Python -- HTTP服务器
在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来。而浏览器和服务器之间的传输协议是HTTP,所以:
-
HTML是一种用来定义网页的文本,会HTML,就可以编写网页;
-
HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信。
http协议分析
浏览器请求
我们在地址栏输入 www.baidu.com 时,浏览器将显示新浪的首页。在这个过程中,浏览器都干了哪些事情呢?通过chrome浏览器的Network的记录,我们就可以知道。在Network中,找到www.baidu.com那条记录,点击,右侧将显示Request Headers,点击右侧的view source,我们就可以看到浏览器发给百度服务器的请求:GET / HTTP/1.1
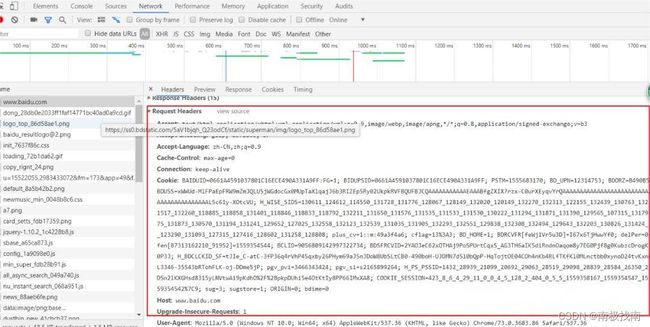
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: BAIDUID=0661A4591037801C16ECE490A331A9FF:FG=1; BIDUPSID=0661A4591037801C16ECE490A331A9FF; PSTM=1555xxxxxxx说明:
首先看第一行:
GET / HTTP/1.1GET 表示一个读取请求,将从服务器获得网页数据,/表示URL的路径,URL总是以/开头,/就表示首页,最后的HTTP/1.1指示采用的HTTP协议版本是1.1。目前HTTP协议的版本就是1.1,但是大部分服务器也支持1.0版本,主要区别在于1.1版本允许多个HTTP请求复用一个TCP连接,以加快传输速度。
从第二行开始。都是一个Xxx: abc这样的键值对
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0表示请求的域名是 www.baidu.com。如果一台服务器有多个网站,服务器就需要通过Host来区分浏览器请求的是哪个网站。
服务器相应
我们打开刚才Network里面的Response Headers 点击右侧的viewparsed,看到如下信息
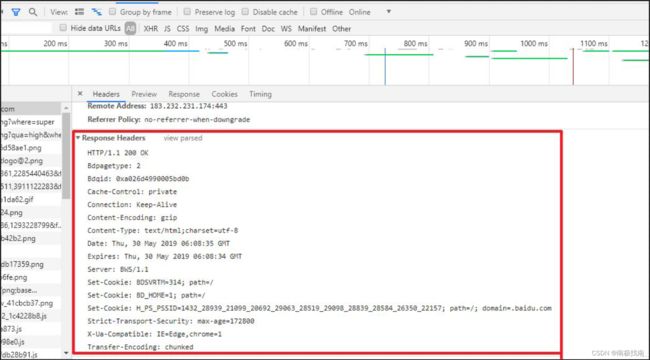
HTTP/1.1 200 OK
Bdpagetype: 2
Bdqid: 0xa026d4990005bd0b
Cache-Control: private
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html;charset=utf-8
Date: Thu, 30 May 2019 06:08:35 GMT
Expires: Thu, 30 May 2019 06:08:34 GMT
Server: BWS/1.1
Set-Cookie: BDSVRTM=314; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=1432_28939_21099_20692_29063_28519_29098_28839_28584_26350_22157; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=172800
X-Ua-Compatible: IE=Edge,chrome=1
Transfer-Encoding: chunkedHTTP响应分为 Header 和 Body 两部分(Body是可选项),我们在Network中看到的Header最重要的几行如下:
HTTP/1.1 200 OK200表示一个成功的响应,后面的OK是说明。
如果返回的不是200,那么往往有其他的功能,例如
失败的响应有404 Not Found:网页不存在
500 Internal Server Error:服务器内部出错
…等等…
Content-Type: text/htmlContent-Type指示响应的内容,这里是text/html表示HTML网页。
请注意,浏览器就是依靠Content-Type来判断响应的内容是网页还是图片,是视频还是音乐。浏览器并不靠 URL来判断响应的内容,所以,即使URL是http://www.baidu.com/meimei.jpg,它也不一定就是图片。
HTTP响应的Body就是HTML源码,我们在菜单栏选择“视图”,“开发者”,“查看网页源码”就可以在浏览器中直接查看HTML源码。
浏览器解析过程描述
当浏览器读取到百度首页的HTML源码后,它会解析HTML,显示页面,然后,根据HTML里面的各种链接,再发送HTTP请求给新浪服务器,拿到相应的图片、视频、Flash、JavaScript脚本、CSS等各种资源,最终显示出一个完整的页面。所以我们在Network下能看到很多额外的HTTP请求。
HTTP格式
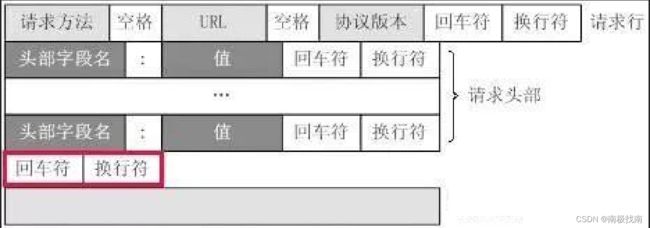
每个HTTP请求和响应都遵循相同的格式,一个HTTP包含Header和Body两部分,其中Body是可选的。
HTTP协议是一种文本协议,所以,它的格式也非常简单。
HTTP GET请求格式
GET /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3每个Header一行一个,换行符是\r\n。
HTTP POST 请求格式
POST /path HTTP/1.1
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...当遇到 连续两个\r\n 时,Header部分结束,后面的数据全部是Body。Header部分和Body中间有一个空行
HTTP 相应格式
200 OK
Header1: Value1
Header2: Value2
Header3: Value3
body data goes here...HTTP响应如果包含body,也是通过 \r\n\r\n (俩个空行) 来分隔的。
Tips: Body的数据类型由Content-Type头来确定,如果是网页,Body就是文本,如果是图片,Body就是图片的二进制数据。
当存在Content-Encoding时,Body数据是被压缩的,最常见的压缩方式是gzip,所以,看到Content-Encoding: gzip时,需要将Body数据先解压缩,才能得到真正的数据。压缩的目的在于减少Body的大小,加快网络传输。