YOLO系列目标检测算法——YOLOX
YOLO系列目标检测算法目录 - 文章链接
- YOLO系列目标检测算法总结对比- 文章链接
- YOLOv1- 文章链接
- YOLOv2- 文章链接
- YOLOv3- 文章链接
- YOLOv4- 文章链接
- Scaled-YOLOv4- 文章链接
- YOLOv5- 文章链接
- YOLOv6- 文章链接
- YOLOv7- 文章链接
- PP-YOLO- 文章链接
- PP-YOLOv2- 文章链接
- YOLOR- 文章链接
- YOLOS- 文章链接
- YOLOX- 文章链接
- PP-YOLOE- 文章链接
本文总结:
- 使用YOLOv3-SPP作为baseline,使用多种改进技术,形成了一个高性能的anchor-free检测器;
- 改进包括增加EMA权重更新、cosine学习率策略、IoU loss和IoU-aware 分支、训练时cls和obj分支使用BCE loss,reg分支使用IoU loss等等;
- 另外还有Decoupled head、Multi positives、SimOTA等等;
- 经过改进后的YOLOX,轻量级的模型YOLOX-Tiny和YOLOX-Nano性能更好,大模型YOLOX-L也取得的SOTA。
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
本章目录
- 1. 简介
- 2. YOLOX
-
- 2.1 YOLOX-DarkNet53
- 2.2 其他backbone
- 3. 与SOTA对比
- 4. 结论
1. 简介
本文中,介绍了对YOLO系列一些有经验的改进方法,提出了一个高性能的检测器——YOLOX。YOLOX采用anchor-free方式,加上其他先进的检测技术,例如decoupled head和标签分配策略SimOTA,取得了非常优异的效果。在轻量级模型方面,YOLOX-Nano仅仅0.91M的参数量,取得了25.3%AP,比NanoDet高1.8%。YOLOX-L和YOLOv4-CSP、YOLOv5-L差不多同样的参数量,取得50.0%AP,高出1.8%AP。
在过去这两年里,目标检测学术界的主要进展主要集中在anchor-free检测器、标签分配策略、end-to-end(NMS-free)检测器上。这些还没有融入到YOLO系列中,YOLOv4和YOLOv5仍然是anchor-based的目标检测器,而且需要手工设计训练规则。这也是为什么提出YOLOX的原因,要把这些进展融入到YOLO系列中。
考虑到YOLOv4和YOLOv5在anchor-based上有点过优化,所以本文采用YOLOv3作为起点(这里默认为YOLOv3-SPP)。
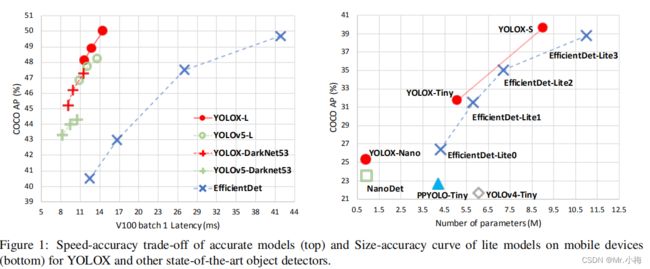
如图1所示,在YOLOv3上修改后得到YOLOX-DarkNet53,得到47.3%AP,高出YOLOv3的44.3%。另外采用先进的CSPNetbackbone和额外的PAN head,YOLOX-L在COCO上以640×640的分辨率在COCO上达到50.0%的AP,比对应的YOLOv5-L高出1.8%。YOLOX-Tiny和YOLOX-Nano(仅0.91M参数和1.08G FLOPs)分别比对应的YOLOv4-Tiny和NanoDet3高出10%和1.8%。
2. YOLOX
2.1 YOLOX-DarkNet53
本文选择YOLOv3的DarkNet53作为的baseline。在本节中,将逐步介绍YOLOX中的整个系统的设计。
实施细节
YOLOv3 baseline
- baseline使用DarkNet53作为backbone,并使用SPP层,也就是YOLOv3-SPP
- 增加EMA权重更新
- cosine学习率策略
- IoU loss和IoU-aware 分支
- 训练时cls和obj分支使用BCE loss,reg分支使用IoU loss
- RandomHorizontalFlip(随机水平翻转)、ColorJitter(颜色抖动)和多尺度等数据增强
- 放弃使用RandomResizedCrop(随机裁剪)策略,因为发现它与mosaic增强有点重叠
Decoupled head
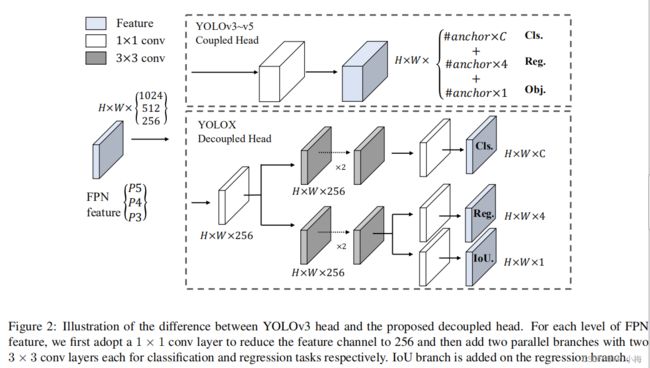
在目标检测任务中,分类和检测分支的冲突问题众所周知,因此decoupled head(解耦头)提出后就被广泛应用。但是,YOLO系列的backbone和特征金字塔(例如,FPN/PAN),在不断演化时,它们的检测头仍保持耦合,如图2所示。
本文通过两个分析实验表明,耦合检测头可能会损害其性能:
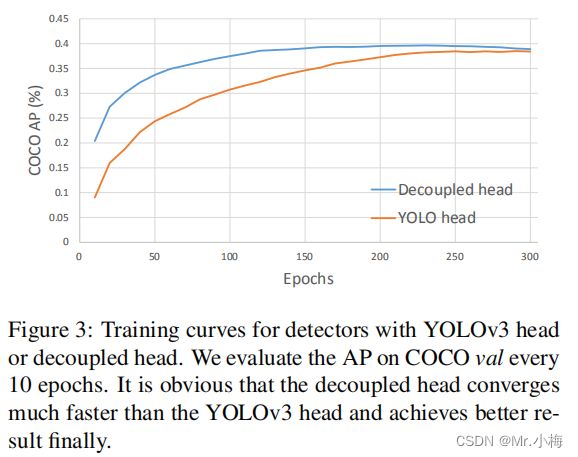
- 用解耦的头代替YOLO的头,大大提高了收敛速度,如图3所示;
- 解耦的头对于YOLO的端到端版本至关重要(下面将进行描述)。
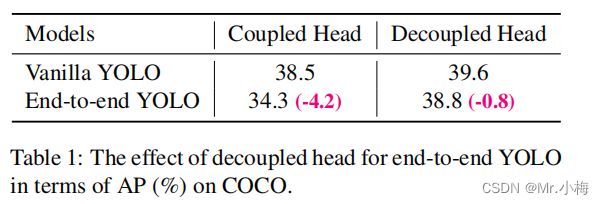
可以从表1中看出,耦合头的端到端性能降低了4.2% AP,而解耦头的端到端性能降低到0.8% AP。因此,本文将YOLO检测头替换为一个精简的解耦头,如图2所示。具体地说,它包含一个1×1 conv层来减少通道维度,然后是两个平行分支和两个3×3 conv层。
数据增强
添加使用Mosaic和MixUp数据增强方法,训练时在模型最后的15个epoch时关闭,结果如表2所示,实现了42.0%的AP。 在使用了强数据增强后,发现ImageNet的预训练并不再有益,因此,本文从头开始训练下面所有模型。
anchor-free
众所周知anchor-based的方法有一些问题,例如:
- 为了达到最优的检测性能,需要在训练前进行聚类分析,以确定一组最优的anchors,这些聚类anchors是特定于领域的,而且不那么一般化;
- anchor机制增加了检测头的复杂性,以及对每个图像的预测数量,在一些边缘的人工智能系统中,在设备之间移动如此大量的预测(例如,从NPU到CPU)可能会成为总体延迟的潜在瓶颈。
anchor-free机制显著减少了需要启发式调优和涉及的许多技巧(如anchor聚类、Grid Sensitive)的设计参数的数量。为了获得良好的性能,使检测器,特别是其训练和解码阶段,相当简单。
将YOLO切换到anchor-free的方式非常简单。将每个位置的预测从3减少到1,并使它们直接预测四个值,即网格左上角的两个偏移量,以及预测框的高度和宽度。将每个目标的中心位置指定为正样本,并预先定义比例范围,以指定每个对象的FPN级别。这种修改降低了检测器的参数和GFLOPs,使其速度更快,但获得了更好的性能42.9%的AP,如表2所示。

Multi positives
为了符合YOLOv3的分配规则,anchor-free版本为每个目标只选择了一个正样本(中心位置),同时忽略了其他高质量的预测。然而,优化这些高质量的预测也可能会带来有益的梯度更新,这会缓解训练过程中正/负抽样的极端不平衡。本文简单地将中心3×3区域分配为正的,在FCOS中也被称为“中心抽样”。检测器的性能提高到45.0% AP,如表2所示,已经超过了目前的最佳各类-YOLOv3的44.3%AP。
SimOTA
标签分配是近年来目标检测的另一项重要进展。本文研究了OTA,总结了一个高级标签分配的四个关键点:
- loss/quality aware
- center prior
- 每个GT动态的正anchors数(简称为动态top-k)
- global view
OTA满足上述所有四条规则,因此本文选择它作为候选标签分配策略。
具体来说,OTA从全局的角度分析标签分配,并将分配过程制定为一个最优传输Optomal Transport(OT)问题,在当前的分配策略中产生SOTA性能。但是,在实践中,发现通过Sinkhorn-Knopp算法解决OT问题会带来25%的额外训练时间,这对于训练300个epoch来说是相当昂贵的。因此,本文将其简化为动态top-k策略,称为SimOTA,以得到一个近似解。
在这里简要介绍SimOTA,SimOTA首先计算成对匹配度,用每个prediction-gt对的cost或quality表示。例如,在SimOTA中,gt g i g_i gi和prediction p j p_j pj之间的cost计算公式为:
c i j = L i j c l s + λ L i j r e g c_{ij}=L^{cls}_{ij}+\lambda L^{reg}_{ij} cij=Lijcls+λLijreg
其中 λ \lambda λ是平衡系数, L i j c l s 和 L i j r e g L^{cls}_{ij}和L^{reg}_{ij} Lijcls和Lijreg是 g i g_i gi和 p j p_j pj之间类别loss和回归loss。然后对于 g i g_i gi,选择在一个固定的中心区域内cost最小的前k个预测作为其正样本。最后,将这些正预测的相应网格划分为正,其余网格划分为负。注意:k值因不同的GT而不同。
SimOTA不仅减少了训练时间,而且避免了该算法中额外的求解器超参数。如表2所示,SimOTA将检测器从45.0% AP提高到47.3% AP,比SOTA YOLOv3高出3.0% AP,显示了高级分配策略的能力。
End-to-end YOLO
添加了两个额外的conv层,one-to-one的标签分配和梯度停止。这些方法使检测器能够执行端到端方式,但会略微降低性能和推理速度,如表2中所示。因此,本文将它作为一个可选的模块,它不涉及到最终的模型。
2.2 其他backbone
除了DarkNet53之外,还在其他backbone上用不同输入尺寸测试了YOLOX,其中YOLOX与所有相应的算法相比,都一致的有所提升。
YOLOv5中修改的CSPNet
为了得到一个公平的比较,采用了YOLOv5的主干,包括改进的CSPNet、SiLU激活和PAN头。还遵循模型的缩放规则得到YOLOX-S、YOLOX-M、YOLOX-L和YOLOX-X。与表3中的YOLOv5进行了比较,本文的模型得到了∼3.0%的∼1.0%的AP,只有延迟增加(原因来自解耦头)。

Tiny/Nano检测器
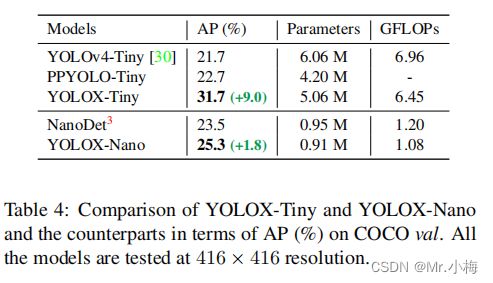
进一步缩小了模型为YOLOX-Tiny,以与YOLOv4-Tiny进行比较。对于移动设备,采用深度卷积来构建一个YOLOX-Nano模型,该模型只有0.91M的参数和1.08G的FLOPs,如表4所示YOLOX在更小的模型尺寸下表现得很好。
模型大小和数据增强
在本文的实验中,所有的模型都保持了几乎相同的学习时间表和优化参数。然而,使用发现合适的增强策略因不同的模型大小而不同。如表5所示,在YOLOX-L中应用MixUp可以提高0.9%,而对于小模型像YOLOX-Nano,削弱这种增强效果更好。具体来说,当训练小模型,即YOLOX-S、YOLOX-Tiny和YOLOX-Nano时,消除了mixuo增强和削弱了mosaic增强(将尺度范围从[0.1,2.0]缩小到[0.5,1.5])。这种修改将YOLOX-Nano的AP从24.0%提高到25.3%。
对于大型模型,实验还发现更强的增强更有帮助。受Copypaste的启发,本文在混合两幅图像之前通过随机采样的比例因子进行抖动。为了理解带有比例抖动的MixUp的能力,将其与YOLOX-L上的Copypaste进行了比较,注意:Copypaste需要额外的实例掩码标注,而MixUp则不需要。结果如表5所示,这两种方法实现了具有竞争力的性能,表明当没有实例掩码标注时,具有比例抖动的MixUp是Copypaste的合格替代品。

3. 与SOTA对比
与SOTA的比较结果如表6所示,但是,这个表中模型的推理速度通常是不受控制的,因为速度随着软件和硬件的不同而变化。因此,对图1中所有YOLO系列使用相同的硬件和代码库,绘制了受控制的速度/精度曲线。

4. 结论
本文介绍了YOLO系列的一些有效的更新,得到了一个名为YOLOX的高性能anchor-free目标检测器。YOLOX配备了一些最新的先进的检测技术,即解耦头,anchor-free,和先进的标签分配策略,YOLOX在所有模型大小的速度和准确性与其他算法之间实现了更好的权衡。值得注意的是,本文将YOLOv3架构在COCO上的准确率提高到了47.3%,比目前的最佳实践高出3.0%。