使用FastDeploy在英特尔CPU和独立显卡上端到端高效部署AI模型
目录
1.1 产业实践中部署AI模型的痛点
1.1.1 部署模型的典型流程
1.1.2 端到端的AI性能
1.1.3 部署模型的难点和痛点
1.2 FastDeploy简介
1.3 英特尔独立显卡简介
1.4 使用FastDeploy在英特尔CPU和独立显卡上部署模型的步骤
1.4.1 搭建FastDeploy开发环境
1.4.2 下载模型和测试图处
1.4.3 三行代码完成在项特尔CPU上的模型部署
1.4.4 使用RuntimeOption 将AI推理硬伯切换项特尔独立显卡
1.5 总结
作者:王一凡 英特尔物联网创新大使
1.1 产业实践中部署AI模型的痛点
1.1.1 部署模型的典型流程
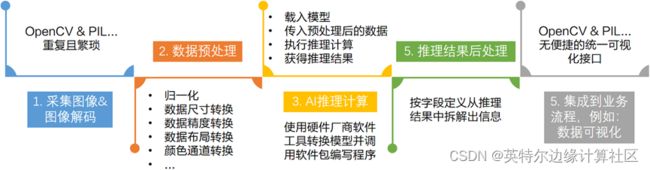
对于来自于千行百业,打算将AI模型集成到自己的主线产品中,解决本行痛点的AI开发者来说,部署AI模型,或者说将AI模型集成到自己产品中去的典型步骤(以计算机视觉应用为例)有:
- 采集图像&图像解码
- 数据预处理
- 执行AI推理计算
- 推理结果后处理
- 将后处理结果集成到业务流程
1.1.2 端到端的AI性能
当AI开发者将AI模型集成到业务流程后,不太关心AI模型在AI推理硬件上单纯的推理速度,而是关心包含图像解码、数据预处理和后处理的端到端的AI性能。

在产业实践中,我们发现不仅AI推理硬件和对应推理引擎(例如:OpenVINO Runtime)对于端到端的性能影响大,数据预处理和后处理代码是否高效对于端到端的性能影响也大。
以CPU上预处理操作融合优化为例,经过优化后的前处理代码,可以使得AI端到端性能得到较大提升。
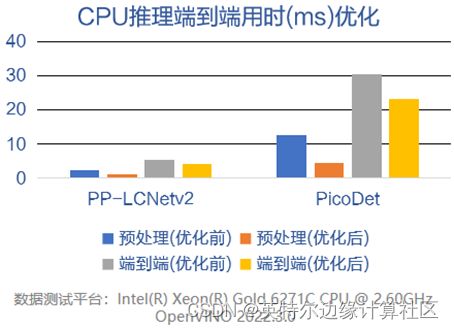
数据来源:感谢FastDeploy团队完成测试并提供数据
结论:优秀且高效的前后处理代码,可以明显提高端到端的AI性能!
1.1.3 部署模型的难点和痛点
在产业实践中,在某个任务上当前最优的SOTA模型的很有可能与部署相关的文档和范例代码不完整,AI开发者需要通过阅读SOTA模型源代码来手动编写模型的前后处理代码,这导致:
- 耗时耗力:阅读SOTA模型源代码来理解模型的前后处理,提高了部署模型的技术门槛。另外,手动编写前后处理代码,也需要更多的测试工作来消除bug。
- 精度隐患:手动或借助网上开源但未经过实践验证过的前后处理代码,会有精度隐患,即当前对于某些图片精度很好,但对于另外的图片精度就下降。笔者就遇到过类似问题,原因在于调用了一个GitHub上下载的NMS()函数,这个函数对代码仓提供的范例模型有效,但对于笔者使用的模型恰恰就出现丢失检测对象的问题。
- 优化困难:解决了精度问题后,下一步就是通过多线程、模型压缩、Batch优化等软件技术进一步提升端到端的AI性能,节约硬件采购成本。这些软件技术对于计算机专业的工程师不算挑战,但对于千行百业中非计算机专业的工程师,却无形中建立起了一道极高的门槛。
为了赋能千行百业的工程师,高效便捷的将AI模型集成到自己的产品中去,急需一个专门面向AI模型部署的软件工具。
1.2 FastDeploy简介
FastDeploy是一款全场景、易用灵活、极致高效的AI推理部署工具。提供开箱即用的云边端部署体验, 支持超过 150+ Text, Vision, Speech和跨模态模型,并实现端到端的推理性能优化。包括图像分类、物体检测、图像分割、人脸检测、人脸识别、关键点检测、抠图、OCR、NLP、TTS等任务,满足开发者多场景、多硬件、多平台的产业部署需求。

FastDeploy项目链接: https://github.com/PaddlePaddle/FastDeploy
1.3 英特尔独立显卡简介
英特尔在2021年的构架日上发布了独立显卡产品路线图,OpenVINO从2022.2版本开始支持AI模型在英特尔独立显卡上做AI推理计算。

当前已经可以购买的消费类独立显卡是英特尔锐炫TM独立显卡A7系列,并已发布在独立显卡上做AI推理计算的范例程序。

1.4 使用FastDeploy在英特尔CPU和独立显卡上部署模型的步骤
1.4.1 搭建FastDeploy开发环境
当前FastDeploy 最新的Release版本是1.0.1,一行命令即可完成FastDeploy的安装:
pip install fastdeploy-python –f https://www.paddlepaddle.org.cn/whl/fastdeploy.html 1.4.2 下载模型和测试图处
FastDeploy支持的PaddleSeg预训练模型下载地址:FastDeploy/examples/vision/segmentation/paddleseg at develop · PaddlePaddle/FastDeploy · GitHub
测试图片下载地址:https://paddleseg.bj.bcebos.com/dygraph/demo/cityscapes_demo.png
使用命令,下载模型和测试图片
图片:
wget https://paddleseg.bj.bcebos.com/dygraph/demo/cityscapes_demo.png
模型:https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/vision/segmentation/paddleseg1.4.3 三行代码完成在项特尔CPU上的模型部署
基于FastDeploy,只需三行代码即可完成在英特尔CPU上的模型部署,并获得经过后处理的推理结果。
import fastdeploy as fd
import cv2
# 读取图片
im = cv2.imread("cityscapes_demo.png")
# 加载飞桨PaddleSeg模型
model = fd.vision.segmentation.PaddleSegModel(“model.pdmodel”, “model.pdiparams”,“deploy.yaml”)
# 预测结果
result = model.predict(im)
print(result)将推理结果print出来,如下图所示,经过FastDeploy完成的AI推理计算,拿到的是经过后处理的结果,可以直接将该结果传给业务处理流程。

1.4.4 使用RuntimeOption 将AI推理硬伯切换项特尔独立显卡
在上述三行代码的基础上,只需要使用RuntimeOption将AI推理硬件切换为英特尔独立显卡,完成代码如下所示:
import fastdeploy as fd
import cv2
# 读取图片
im = cv2.imread("cityscapes_demo.png")
h, w, c = im.shape
# 通过RuntimeOption配置后端
option = fd.RuntimeOption()
option.use_openvino_backend()
option.set_openvino_device("GPU.1")
# 固定模型的输入形状
option.set_openvino_shape_info({"x": [1,c,h,w]})
# 加载飞桨PaddleSeg模型
model = fd.vision.segmentation.PaddleSegModel(“model.pdmodel”, “model.pdiparams”,“deploy.yaml”,
runtime_option=option)
# 预测结果
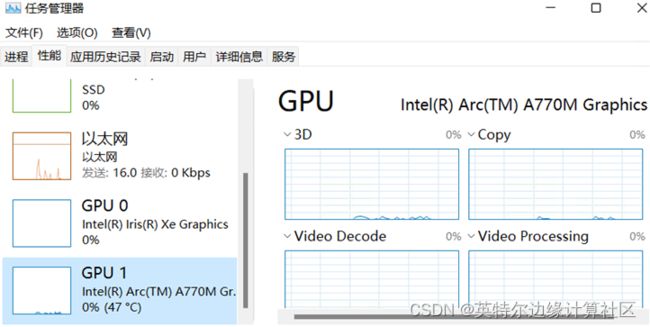
result = model.predict(im)set_openvino_device()中字符串填写“GPU.1”是根据英特尔独立显卡在操作系统的中设备名称,如下图所示:
当前,在英特尔独立显卡上做AI推理,需要注意的问题有:
- 需要固定模型输入节点的形状(Shape)
- 英特尔GPU上支持的算子数量与CPU并不一致,在部署PPYOLE时,如若全采用GPU执行,会出现如下提示
![]()
这是需要将推理硬件设置为异构方式
option.set_openvino_device("HETERO:GPU.1,CPU")到此,使用FastDeploy在英特尔CPU和独立显卡上部署AI模型的工作全部完成。
1.5 总结
面对千行百业中部署AI模型的挑战,FastDeploy工具很好的保证了部署AI模型的精度,以及端到端AI性能问题,也提高了部署端工作的效率。通过RuntimeOption,将FastDeploy的推理后端设置为OpenVINO,可以非常便捷将AI模型部署在英特尔CPU、集成显卡和独立显卡上。
