博通团队文本标签提取技术演进

文本标签提取技术实践与探索方案 | 相关论文入选顶会
| 导语 搜索、广告、推荐等场景都需要对内容的深入理解,而标签提取是内容理解中最常见的任务,本文介绍了博通内容理解中文本标签提取的技术实践和探索。目前博通内容理解的标签提取已广泛应用于公司的信息流、广告、搜索等业务中,相关的创新方案被ACL、AAAI等顶级会议录取。
搜索、广告、推荐等场景作为互联网时代最主要的三种信息获取方式,均需要对用户的兴趣和内容进行精准的匹配。在此过程中,对内容的理解至关重要。标签作为一种比较常见的内容特征,在内容理解中起着非常重要的作用。本文主要介绍我们在文本标签提取上的实践方案以及技术探索,所提出的两个创新技术方案:联合抽取与生成的统一模型和基于提示的受控生成模型,分别被ACL2021与AAAI2022录用。
博通内容理解平台由TEG 机器学习平台部NLP技术中心打造。平台目前提供65+种能力,涵盖了分类标签,内容质量、特定属性和基础能力等四个大类,支持图文、视频和直播等主要内容形态,广泛应用于腾讯看点、微视、微信搜一搜、AMS广告等业务,平台日均调用量6亿+次。目前,博通内容理解平台已集成本文介绍的标签提取系统,欢迎大家体验和接入。
1、任务背景

图1 标签在推荐系统中的应用
在内容理解中,通常将能体现文章主旨/主题的词或短语称为标签。标签提取任务的目标是为文章这样的无结构文本提取出结构化的标签,这样的结构化标签可以用于推荐系统的各个模块,如图1所示,标签提取的结果可以单独作为一路召回,或者作为离散特征用于粗排、精排、构建用户画像等。对推荐系统起着重要的作用。此外,标签提取任务在学术界以Keyphrase Prediction的任务形式同样受到NLP研究人员的关注,每年的各大NLP相关的顶会上均有该任务相关论文的发表。
2、技术方案
2.1 实体标签提取
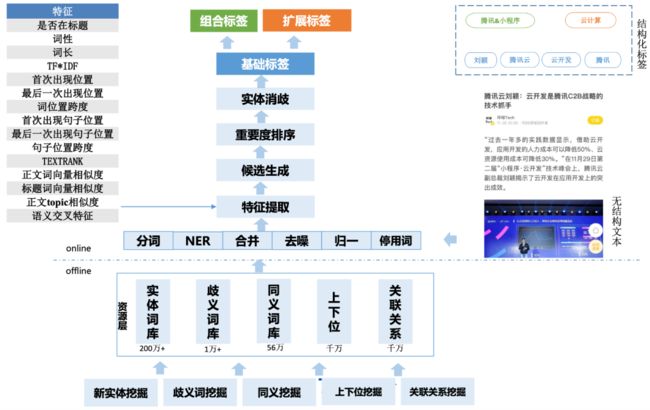
图2 实体标签提取系统
实体标签是指的文中重要的实体词,这样的词通常会显式的出现在文中。针对实体标签提取任务,如图2所示,我们将其分成了离线词典挖掘与在线实体标签抽取两个模块。对于离线词典挖掘,我们设计了包括实体词挖掘、歧义词挖掘、同义词挖掘等多个离线词典,这些词典对于在线实体标签抽取的各个阶段起着重要作用。对于在线实体标签抽取模块,由于实体标签通常会在文中直接出现,因此我们采用了候选提取+重要度排序的思路从文中提取出相应的标签。在候选提取阶段,我们首先对原始文章进行了分词、去噪、归一等处理,在此基础上我们设计了多种能衡量候选标签在文中重要性的特征,并在这些特征下通过一个重要度排序模型得到初步的实体标签的结果,最后设计了一个实体消歧模块得到最终的实体标签的结果。
2.2 语义标签提取

图3 实体标签问题分析
我们通过分析数据发现。对于推荐系统而言,仅仅只有实体标签是不够的。如图3中的文章会提取出广西、螺蛳粉等实体词。然而只提取这些词会存在无法精准描述用户兴趣的问题。以广西为例,其含义相对而言较泛,带有“广西”标签的用户可能只是对广西美食感兴趣、或者对广西房价感兴趣;只提取出广西,无法反映出用户的真实兴趣,在召回时就容易返回用户不感兴趣的内容;针对这篇文章提取出广西美食更加合适。我们将类似于广西美食能更细致反映用户兴趣的标签称为语义标签。我们希望除了基础粒度的实体术语外,还能够提取出语义标签。
2.2.1 基于匹配的标签提取方法
首先我们尝试了基于匹配的语义标签提取方法。具体而言,我们参照了实体标签提取,采用了离线词典挖掘+在线匹配的方案。
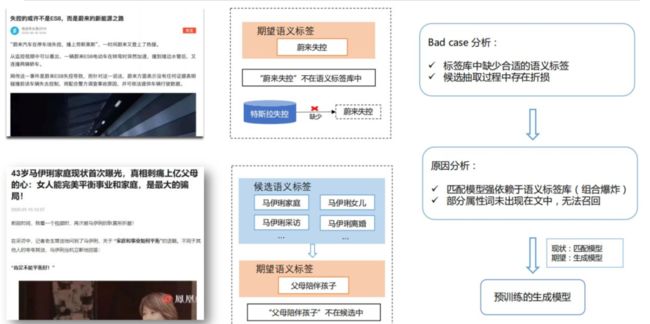
图4 匹配式方法问题分析
虽然匹配方法起到了较好的效果,但匹配模型本身存在天然的缺陷,我们分析badcase发现,主要存在两大类问题:
-
标签库中缺少合适的语义标签:比如图4中文章1我们希望能抽取出“蔚来汽车失控”,但其不在语义标签库中,导致无法提出期望的语义标签;由于语义标签可以看作是一个中心词+属性词组合的结果,这样的组合过程存在组合爆炸的问题,所以语义标签库难以挖掘得到类似于蔚来失控这样的偏长尾的短语,而匹配模型强依赖于标签库;
-
候选抽取过程中存在折损:这里主要是因为部分属性词未出现在文章,导致期望的语义标签在候选提取阶段难以召回,如图4中文章2的“陪伴孩子”就没有出现在文中,从而导致“父母陪伴孩子”没有出现在侯选中;
由于存在这两类问题,因此我们希望通过摆脱匹配模型这样的模式,从而解除对语义标签库及候选提取过程的依赖,我们希望能通过生成模型来解决这样的问题。
2.2.2 端到端的标签生成方法
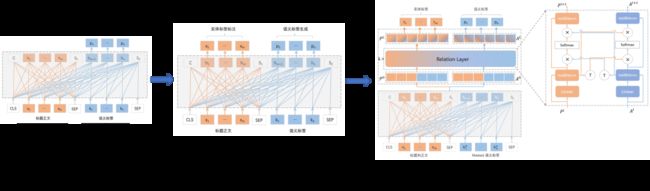
图5 端到端生成式方法演进过程
为了实现语义标签的生成,我们引入了UNILM这样的预训练生成模型,其特点是既能做自然语言理解,也能做自然语言生成,在做生成时主要是依赖于seq2seq的掩码规则实现。具体到语义标签的生成,我们首先尝试了如图5中的(a)所示的生成方法,我们将文章作为模型的输入,希望模型能输出对应的语义标签,从而实现标签的生成。通过实验发现生成模型在整体效果尤其是召回上有了较大的提升。
通过对比匹配模型与生成模型的效果,我们发现虽然召回有明显提升,但准确率下降了。我们分析因为生成模型是在一个开放集合下得到语义标签,结果不受语义标签库的约束,导致准确率下降。通过前面的分析可以知道,语义标签通常是实体标签的扩展或细化,其一般与文章实体标签密切相关,对语义标签的提取有一定指导作用。因此我们设计了增加实体标签辅助任务去帮助语义标签生成,具体如图5中的(b)所示,模型需要同时学习两个任务,即分别需要对文章内容进行实体标签标注和语义标签生成。
我们发现加入辅助任务后准确率有明显提升,但召回略有下降,整体效果提升不明显。我们分析是因为序列标注和生成部分交互不充分,因为原始UNILM是在统一的框架下分别完成NLU与NLG任务,而我们的任务需要同时完成两项任务,因此需要有更强的交互。因此我们在UNILM基础上增加了一个关系网络层,如图5中的(c)所示,该层主要是用于建模实体标签标注与语义标签生成两个任务的交互。具体的我们通过两个任务表示P和A之间的互相attention操作实现任务的交互。最终在交互后的表示上进行预测。通过表1给出的在业务数据集上的实验结果可以看到,加入交互机制后生成效果有了较好的提升。
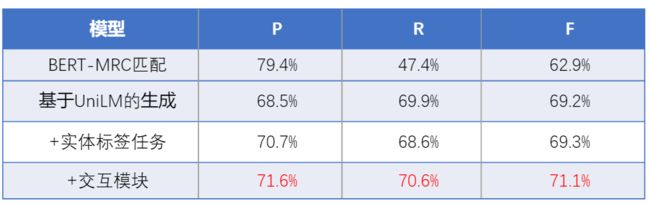
表1 在业务数据集上模型效果对比
除了在业务数据上的实验之外,我们还将联合实体标签提取与语义标签生成的技术方案在业界的Keyphrase Prediction Benchmark上进行了验证。Keyphrase Prediction任务通常会将待提取的keyphrase分为present keyphrase(出现在原文中的keyphrase,类似于本文提到的实体标签)和absent keyphrase(未出现在文中,类似于本文提到的语义标签)。已有的keyphrase prediction方法通常是将两类keyphrase拼接成一个文本序列,按照seq2seq生成的方案进行建模。这样的方法未显式的建模两类keyphrase间的关系。参照我们在业务数据集上的分析发现,在Benchmark上的两类keyphrase间存在形态上的差异与语义上的关联。因此,我们按照上述提到的联合抽取与生成的骨架网络显式的区分两类keyphrase进行建模,此外,额外引入的交互层被用于建模两类keyphrase间语义上的关联。
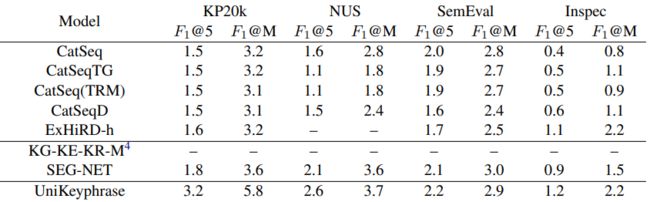
表2 在Keyphrase Prediction Benchmark与已有方法效果的对比
我们在多个公开数据集上验证了方法的效果,实验结果如表2所示,可以看到我们提出的方法具有较好的效果。我们将整体方案形成了论文UniKeyphrase: A Unified Extraction and Generation Framework for Keyphrase Prediction,并被ACL2021 Findings录用。
论文链接:https://arxiv.org/pdf/2106.04847.pdf
2.2.3 基于提示的受约束生成方法
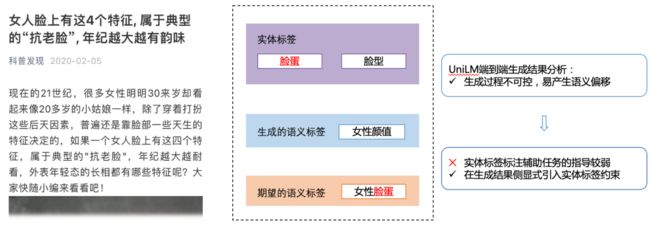
图6 端到短生成式方法问题分析
在端到端生成方法下我们通过case分析发现,该方案存在生成结果不可控的问题,体现在容易生成一些高频偏泛的结果,且容易产生语义漂移。例如这样一篇讲女性脸蛋的文章,生成模型容易生成出“女性颜值”,该短语并非是文章最重点的短语;我们可以看到“脸蛋”已经是文章的实体标签了,虽然之前的方案已经通过实体标签辅助任务去引导模型生成与“脸蛋”相关的短语,但这样的引导是隐式的且信号较弱。因此我们希望能在生成语义标签时显式的加入“脸蛋”这样的实体标签的约束。
为此,我们尝试将语义标签生成任务进行进一步转化,通过之前的分析我们发现可以将语义标签通常是实体标签加上属性词组合的结果,因此我们将其转换为一个在实体标签约束下的属性词生成任务。通过这样的任务形态转换,可以使得语义标签提取的结果受到实体标签的强约束,从而使得生成的结果更能反映原文重点信息。

图7 基于提示的约束生成方法示意
首先,我们尝试在实体标签两侧分别加上mask占位符后拼接上原文以实现这一过程。以图7给出的文章为例,我们在实体标签“江苏”两侧分别加上mask占位符,之后拼接上原文输入到预训练模型中,模型预测mask位置需要生成的字。该过程与模型预训练过程的目标是一致的。在得到mask位置相应的属性词之后,将属性词与实体标签组合后即可得到最终的语义标签。我们通过实验发现这样条件生成的结果效果不如端到端生成的结果,我们分析直接将带有mask的序列作为输入会与预训练解决的正常的句子在形态上存在差异。因此我们引入了辅助句作为提示语(prompt)的模式进行生成,主要出发点是使得属性词生成任务蕴含在一段自然文本中,更加贴近预训练的场景,有益于模型的学习。此外,在该模式下还可以便捷的实现非自回归推理,这可以显着加快生成过程。
通过实验我们发现引入辅助句后模型准确率有大幅度的提升。和之前的端到端生成任务类似,这里我们在属性词生成时也引入了实体标签标注的辅助任务,我们希望引入实体标签标注任务能够帮助模型对文章的理解。最终我们通过多任务的形式同时学习实体标签标注和属性词生成两个任务;实验发现,引入实体标签标注辅助任务后同样能带来效果上的提升。

表3 基于提示生成方法在业务数据集上效果对比
相应的创新技术方案我们也在业界的keyphrase generation benchmark上进行了验证。且将其形成了论文Fast and Constrained Absent Keyphrase Generation by Prompt-Based Learning,并被AAAI2022录用。下边将介绍我们的方法在通用数据集上的做法。
与业务数据集不同的是,业界benchmark并没有提供文章对应的实体标签。为此,我们提出了针对absent keyphrase两阶段生成方法,首先我们将文章与absent keyphrase和间重叠的部分定义为keyword (可视为是业务数据集上的实体标签)。在训练阶段,我们使用多任务模式训练了一个keyword抽取模型与带提示语的keyphrase生成模型,在推理阶段,我们首先了利用模型抽取得到文章的keyword,在此基础上利用基于提示语(prompt)的方法完成keyphrase的生成。图8给出了在通用数据集上模型预测与训练的过程示意图。
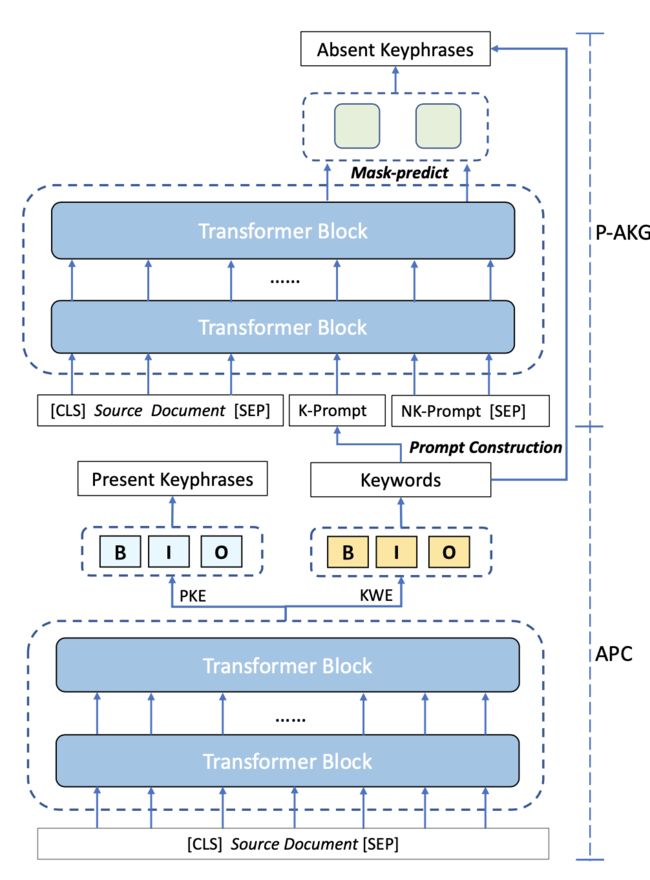
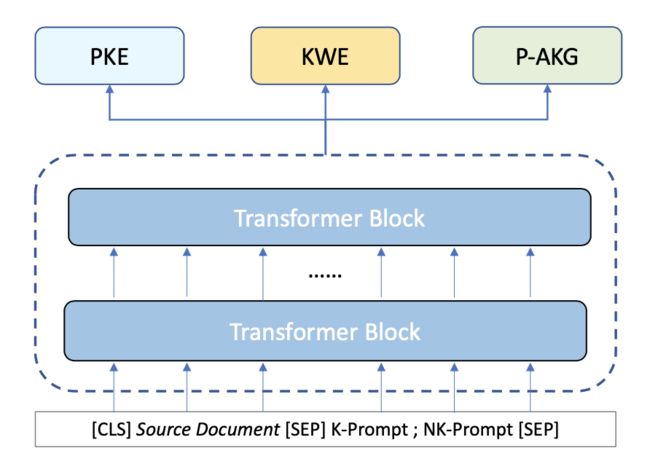
图8 模型预测(上图)与训练(下图)过程
具体而言,对于给定的文档和相应的keyword,我们的目标是构建受约束的absent keyphrase生成的prompt。具体来说,我们在本文中为约束生成定义了两种类型的prompt:
-
K-Prompt:对于文档中的每个keyword $KW,我们应用“phrase of $KW is [MASK] [MASK] $KW [MASK] [MASK]”作为prompt。可以通过结合 $KW 和掩码预测结果来获得最终的absent keyphrase。这样的prompt可以确保 $KW 出现在最终输出的keyphrase中。我们只取前 K 个keyword来构建prompt,以减少keyword提取中的噪音。
-
NK-Prompt:文档中也有一些没有keyword的keyphrase。对于这种情况,我们将prompt表示为“ other keyphrases are [MASK] [MASK] [MASK] [MASK]”。每个 [MASK] 位置的预测结果将被组合为absent keyphrase。这样的prompt可以提供生成与输入文档不重叠的关键短语的约束。
值得说明的是,在构建prompt时,K-Prompt 和 NK-Prompt 中的 [MASK] 标记的数量是超参数。这两种类型的prompt将被连接起来作为生成的最终prompt。图9给出了生成过程的示意。
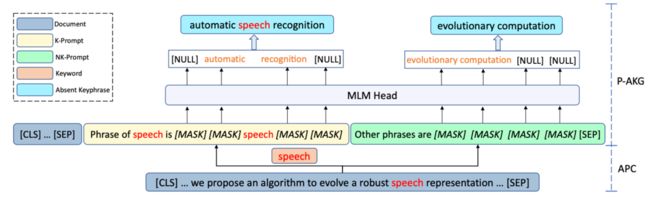
图9 基于prompt的absent keyphrase生成示例
如表4所述结果可以看到,在多个数据集上我们的方法都取得了较好的效果。另外,我们还探索了我们方法的上限,即在推理阶段,直接使用ground truth的keyword结果去构造prompt,从实验结果可以看到,在该设置下,absent keyphrase的生成性能可以得到较大幅度的提升。

表4 在Keyphrase Prediction Benchmark与已有方法效果的对比
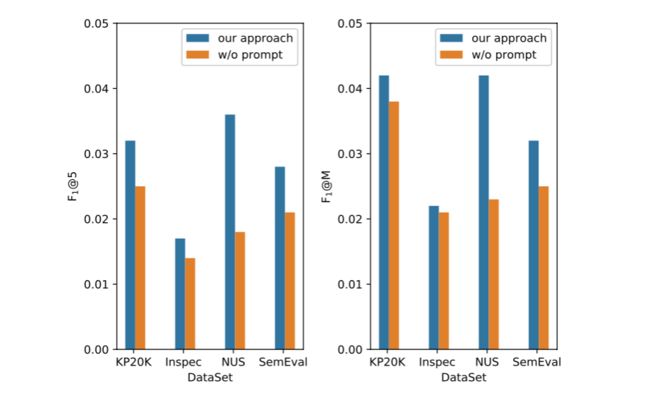
图10 使用提示语(prompt)对效果的影响分析
我们还对比了不使用prompt的生成方法,即在同样的模型框架下,仅使用mask-predict的范式进行生成,通过图10的实验结果可以看到,在各个数据集下效果均会下降,进一步验证了构造prompt的必要性。此外,基于prompt的约束生成方法将解码过程转换成了非自回归模式,模型的推理速度有了大幅度的提升。
论文链接:
https://www.aaai.org/AAAI22Papers/AAAI-4989.WuH.pdf
3、总结
本文介绍了我们在标签提取任务上的技术方案。首先简要介绍了实体标签提取方法,接着重点对语义标签提取的技术演进进行了详细的解析:匹配式的提取方法需要从候选语义标签库中选出正确的语义标签,相对来说比较简单,因此模型准确率较高。但强依赖于标签库,无法提取未出现在标签库或未出现在文章中的短语;端到端的生成模型,可以较容易的处理未出现在文章中的短语,但这样的方法生成过程不可控,易出现语义漂移的问题。此外这类模型在预测时需要从左往右依次生成每个字,耗时较大;基于实体标签约束的提示生成,可以较好的解决匹配模型无法处理absent keyphrase的问题,同时也可以缓解端到端生成模型存在的缺陷。本文提到的相关方法已应用于腾讯看点等信息流推荐业务中。此外,我们还将提出的方法在业界公开数据集上进行验证,相关的创新性方案也被AI顶会ACL和AAAI录用。
关注【腾讯太极机器学习平台】公众号
获取更多技术内容