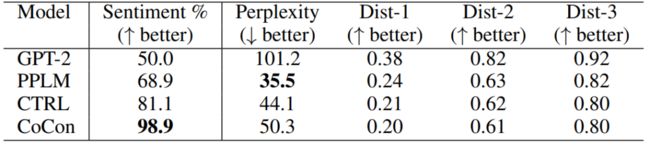
在主题可控任务上,比较的基线模型有PPLM和CTRL,都是当前很强的模型。为验证主题相关性,训练一个分类器用于评估主题程度。下表是实验结果:

CoCon所生成的文本和主题最相关,在PPL上三个模型都优于GPT2。
情感可控文本生成
情感可控任务采用二分类情感,下表是实验结果。和主题任务类似,CoCon在情感相关度上显著优于其他模型,这说明CoCon能够更加紧密地结合控制文本 。
实例分析
下图是不同的 生成的不同文本,显然,值越大就越和控制文本(Posotive)相关,但是越容易生成不相关的内容。

下图是多个控制文本一起输入时,CoCon生成的内容。第一个例子输入了三个控制文本:一段纯文本,一个主题和一个情感。
可以看到,生成的文本和这几个内容相关。第二个例子输入了两个控制文本:一段纯文本,一个主题。尽管生成的文本非常高深,但至少还是和控制文本贴合得很紧密。

小结
本文提出CoCon,一个以文本为控制变量的可控文本生成模型,能够更加全面地从多个角度控制文本生成的内容。CoCon完全依赖无监督训练,依靠预训练的GPT2,只需要训练CoCon模块的部分即可,训练非常高效。
从结果来看,CoCon所生成的文本能够很好地贴合给定的控制文本,而且能够保持文本整体的流畅。尽管生成的文本仍然不知所云,但这是当前所有文本生成模型的通病,至少CoCon在可控这一层面迈出了一步。
结合CoCon,未来可控文本生成的一个方向是从非结构化文本中提取出结构化信息作为控制变量。比如“乔峰爱上了阿朱”,就可以构造一个三元组(乔峰,爱,阿朱),那么把这个作为控制变量进行文本生成,可以有更广阔的应用前景。
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

