爬虫实践——爬取新闻并生成pdf文档
引言
最近写了一个爬虫项目,爬取了德语新闻网站上特定关键词下的一系列新闻,共计200+文章。并生成简单的pdf。记录一下,方便以后用。
国外的网站需要,但整个爬虫处理流程是相同的,科学上网的问题自行解决
工具
python 3.8
selenium,reportlab
chromeDriver
xpath helper 插件
思路
整体上分3个步骤,1)获取需要爬取的新闻链接列表;2)单个新闻页面爬虫及提取需要的信息;3)生成pdf文档
代码
爬虫基础
爬虫的部分主要是使用selenium。对selenium的了解就只会用,在我看来,selenium爬虫的过程就是会自动打开浏览器,然后通过元素定位,来获取数据或者模拟人的点击。
selenium需要下载chromeDriver 配合使用。安装教程
然后基础过程大致是
from selenium import webdriver
# 打开浏览器
browser = webdriver.Chrome()
# 打开想要的网页的页面
browser.get(url)
#元素定位
#通常说有八大定位方法,我最喜欢的是xpath,因为写起来简单
browser.find_element_by_xpath("xxxxxx") #符合条件的一个,没找到会报错
browser.find_elements_by_xpath("xxxxxx") #符合条件的很多个,返回列表
# 元素获取后的处理
# 点击1
_button.click()
# 点击2
browser.execute_script("arguments[0].click();", _button)
# 文本内容
element.text
# 可以获取元素属性(标签)
element.get_property("tagname")
element.get_attribute("tagname")
# 属性
注: python是解释型语言,读一行执行一行。如果拿不准是否能准确定位,可以在console里面一行一行地写,然后输出试一下。
xpath插件
因为xpath的语法没学过,所以其实看不太懂,但是有辅助神器Xpath helper。安装教程
国内下载地址:https://chrome.zzzmh.cn/info/hgimnogjllphhhkhlmebbmlgjoejdpjl
google player 直接搜索安装也可。
使用示例
鼠标右击点检查,然后点一下检查测边框左上角的小蓝标,进入鼠标定位的模式,鼠标移动到想要定位的元素,找到在源代码中对应的位置

复制得到xpath地址
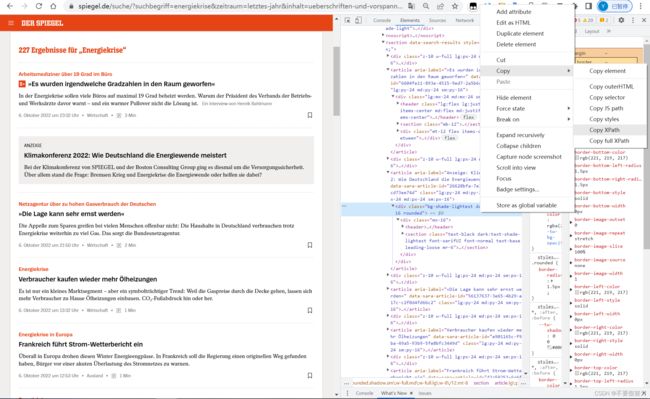
使用插件验证xpath
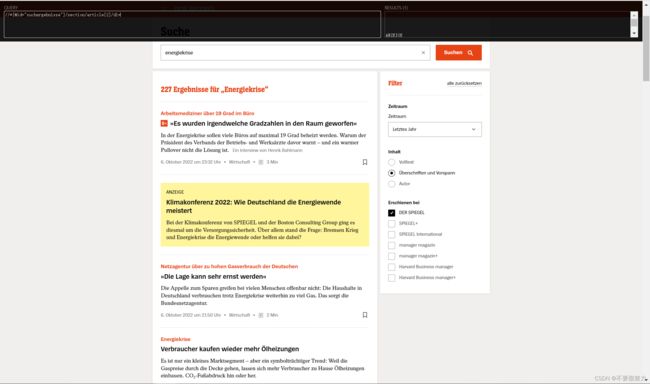
下面正式开始
主要步骤
step1 获取需要爬取的新闻链接列表
目标是某一关键词搜索下的所有结果,观察搜索结果页面,我们需要的是提取新闻链接以及翻页。
翻页有两种思路
都要先要获取总页数,然后是一个循环。
第一种是改网址中的页码参数 放到现在的例子也就是
for i in range(total):
url = "https://www.spiegel.de/suche/?suchbegriff=energiekrise&seite="+i+"&zeitraum=letztes-jahr&inhalt=ueberschriften-und-vorspann&erschienenBei=der-spiegel'
browser.get(url)
......
第二种是模拟点击页面上的翻页按钮
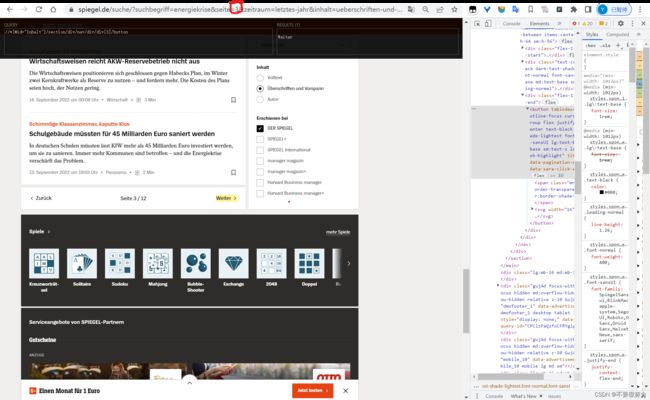
我采用的是第二种模拟点击翻页。
browser.get(start_url)
# 获取总页数
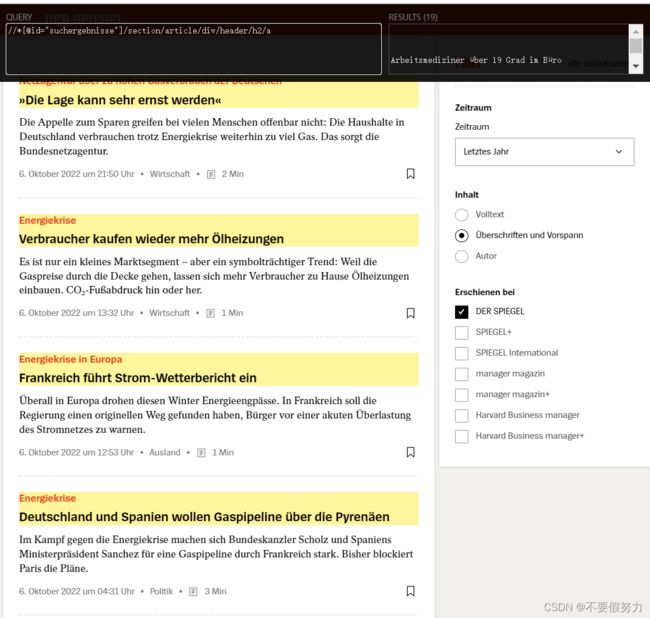
total = browser.find_element_by_xpath('//*[@id="Inhalt"]/section/div/nav/div/div[2]/span[2]')
total = int(total.text)
links = []
next_button_pattern = '//*[@id="Inhalt"]/section/div/nav/div/div[3]/button'
pattern = '//*[@id="suchergebnisse"]/section/article/div/header/h2/a'
while total > 0:
#获取新闻链接列表
content_elements = browser.find_elements_by_xpath(pattern)
links.extend([c.get_attribute('href') for c in content_elements])
if total > 1:
#翻页
next_button = browser.find_element_by_xpath(next_button_pattern)
browser.execute_script("arguments[0].click();", next_button)
time.sleep(3)#有时候翻页之后网页不能很快加载出来,所以留一点儿时间(这个是个人感觉,没有依据,不加的时候确实数据没获取全)
total -= 1
# 把获得的新闻链接列表存下来。
with open("link.txt", "w") as f:
for link in links:
f.write(link+'\n')
step2 获取单篇新闻的主要信息
就是上面说的爬虫的基本东西,直接上代码。
def handle_spiegel(url, _id ):
browser.get(url)
time.sleep(2)
# 获小取标题
little_title_pattern = '//*[@id="Inhalt"]/article/header/div/div/h2/span[1]'
little_title = browser.find_element_by_xpath(little_title_pattern).text
# 获取标题
title_pattern = '//*[@id="Inhalt"]/article/header/div/div/h2/span[2]'
title = browser.find_element_by_xpath(title_pattern).text
# 获取时间
# 这里是后面发现有的文章没有发布时间,所以做了一个异常处理
try:
datetime = browser.find_element_by_xpath('//*[@id="Inhalt"]/article/header/div/div/div/time').get_attribute('datetime')
except common.exceptions.NoSuchElementException as e:
print(e)
datetime = ''
# 获取概述
summary_pattern = '//*[@id="Inhalt"]/article/header/div/div/div[1]'
summary = browser.find_element_by_xpath(summary_pattern).text
# 获取正文
content_pattern = '//*[@id="Inhalt"]/article/div/section[2]/div/div/div'
content_elements = browser.find_elements_by_xpath(content_pattern)
contents = []
for p in content_elements:
if p.text != '':
contents.append(p.text)
# 把获得的信息存下来,这是下一步的工作了
Graphs.save_pdf(little_title, title, summary, datetime, contents, url, str(_id))
step3 输出为pdf
这里使用了reportlab,也是现学的。参考
这里另外建了一个Graph.py 负责处理pdf生成的问题。把方法设置为静态,方便调用。
效果:
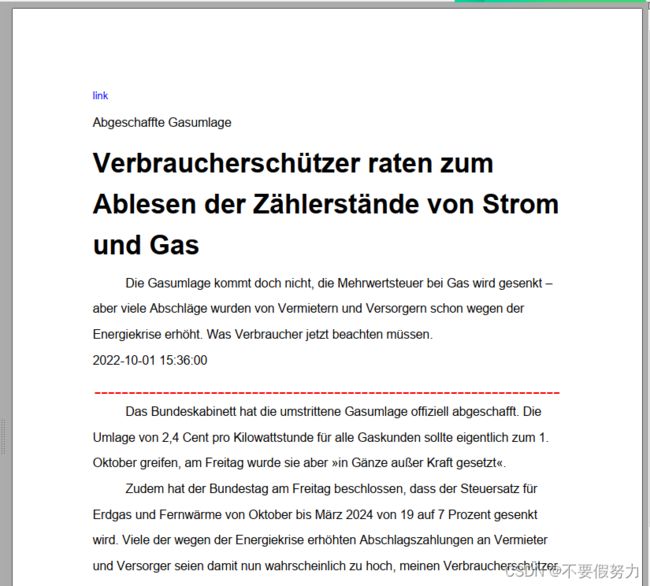
注意:代码比较固定,但我想说的是存哪些信息的问题。除了必要的文本信息,我还存了id,原url。
是因为这个爬虫写的很基础,比较慢,又要,所有很有可能就爬到一半就断了。所以存下来id,放到文件标题里可以很快的看到哪些已经爬过了,哪些没有;另一个好处是可以让文件名减少重复 (最初写的时候,用文章标题做题目,结果因为有同名文件,生成的时候覆盖了另一个,所以在200多个看不懂标题的文件里找了近一个小时才发现问题)。
然后存下来url是文件使用者如果发现文件爬取的结果有哪不对,或者想确认一下原文时就可以很方便。
另一个要注意的点是,有的文章标题带有“?",“:”这样的特殊符号,这些是不能出现在文件名中的,所以做了一些特判。
from reportlab.lib.styles import getSampleStyleSheet # 文本样式
from reportlab.lib import colors # 颜色模块
from reportlab.platypus import SimpleDocTemplate, Paragraph
from reportlab.lib.pagesizes import LETTER
class Graphs:
# 绘制标题
@staticmethod
def draw_title(title: str):
# 获取所有样式表
style = getSampleStyleSheet()
# 拿到标题样式
ct = style['Heading1']
# 单独设置样式相关属性
ct.fontSize = 26 # 字体大小
ct.leading = 40 # 行间距
ct.alignment = 0 # 居中
ct.bold = True
# 创建标题对应的段落,并且返回
return Paragraph(title, ct)
# 绘制小标题
@staticmethod
def draw_little_title(title: str):
# 获取所有样式表
style = getSampleStyleSheet()
# 拿到标题样式
ct = style['Normal']
# 单独设置样式相关属性
ct.fontSize = 12 # 字体大小
ct.leading = 30 # 行间距
# ct.textColor = colors.red # 字体颜色
# 创建标题对应的段落,并且返回
return Paragraph(title, ct)
# 绘制普通段落内容
@staticmethod
def draw_text(text: str):
# 获取所有样式表
style = getSampleStyleSheet()
# 获取普通样式
ct = style['Normal']
ct.fontSize = 12
ct.wordWrap = 'CJK' # 设置自动换行
ct.alignment = 0 # 左对齐
ct.firstLineIndent = 32 # 第一行开头空格
ct.leading = 25
return Paragraph(text, ct)
# 绘制网址链接
@staticmethod
def draw_url(text: str):
# 获取所有样式表
style = getSampleStyleSheet()
# 获取普通样式
ct = style['Normal']
ct.fontSize = 10
ct.alignment = 0 # 左对齐
ct.leading = 25
return Paragraph("link", ct)
# 绘制时间显示
@staticmethod
def draw_time(text: str):
# 获取所有样式表
style = getSampleStyleSheet()
# 获取普通样式
ct = style['Normal']
ct.fontSize = 12
ct.alignment = 0 # 右对齐
ct.leading = 25
return Paragraph(text, ct)
# 绘制分割线
@staticmethod
def draw_line():
# 获取所有样式表
style = getSampleStyleSheet()
# 获取普通样式
ct = style['Normal']
ct.fontSize = 20
ct.alignment = 1 # 居中
ct.leading = 25
ct.textColor = colors.red
return Paragraph('--------------------------------------------------------------------', ct)
# 绘制普通段落内容
@staticmethod
def save_pdf(little_title: str, title: str, summary: str, datetime: str, content: list, url: str, id: str):
to_write = list()
to_write.append(Graphs.draw_url(url+'\n'))
to_write.append(Graphs.draw_little_title(little_title))
to_write.append(Graphs.draw_title(title))
to_write.append(Graphs.draw_text(summary))
to_write.append(Graphs.draw_time(datetime))
to_write.append(Graphs.draw_line())
# 爬取的到的text中,有\n但是直接输入没法换行
for c in content:
tem = c.split("\n")
for p in tem:
to_write.append(Graphs.draw_text(p))
# 特殊符号不能出现在文件名中,特判
if title.__contains__('?'):
title = title.split('?')[0]
if title.__contains__(':'):
t = title.split(':')
title = t[0]+t[1]
doc = SimpleDocTemplate('./files/' + id + " " + title + '.pdf', pagesize=LETTER)
doc.build(to_write)
step4 批量爬取
万事俱备,“只欠”运行
def handle_download():
with open("link.txt", "r") as f:
links = f.readlines()
_len = len(links)
for i in range(_len): # 要是爬虫出错被打断,可以改这里的range,不用爬重复的
print(links[i])
handle_spiegel(links[i], i)
print("finish: " + str(i))# 打印进度
完。
浅展示一下结果:
