Hadoop运行模式&完全分布式运行模式
Hadoop运行模式包括:本地模式(计算的数据存在Linux本地,在一台服务器上 自己测试)、伪分布式模式(和集群接轨 HDFS yarn,在一台服务器上执行)、完全分布式模式。
本地模式:(hadoop默认安装后启动就是本地模式,就是将来的数据存在Linux本地,并且运行MR程序的时候也是在本地机器上运行)
伪分布式模式:伪分布式其实就只在一台机器上启动HDFS集群,启动YARN集群,并且数据存在HDFS集群上,以及运行MR程序也是在YARN上运行,计算后的结果也是输出到HDFS上。本质上就是利用一台服务器中多个java进程去模拟多个服务
完全分布式:完全分布式其实就是多台机器上分别启动HDFS集群,启动YARN集群,并且数据存在HDFS集群上的以及运行MR程序也是在YARN上运行,计算后的结果也是输出到HDFS上。
Hadoop官方网站:http://hadoop.apache.org/
本地运行模式(官方wordcount)
1)创建在hadoop-3.1.3文件下面创建一个wcinput文件夹
/opt/module/hadoop-3.1.3
[gyy@hadoop102 hadoop-3.1.3]$ mkdir wcinput #数据输入目录
2)在wcinput文件下创建一个hello.txt文件/传一个
/opt/module/hadoop-3.1.3/wcinput
[gyy@hadoop102 wcinput]$ cat hello.txt
3)回到Hadoop目录/opt/module/hadoop-3.1.3
/opt/module/hadoop-3.1.3 下执行
4)执行程序
[gyy@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput

5)查看结果
[atguigu@hadoop102 hadoop-3.1.3]$ cat wcoutput/part-r-00000

看到如下结果:

完全分布式模式 (重点)
一、准备阶段
1. 准备完全分布式需要的机器
hadoop102 hadoop103 hadoop104
2. 将hadoop102的数据(jdk、hadoop安装目录同步,环境变量文件)同步到 hadoop103 hadoop104
二、学习编写集群分发脚本xsync(scp和rsync)
1.scp(secure copy)安全拷贝:scp可以实现服务器与服务器之间的数据拷贝。(fromserver1to server2)
特点:完全拷贝内容,不做任何比较,如果目的地已有相关内容,它会进行覆盖。
基本语法:
scp -r $pdir/$fname [$user@]hadoop$host:$pdir/$fname #$user@可省,默认当前登录用户
命令 递归 要拷贝的文件路径/名称 [目的用户@]主机:目的路径/名称
# 将hadoop102 上/opt/module 所有目录拷贝到 hadoop103的/opt/module
[gyy@hadoop102 module]$ pwd
/opt/module
[gyy@hadoop102 module]$ scp -r ./* gyy@hadoop103:/opt/module/
#也可以在hadoop104上操作,将hadoop102 上/opt/module下文件 主动拉取到 hadoop104的/opt/module
[gyy@hadoop104 module]$ scp -r gyy@hadoop102:/opt/module/jdk1.8.0_212 ./
#还可以在hadoop103上操作,将hadoop102 上/opt/module下文件 拷贝到 hadoop104的/opt/module
[gyy@hadoop103 module]$ scp -r gyy@hadoop102:/opt/module/hadoop-3.1.3 gyy@hadoop104:/opt/module/
2.rsync远程同步工具:主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去。scp可以同时连接其他两个主机让他俩互相传,但rsync不行。
基本语法:(语法规则基本相同)
rsync -av $pdir/$fname $user@hadoop$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
-a :归档拷贝
-v:显示复制过程
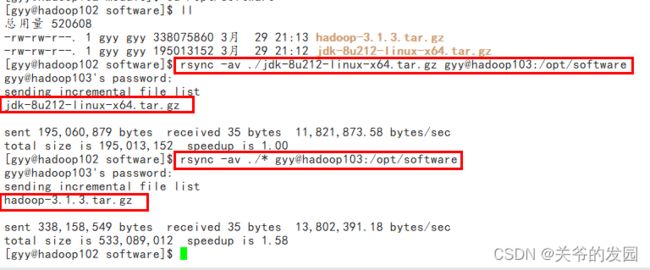
[gyy@hadoop102 module]$ cd /opt/software
[gyy@hadoop102 software]$ ll
总用量 520608
-rw-rw-r--. 1 gyy gyy 338075860 3月 29 21:13 hadoop-3.1.3.tar.gz
-rw-rw-r--. 1 gyy gyy 195013152 3月 29 21:12 jdk-8u212-linux-x64.tar.gz
[gyy@hadoop102 software]$ rsync -av ./jdk-8u212-linux-x64.tar.gz gyy@hadoop103:/opt/software
gyy@hadoop103's password:
sending incremental file list
jdk-8u212-linux-x64.tar.gz#传送jdk
sent 195,060,879 bytes received 35 bytes 11,821,873.58 bytes/sec
total size is 195,013,152 speedup is 1.00
[gyy@hadoop102 software]$ rsync -av ./* gyy@hadoop103:/opt/software
gyy@hadoop103's password:
sending incremental file list
hadoop-3.1.3.tar.gz#补差异,只传了Hadoop,jdk没有再传
sent 338,158,549 bytes received 35 bytes 13,802,391.18 bytes/sec
total size is 533,089,012 speedup is 1.58
[gyy@hadoop102 software]$
rsync不能同时连接两个主机
#rsync也可以实现在目标机上对源机上的文件进行拉取
[gyy@hadoop104 software]$ cd /opt/software
[gyy@hadoop104 software]$ ll
总用量 0
[gyy@hadoop104 software]$ rsync -av gyy@hadoop102:/opt/software/hadoop-3.1.3.tar.gz ./
gyy@hadoop102's password:
receiving incremental file list
hadoop-3.1.3.tar.gz
sent 43 bytes received 338,158,507 bytes 16,495,539.02 bytes/sec
total size is 338,075,860 speedup is 1.00
[gyy@hadoop104 software]$
#但!!!rsync不能同时连接两个其他的主机
[gyy@hadoop103 software]$ rsync -av gyy@hadoop102:/opt/software/jdk-8u212-linux-x64.tar.gz gyy@hadoop104:/opt/software
The source and destination cannot both be remote.
rsync error: syntax or usage error (code 1) at main.c(1275) [Receiver=3.1.2]
[gyy@hadoop103 software]$
![]()
3.编写集群分发的脚本(手动-->自动 提升)
在个人文件夹下创建bin目录
[gyy@hadoop102 hadoop-3.1.3]$ cat /home/gyy/bin/my_rsync.sh
#!/bin/bash
#参数预处理
if [ $# -lt 1 ]
then
echo '参数不能为空'
exit;
fi
#遍历集群中的机器依次分发内容
for host in hadoop103 hadoop104
do
#依次分发内容
for file in $@
do
#判断当前文件是否存在
if [ -e $file ]
then
#存在
#1.获取当前文件的目录结构
pdir=$(cd -P $(dirname $file); pwd)
#$(dirname $file)拿到具体目录结构;防止是软连接用cd -P 来到他的真实目录下,然后再执行pwd获取真实目录
#2.获取当前的文件名
fname=$(basename $file)
#3.登录目标机器,创建统一的目录结构
ssh $host "mkdir -p $pdir"#此处远程登录需要输入依次密码
#4.依次将要分发的目录或文件进行分发
rsync -av $pdir/$fname $host:$pdir#此处发的时候又需要输一次密码
else
#不存在
echo "$file不存在"
fi
done
done
############################
[gyy@hadoop102 hadoop-3.1.3]$ my_rsync.sh /opt/software/jdk-8u212-linux-x64.tar.gz
gyy@hadoop103's password:
Permission denied, please try again.
gyy@hadoop103's password:
gyy@hadoop103's password:
sending incremental file list
sent 76 bytes received 12 bytes 16.00 bytes/sec
total size is 195,013,152 speedup is 2,216,058.55
gyy@hadoop104's password:
gyy@hadoop104's password:
sending incremental file list
jdk-8u212-linux-x64.tar.gz
sent 195,060,879 bytes received 35 bytes 16,961,818.61 bytes/sec
total size is 195,013,152 speedup is 1.00
[gyy@hadoop102 hadoop-3.1.3]$

把环境配置分别分发给103和104直接用scp命令,因为这个文件的权限是root不然会报权限不够的错
[gyy@hadoop102 profile.d]$ scp -r ./my_env.sh root@hadoop103:/etc/profile.d
root@hadoop103's password:
my_env.sh 100% 436 235.3KB/s 00:00
[gyy@hadoop102 profile.d]$ scp -r ./my_env.sh root@hadoop104:/etc/profile.d
root@hadoop104's password:
my_env.sh 100% 436 407.2KB/s 00:00
[gyy@hadoop102 profile.d]$
##################################
[gyy@hadoop103 software]$ hadoop version
-bash: hadoop: 未找到命令
[gyy@hadoop103 software]$ source /etc/profile
[gyy@hadoop103 software]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[gyy@hadoop103 software]$
########################################
[gyy@hadoop104 software]$ source /etc/profile
[gyy@hadoop104 software]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[gyy@hadoop104 software]$
4.规划hadoop集群
注意:NameNode和SecondaryNameNode不要安装在同一台服务器
注意:ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
hadoop102 NameNode(HDFS) DataNode(HDFS) NodeManager(YARN)
hadoop103 ResourceManager(YARN) DataNode(HDFS) NodeManager(YARN)
hadoop104 SecondaryNameNode(HDFS) DataNode(HDFS) NodeManager(YARN)
5.搭建集群 熟悉Hadoop的配置文件
Hadoop中加载配置文件的顺序:当Hadoop集群启动之后,会先加载默认配置,然后再加载自定义配置文件,自定义的配置信息会覆盖默认配置
6. 配置集群的相关信息(修改hadoop自定义的配置文件)
-- hadoop-env.sh (主要映射jdk的环境变量)(可以不配)在Hadoop3.x时候基本不用动了
(1)-- core-site.xml (配置hadoop的全局信息)
(2)-- hdfs-site.xml
(3)-- mapread-site.xml
(4)-- yarn-site.xml
[gyy@hadoop102 etc]$ cd /opt/module/hadoop-3.1.3
[gyy@hadoop102 hadoop-3.1.3]$ ll
总用量 208
drwxr-xr-x. 2 gyy gyy 4096 9月 12 2019 bin
drwxr-xr-x. 3 gyy gyy 4096 9月 12 2019 etc
drwxr-xr-x. 2 gyy gyy 4096 9月 12 2019 include
drwxr-xr-x. 3 gyy gyy 4096 9月 12 2019 lib
drwxr-xr-x. 4 gyy gyy 4096 9月 12 2019 libexec
-rw-rw-r--. 1 gyy gyy 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 gyy gyy 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 gyy gyy 1366 9月 4 2019 README.txt
drwxr-xr-x. 3 gyy gyy 4096 9月 12 2019 sbin
drwxr-xr-x. 3 gyy gyy 4096 3月 30 21:56 share
drwxrwxr-x. 2 gyy gyy 4096 3月 30 21:09 wcinput
drwxr-xr-x. 2 gyy gyy 4096 3月 30 21:18 wcoutput
[gyy@hadoop102 hadoop-3.1.3]$ cd etc/hadoop
[gyy@hadoop102 hadoop]$ ll
-rw-r--r--. 1 gyy gyy 8260 9月 12 2019 capacity-scheduler.xml
-rw-r--r--. 1 gyy gyy 1335 9月 12 2019 configuration.xsl
-rw-r--r--. 1 gyy gyy 1940 9月 12 2019 container-executor.cfg
-rw-r--r--. 1 gyy gyy 774 9月 12 2019 core-site.xml#(配置hadoop的全局信息)
-rw-r--r--. 1 gyy gyy 3999 9月 12 2019 hadoop-env.cmd
-rw-r--r--. 1 gyy gyy 15903 9月 12 2019 hadoop-env.sh
-rw-r--r--. 1 gyy gyy 3323 9月 12 2019 hadoop-metrics2.properties
-rw-r--r--. 1 gyy gyy 11392 9月 12 2019 hadoop-policy.xml
-rw-r--r--. 1 gyy gyy 3414 9月 12 2019 hadoop-user-functions.sh.example
-rw-r--r--. 1 gyy gyy 775 9月 12 2019 hdfs-site.xml
-rw-r--r--. 1 gyy gyy 1484 9月 12 2019 httpfs-env.sh
-rw-r--r--. 1 gyy gyy 1657 9月 12 2019 httpfs-log4j.properties
-rw-r--r--. 1 gyy gyy 21 9月 12 2019 httpfs-signature.secret
-rw-r--r--. 1 gyy gyy 620 9月 12 2019 httpfs-site.xml
-rw-r--r--. 1 gyy gyy 3518 9月 12 2019 kms-acls.xml
-rw-r--r--. 1 gyy gyy 1351 9月 12 2019 kms-env.sh
-rw-r--r--. 1 gyy gyy 1747 9月 12 2019 kms-log4j.properties
-rw-r--r--. 1 gyy gyy 682 9月 12 2019 kms-site.xml
-rw-r--r--. 1 gyy gyy 13326 9月 12 2019 log4j.properties
-rw-r--r--. 1 gyy gyy 951 9月 12 2019 mapred-env.cmd
-rw-r--r--. 1 gyy gyy 1764 9月 12 2019 mapred-env.sh
-rw-r--r--. 1 gyy gyy 4113 9月 12 2019 mapred-queues.xml.template
-rw-r--r--. 1 gyy gyy 758 9月 12 2019 mapred-site.xml
drwxr-xr-x. 2 gyy gyy 4096 9月 12 2019 shellprofile.d
-rw-r--r--. 1 gyy gyy 2316 9月 12 2019 ssl-client.xml.example
-rw-r--r--. 1 gyy gyy 2697 9月 12 2019 ssl-server.xml.example
-rw-r--r--. 1 gyy gyy 2642 9月 12 2019 user_ec_policies.xml.template
-rw-r--r--. 1 gyy gyy 10 9月 12 2019 workers
-rw-r--r--. 1 gyy gyy 2250 9月 12 2019 yarn-env.cmd
-rw-r--r--. 1 gyy gyy 6056 9月 12 2019 yarn-env.sh
-rw-r--r--. 1 gyy gyy 2591 9月 12 2019 yarnservice-log4j.properties
-rw-r--r--. 1 gyy gyy 690 9月 12 2019 yarn-site.xml
[gyy@hadoop102 hadoop]$
(1)配置core-site.xml文件(指定NN地址、HDFS数据存储目录、静态用户...)
vim core-site.xml文件,在
fs.defaultFS
hdfs://hadoop102:9820 #hdfs:协议,Hadoop102:地址;9820:内部通讯使用的端口号
hadoop.tmp.dir
/opt/module/hadoop-3.1.3/data
hadoop.http.staticuser.user
gyy
hadoop.proxyuser.atguigu.hosts
*
hadoop.proxyuser.atguigu.groups
*
hadoop.proxyuser.atguigu.groups
*
###################################################
#没配置之前的core-site.xml文件
fs.defaultFS
file:///
The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.


在没配置之前访问的是默认的本地,配置之后访问的hdfs协议访问hdfs,ip地址:Hadoop102,端口号:9820
(2)配置hdfs-site.xml文件(HDFS的NN和2NN的web端地址)
[gyy@hadoop102 hadoop]$ vim hdfs-site.xml
#在
dfs.namenode.http-address
hadoop102:9870
dfs.namenode.secondary.http-address
hadoop104:9868
(3)配置yarn-site.xml文件(指定MR走shuffle、指定RM地址、最大内存...)
[gyy@hadoop102 hadoop]$ vim yarn-site.xml
#在
#重新洗
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname #指定在哪个服务器启动RM
hadoop103
#yarn工作的时候需要的环境变量,这么配就行
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
#如果不配置最小就是1024,最大8G
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
4096
yarn.nodemanager.resource.memory-mb
4096
yarn.nodemanager.pmem-check-enabled
false
yarn.nodemanager.vmem-check-enabled
false
(4)配置mapred-site.xml文件(配置指定MR运行在yarn上)
[gyy@hadoop102 hadoop]$ vim mapred-site.xml
#在
mapreduce.framework.name
yarn #默认值是local本地
7. 把配置信息行进分发
my_rsync.sh /opt/module/hadoop-3.1.3/etc/hadoop/
hadoop102的配置配完了,直接用分发脚本把配置分发到Hadoop103和104上
[gyy@hadoop102 hadoop-3.1.3]$ my_rsync.sh etc/hadoop/
gyy@hadoop103's password:
gyy@hadoop103's password:
sending incremental file list
hadoop/
hadoop/configuration.xsl
hadoop/container-executor.cfg
hadoop/core-site.xml
hadoop/hadoop-env.cmd
hadoop/hadoop-env.sh
hadoop/hadoop-metrics2.properties
hadoop/hadoop-policy.xml
hadoop/hadoop-user-functions.sh.example
hadoop/hdfs-site.xml
hadoop/httpfs-env.sh
hadoop/httpfs-log4j.properties
hadoop/httpfs-signature.secret
hadoop/httpfs-site.xml
hadoop/kms-acls.xml
hadoop/kms-env.sh
hadoop/kms-log4j.properties
hadoop/kms-site.xml
hadoop/log4j.properties
hadoop/mapred-env.cmd
hadoop/mapred-env.sh
hadoop/mapred-queues.xml.template
hadoop/mapred-site.xml
hadoop/ssl-client.xml.example
hadoop/ssl-server.xml.example
hadoop/user_ec_policies.xml.template
hadoop/workers
hadoop/yarn-env.cmd
hadoop/yarn-env.sh
hadoop/yarn-site.xml
hadoop/yarnservice-log4j.properties
hadoop/shellprofile.d/
hadoop/shellprofile.d/example.sh
sent 6,056 bytes received 1,547 bytes 1,689.56 bytes/sec
total size is 108,561 speedup is 14.28
gyy@hadoop104's password:
gyy@hadoop104's password:
sending incremental file list
hadoop/
hadoop/capacity-scheduler.xml
hadoop/configuration.xsl
hadoop/container-executor.cfg
hadoop/core-site.xml
hadoop/hadoop-env.cmd
hadoop/hadoop-env.sh
hadoop/hadoop-metrics2.properties
hadoop/hadoop-policy.xml
hadoop/hadoop-user-functions.sh.example
hadoop/hdfs-site.xml
hadoop/httpfs-env.sh
hadoop/httpfs-log4j.properties
hadoop/httpfs-signature.secret
hadoop/httpfs-site.xml
hadoop/kms-acls.xml
hadoop/kms-env.sh
hadoop/kms-log4j.properties
hadoop/kms-site.xml
hadoop/log4j.properties
hadoop/mapred-env.cmd
hadoop/mapred-env.sh
hadoop/mapred-queues.xml.template
hadoop/mapred-site.xml
hadoop/ssl-client.xml.example
hadoop/ssl-server.xml.example
hadoop/user_ec_policies.xml.template
hadoop/workers
hadoop/yarn-env.cmd
hadoop/yarn-env.sh
hadoop/yarn-site.xml
hadoop/yarnservice-log4j.properties
hadoop/shellprofile.d/
hadoop/shellprofile.d/example.sh
sent 6,143 bytes received 1,638 bytes 1,729.11 bytes/sec
total size is 108,561 speedup is 13.95
[gyy@hadoop102 hadoop-3.1.3]$
#####################
#在Hadoop103上检测一下
[gyy@hadoop103 software]$ cd /opt/module/hadoop-3.1.3/etc/hadoop
[gyy@hadoop103 hadoop]$ cat core-site.xml
#查看里面的配置是不是都是写好的
8.单点 启动/停止 集群
(1)启动HDFS集群
首次启动HDFS需要对NameNode进行格式化操作在hadoop102执行:
hdfs namenode -format
注意 -- 集群只有首次搭建后需要对NameNode进行格式化操作
-- 如果集群在后期使用过程需要重新格式化,一定切记删除所有机器hadoop安装目录下的 data logs 目录。

回到/opt/module/hadoop-3.1.3
-- hadoop102启动namenode
hdfs --daemon start namenode

http://hadoop102:9870(hdfs-site.xml文件配置访问nn的web界面)


-- hadoop102 hadoop103 hadoop104 分别启动 datanode
hdfs --daemon start datanode




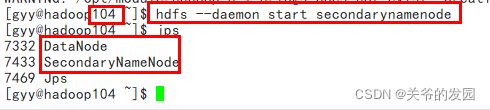
-- hadoop104 启动secondarynamenode
hdfs --daemon start secondarynamenode
(2)启动YARN集群
-- hadoop103启动resourcemanager
yarn --daemon start resourcemanager
-- hadoop102 hadoop103 hadoop104 分别启动 nodemanager
yarn --daemon start nodemanager

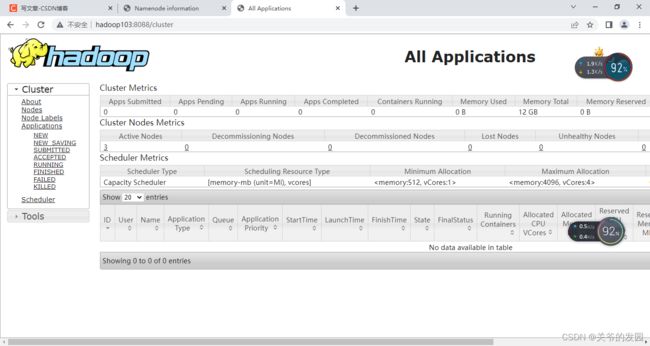
访yarnWeb端http://hadoop103:8088
(3)停止HDFS集群
-- hadoop102停止namenode
hdfs --daemon stop namenode
-- hadoop102 hadoop103 hadoop104 分别停止 datanode
hdfs --daemon stop datanode
-- hadoop104 停止secondarynamenode
hdfs --daemon stop secondarynamenode
(4)停止YARN集群
-- hadoop103停止resourcemanager
yarn --daemon stop resourcemanager
-- hadoop102 hadoop103 hadoop104 分别停止 nodemanager
yarn --daemon stop nodemanager
9.SSH免密登录
免密登录的原理:

准备工作:
(1)在hadoop102上生成密钥对
ssh-keygen -t rsa (敲4次回车,rsa加密算法非对称算法)
(2)在hadoop102上给 hadoop102 hadoop103 hadoop104进行授权(拷公钥)
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104


(3)在hadoop103/104上生成密钥对(与上面102配置相同)
ssh-keygen -t rsa (敲4次回车)
(4)在hadoop103/104上给 hadoop102 hadoop103 hadoop104进行授权(拷公钥)
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
(5)修改 hadoop安装目录下 etc/hadoop/workers 文件
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
原因:当执行群启/群停脚本的时候,首先会解析etc/hadoop/workers,解析到的内容都是每一台机器的地址,脚本会自动执行在每一台机器上启动 dn nm 。

(6)分发my_rsync.sh /opt/module/hadoop-3.1.3/etc/hadoop/workers

(7) 利用hadoop提供的 群启/群停 脚本完成集群操作
群启: start-dfs.sh start-yarn.sh
群停: stop-dfs.sh stop-yarn.sh
注意:启动hdfs的时候要在NameNode所在的机器执行脚本
启动yarn的时候要在resourcemanager所在的机器执行脚本
(8)自定义封装一些操作集群的脚本
vim /home/gyy/bin/my_cluster.sh
#!/bin/bash
#参数校验
if [ $# -lt 1 ]
then
echo "参数不能为空!!!"
exit
fi
#根据参数的值进行 启停 操作
case $1 in
"start")
#启动操作
echo "===============start HDFS================="
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/start-dfs.sh
echo "===============start YARN================="
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/start-yarn.sh
;;
"stop")
#停止操作
echo "===============stop HDFS================="
ssh hadoop102 /opt/module/hadoop-3.1.3/sbin/stop-dfs.sh
echo "===============stop YARN================="
ssh hadoop103 /opt/module/hadoop-3.1.3/sbin/stop-yarn.sh
;;
*)
echo "ERROR!!!!"
;;
esac
10.测试集群 (官方的wordcount案例在集群上跑一遍)
(1)启动集群
在/opt/module/hadoop-3.1.3/路径下执行my_cluster.sh start
(2)查看web端界面http://hadoop102:9870

↑分布式连接系统,是nn所维护的元数据信息
(3)创建文件夹
配置core-site.xml文件时,配置了hdfs网页登录使用的静态用户gyy,如果没配置这个变量的话,在网页上创建不出来文件夹的。
hadoop.http.staticuser.user
gyy

(4)上传入力文件(把本地文件上传到hdfs上)

(5)在102上跑程序
#1在服务器上敲的命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput #输出结果文件夹每次都要不一样,或者删掉同名的
#2使用本地模式的时候还没改配置文件,没改就用文件默认值,这时候的/相当于file:///就是本地
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount file:///wcinput file:///wcoutput
#3配置核心文件core-site.xml之后,这里的/相当于hdfs://hadoop102:9820,就是hdfs的地址
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount hdfs://hadoop102:9820/wcinput hdfs://hadoop102:9820/wcoutput
####像1那样省略也可以,像23那样写全了也可以,不加它自动加
#就是配置文件决定的
更改的核心配置文件
fs.defaultFS
hdfs://hadoop102:9820 #hdfs:协议,Hadoop102:地址;9820:内部通讯使用的端口号
在yarn web端查看

在hdfsweb端查看



11.配置历史服务器(历史服务器是针对MR程序执行的历史记录)
(1)修改 mapred-site.xml 文件并分发给103,104
修改:在/opt/module/hadoop-3.1.3路径下vim etc/hadoop/mapred-site.xml
分发:在/opt/module/hadoop-3.1.3路径下my_rsync.sh etc/hadoop/mapred-site.xml

(2)启动历史服务器(部署在102上了就在102上启动)
mapred --daemon start historyserver
(3)启动hdfs(需要启动hdfs不然web端报错无法访问,hdfs存取数据用的,也会把历史数据存放在hdfs上)
start-dfs.sh

(4)访问历史服务器
http://hadoop102:19888

12.日志聚集功能
日志是针对 MR 程序运行是所产生的的日志
(1)正常可以根据yarn查看目录(不友好)
/opt/module/hadoop-3.1.3/logs

日志聚集功能可以把(1)的日志加工成web端界面,画面和操作友好
(2)打开历史服务器
http://hadoop102:19888


(3)开启日志聚集功能-->修改yarn-site.xml配置文件
yarn.log-aggregation-enable
true
yarn.log.server.url
http://hadoop102:19888/jobhistory/logs
yarn.log-aggregation.retain-seconds
604800
(4)在Hadoop102上修改完,分发给103和104
在/opt/module/hadoop-3.1.3路径下my_rsync.sh etc/hadoop/yarn-site.xml
(5)重启集群和历史服务器
在/opt/module/hadoop-3.1.3路径下:my_cluster.sh stop
在/opt/module/hadoop-3.1.3路径下:my_cluster.sh start
在/opt/module/hadoop-3.1.3路径下:mapred --daemon stop historyserver
在/opt/module/hadoop-3.1.3路径下:mapred --daemon start historyserver
(6)刷新历史服务器,查看日志聚集是否被打开
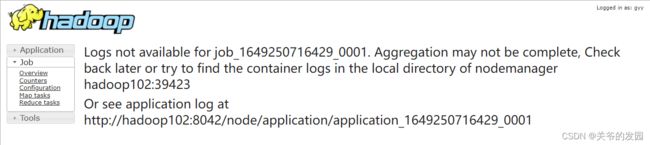
如上图说明日记聚集功能被打开了,但由于跑程序的时候并没有开,所以并不会有之前的记录
(7) 再跑一个程序,查看日志
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput1



详细log点开↑。【info】正常【warning】警告【error】报错
13.配置Hadoop集群的时间服务器集群时间(了解)
把集群时间统一一下,不然定时任务可能有问题
如果服务器能连接外网,那不需要时间同步;如果连不了外网,需要时间同步(少)。
1)时间服务器配置(必须root用户)
(0)查看所有节点ntpd服务状态和开机自启动状态(ntpd时间同步的服务)
[gyy@hadoop102 hadoop-3.1.3]$ sudo systemctl status ntpd
● ntpd.service - Network Time Service
Loaded: loaded (/usr/lib/systemd/system/ntpd.service; disabled; vendor preset: disabled)
Active: inactive (dead)
[gyy@hadoop102 hadoop-3.1.3]$ sudo systemctl is-enabled ntpd
disabled
[gyy@hadoop102 hadoop-3.1.3]$
(1)在所有节点关闭ntpd服务和自启动(上一步检查过了都没开,可以跳过此步)
[atguigu@hadoop102 ~]$ sudo systemctl stop ntpd
[atguigu@hadoop102 ~]$ sudo systemctl disable ntpd
(2)修改hadoop102的ntp.conf配置文件(要将hadoop102作为时间服务器)
[atguigu@hadoop102 ~]$ sudo vim /etc/ntp.conf
修改内容如下:(把a的注释打开,把b注释掉)
a)修改1(授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间)
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
为restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
b)修改2(集群在局域网中,不使用其他互联网上的时间)
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
为
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
c)添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
server 127.127.1.0
fudge 127.127.1.0 stratum 10
(3)修改hadoop102的/etc/sysconfig/ntpd 文件
[atguigu@hadoop102 ~]$ sudo vim /etc/sysconfig/ntpd
增加内容如下(让硬件时间与系统时间一起同步)
SYNC_HWCLOCK=yes
(4)重新启动ntpd服务
[atguigu@hadoop102 ~]$ sudo systemctl start ntpd
(5)设置ntpd服务开机启动
[atguigu@hadoop102 ~]$ sudo systemctlenable ntpd
2)其他机器配置(必须root用户)
(1)在其他机器配置10分钟与时间服务器同步一次
[atguigu@hadoop103 ~]$ sudocrontab -e
编写定时任务如下:
*/10 * * * * /usr/sbin/ntpdate hadoop102
(2)修改任意机器时间
[atguigu@hadoop103 ~]$sudo date -s "2017-9-11 11:11:11"
(3)十分钟后查看机器是否与时间服务器同步
[atguigu@hadoop103 ~]$sudo date
说明:测试的时候可以将10分钟调整为1分钟,节省时间。