数据挖掘实验(六)Matlab实现Apriori算法【关联规则挖掘】
本文代码均已在 MATLAB R2019b 测试通过,如有错误,欢迎指正。
文章目录
-
- (一)关联规则挖掘
- (二)Apriori关联规则挖掘算法的基本思想
- (三)问题描述
- (四)Matlab实现Apriori挖掘算法,提取关联规则
- (五)运行结果
(一)关联规则挖掘
关联规则挖掘(Association rule mining)是数据挖掘中最活跃的研究方法之一,可以用来发现不同事物之间的联系,最早是为了发现超市交易数据库中不同的商品之间的关系。
例如一个超市的经理想要更多的了解顾客的购物习惯,比如“哪组商品可能会在一次购物中同时被购买?”或者“某顾客购买了个人电脑,那该顾客三个月后购买数码相机的概率有多大?”。利用关联规则挖掘,他可能会发现在面包和牛奶间存在较强的关联性,顾客在购买面包的同时大都会同时购买牛奶。这样的关联规则对超市进行促销销售是很有帮助的,如:如果需要对面包进行促销,可通过将其与牛奶捆绑销售的方式来进行,从而提高二者共同的销量。
- 支持度(support): 支持度是模式为真的任务相关的元组(或事务)所占的百分比。对于形如“A⇒B”的关联规则,支持度定义为:
支 持 度 ( A ⇒ B ) = 包 含 A 和 B 的 元 组 数 元 组 总 数 支持度(A⇒B)= \frac {包含A和B的元组数}{元组总数} 支持度(A⇒B)=元组总数包含A和B的元组数,其中A、B是项目的集合。 - 置信度(certainty): 每个发现的模式都有一个表示其有效性或值得信赖性的度量。对于形如“A⇒B”的关联规则,其有效性度量为置信度,定义为:
置 信 度 ( A ⇒ B ) = 包 含 A 和 B 的 元 组 数 包 含 A 的 元 组 数 置信度(A⇒B)= \frac {包含A和B的元组数}{包含A的元组数} 置信度(A⇒B)=包含A的元组数包含A和B的元组数,其中A、B是项目的集合。 - 强关联规则(合格的关联规则): 同时满足用户定义的最小置信度和最小支持度阈值的关联规则,称为强关联规则(strong association rule),并被认为是有趣的。
(二)Apriori关联规则挖掘算法的基本思想
Apriori算法的主要思想是找出存在于事务数据集中最大的频繁项集,利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则。
(1)Apriori 算法原理
- 任何一个频繁项集的子集必定是频繁项集。
- 任何一个非频繁项集的超集必定是非频繁项集。
(2)Apriori算法实现的两个过程
a)找出所有的频繁项集(支持度必须大于等于给定的最小支持度阈值),在这个过程中连接步和剪枝步互相融合,最终得到最大的频繁项集 L k L_k Lk。
连接步: 连接步的目的是找到K项集。
对给定的最小支持度阈值,分别对候选1项集 C 1 C_1 C1,剔除小于该阈值的项集得到频繁1项集 L 1 L_1 L1;
下一步由 L 1 L_1 L1自身连接( L 1 ∗ L 1 L_1*L_1 L1∗L1)产生候选2项集 C 2 C_2 C2,保留 C 2 C_2 C2中满足约束条件的项集得到频繁2项集,记为 L 2 L_2 L2;
再下一步由 L 2 L_2 L2自身连接( L 2 ∗ L 2 L_2*L_2 L2∗L2)产生候选3项集 C 3 C_3 C3,保留 C 3 C_3 C3中满足约束条件的项集得到频繁3项集,记为 L 3 L_3 L3,等等。
这样循环下去,得到最大频繁项集 L k L_k Lk。
剪枝步: 剪枝步紧接着连接步,在产生候选k项集 C k C_k Ck的过程中起到减小搜索空间的目的。由于 C k C_k Ck是 L k − 1 L_{k-1} Lk−1与 L k − 1 L_{k-1} Lk−1连接产生的,根据Apriori的性质,频繁项集的所有非空子集也必须是频繁项集,所以不满足该性质的项集将不会存在于 C k C_k Ck中,该过程就是剪枝。
b)由频繁项集产生强关联规则:在过程a)可知未超过预定的最小支持度阈值的项集已被剔除,如果剩下这些规则又满足了预定的最小置信度阈值,那么就挖掘出了强关联规则。

(三)问题描述
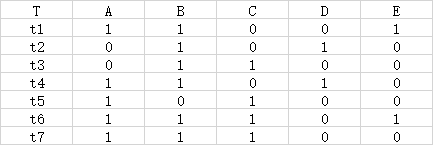
下表给出了某超市的交易记录。该记录中共包含7次交易,7次交易共涉及5种不同的商品。如果某次交易过程中购买了某商品,则在该次交易中,商品的取值为1,否则为0。要求利用Apriori算法,从该交易记录中发掘关联规则。
(四)Matlab实现Apriori挖掘算法,提取关联规则
代码需要说明的地方:
- 支持度(A⇒B)=sum(AB)/n,应该是一个小数,但是由于总元组个数n相同,用分子sum(AB)这个整数来表示支持度。
- 代码中没有写剪枝步,剪枝步是要对每次生成的候选集 C k C_k Ck的所有非空子集判断是否为频繁项集(大于等于最小支持度),而每次求所有子集的时间复杂度是指数级别的,比较大。我写的代码是直接求 C k C_k Ck的置信度,然后选出大于等于最小置信度的 C k C_k Ck作为 L k L_k Lk。
- 数据集写在代码里了,保证你复制粘贴就能运行(Matlab R2019b版本)。 但是对于工程来说,应该用文件形式输入数据,分多个代码文件写函数模块比较好。
clear; clc;
data=[
1 1 0 0 1
0 1 0 1 0
0 1 1 0 0
1 1 0 1 0
1 0 1 0 0
1 1 1 0 1
1 1 1 0 0
];
min_sup=input("请输入最小支持度(正整数,示例:2)\n"); % 最小支持度(未除以n)
min_con=input("请输入最小置信度([0,1]的小数,示例:0.75)\n"); % 最小置信度(已除以n)
[n,m]=size(data);
for i=1:n
x{i}=find(data(i,:)==1); % 求每行购买商品的编号
end
k=0;
while 1
k=k+1;
L{k}={};
%% 生成候选集C{k}
if k==1
C{k}=(1:m)';
else
[nL,mL]=size(L{k-1});
cnt=0;
for i=1:nL
for j=i+1:nL
tmp=union(L{k-1}(i,:),L{k-1}(j,:)); % 两集合并集
if length(tmp)==k
cnt=cnt+1;
C{k}(cnt,1:k)=tmp;
end
end
end
C{k}=unique(C{k},'rows'); % 去掉重复的行
end
%% 求候选集的支持度C_sup{k}
[nC,mC]=size(C{k}); % 候选集大小
for i=1:nC
cnt=0;
for j=1:n
if all(ismember(C{k}(i,:),x{j}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt=cnt+1;
end
end
C_sup{k}(i,1)=cnt; % 每行存候选集对应的支持度
end
%% 求频繁项集L{k}
L{k}=C{k}(C_sup{k}>=min_sup,:);
if isempty(L{k}) % 这次没有找出频繁项集
break;
end
if size(L{k},1)==1 % 频繁项集行数为1,下一次无法生成候选集,直接结束
k=k+1;
C{k}={};
L{k}={};
break
end
end
fprintf("\n");
for i=1:k
fprintf("第%d轮的候选集为:",i); C{i}
fprintf("第%d轮的频繁集为:",i); L{i}
end
fprintf("第%d轮结束,最大频繁项集为:",k); L{k-1}
[nL,mL]=size(L{k-1});
rule_count=0;
for p=1:nL % 第p个频繁集
L_last=L{k-1}(p,:); % 之后将L_last分成左右两个部分,表示规则的前件和后件
%% 求ab一起出现的次数cnt_ab
cnt_ab=0;
for i=1:n
if all(ismember(L_last,x{i}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt_ab=cnt_ab+1;
end
end
len=floor(length(L_last)/2);
for i=1:len
s=nchoosek(L_last,i); % 选i个数的所有组合
[ns,ms]=size(s);
for j=1:ns
a=s(j,:);
b=setdiff(L_last,a);
[na,ma]=size(a);
[nb,mb]=size(b);
%% 关联规则a->b
cnt_a=0;
for i=1:na
for j=1:n
if all(ismember(a,x{j}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt_a=cnt_a+1;
end
end
end
pab=cnt_ab/cnt_a;
if pab>=min_con % 关联规则a->b的置信度大于等于最小置信度,是强关联规则
rule_count=rule_count+1;
rule(rule_count,1:ma)=a;
rule(rule_count,ma+1:ma+mb)=b;
rule(rule_count,ma+mb+1)=ma; % 倒数第二列记录分割位置(分成规则的前件、后件)
rule(rule_count,ma+mb+2)=pab; % 倒数第一列记录置信度
end
%% 关联规则b->a
cnt_b=0;
for i=1:na
for j=1:n
if all(ismember(b,x{j}),2)==1 % all函数判断向量是否全为1,参数2表示按行判断
cnt_b=cnt_b+1;
end
end
end
pba=cnt_ab/cnt_b;
if pba>=min_con % 关联规则b->a的置信度大于等于最小置信度,是强关联规则
rule_count=rule_count+1;
rule(rule_count,1:mb)=b;
rule(rule_count,mb+1:mb+ma)=a;
rule(rule_count,mb+ma+1)=mb; % 倒数第二列记录分割位置(分成规则的前件、后件)
rule(rule_count,mb+ma+2)=pba; % 倒数第一列记录置信度
end
end
end
end
fprintf("当最小支持度为%d,最小置信度为%.2f时,生成的强关联规则:\n",min_sup,min_con);
fprintf("强关联规则\t\t置信度\n");
[nr,mr]=size(rule);
for i=1:nr
pos=rule(i,mr-1); % 断开位置,1:pos为规则前件,pos+1:mr-2为规则后件
for j=1:pos
if j==pos
fprintf("%d",rule(i,j));
else
fprintf("%d∧",rule(i,j));
end
end
fprintf(" => ");
for j=pos+1:mr-2
if j==mr-2
fprintf("%d",rule(i,j));
else
fprintf("%d∧",rule(i,j));
end
end
fprintf("\t\t%f\n",rule(i,mr));
end
(五)运行结果
(1)输入最小支持度为2,最小置信度为0.75
请输入最小支持度(正整数,示例:2)
2
请输入最小置信度([0,1]的小数,示例:0.75)
0.75
第1轮的候选集为:
ans =
1
2
3
4
5
第1轮的频繁集为:
ans =
1
2
3
4
5
第2轮的候选集为:
ans =
1 2
1 3
1 4
1 5
2 3
2 4
2 5
3 4
3 5
4 5
第2轮的频繁集为:
ans =
1 2
1 3
1 5
2 3
2 4
2 5
第3轮的候选集为:
ans =
1 2 3
1 2 4
1 2 5
1 3 5
2 3 4
2 3 5
2 4 5
第3轮的频繁集为:
ans =
1 2 3
1 2 5
第4轮的候选集为:
ans =
1 2 3 5
第4轮的频繁集为:
ans =
空的 0×4 double 矩阵
第4轮结束,最大频繁项集为:
ans =
1 2 3
1 2 5
当最小支持度为2,最小置信度为0.75时,生成的强关联规则:
强关联规则 置信度
2∧5 => 1 1.000000
1∧5 => 2 1.000000
5 => 1∧2 1.000000
(2)输入最小支持度为2,最小置信度为0
请输入最小支持度(正整数,示例:2)
2
请输入最小置信度([0,1]的小数,示例:0.75)
0
第1轮的候选集为:
ans =
1
2
3
4
5
第1轮的频繁集为:
ans =
1
2
3
4
5
第2轮的候选集为:
ans =
1 2
1 3
1 4
1 5
2 3
2 4
2 5
3 4
3 5
4 5
第2轮的频繁集为:
ans =
1 2
1 3
1 5
2 3
2 4
2 5
第3轮的候选集为:
ans =
1 2 3
1 2 4
1 2 5
1 3 5
2 3 4
2 3 5
2 4 5
第3轮的频繁集为:
ans =
1 2 3
1 2 5
第4轮的候选集为:
ans =
1 2 3 5
第4轮的频繁集为:
ans =
空的 0×4 double 矩阵
第4轮结束,最大频繁项集为:
ans =
1 2 3
1 2 5
当最小支持度为2,最小置信度为0.00时,生成的强关联规则:
强关联规则 置信度
1 => 2∧3 0.400000
2∧3 => 1 0.666667
2 => 1∧3 0.333333
1∧3 => 2 0.666667
3 => 1∧2 0.500000
1∧2 => 3 0.500000
1 => 2∧5 0.400000
2∧5 => 1 1.000000
2 => 1∧5 0.333333
1∧5 => 2 1.000000
5 => 1∧2 1.000000
1∧2 => 5 0.500000