用Spark计算引擎执行FATE联邦学习任务

题图摄于北京前门
(本文作者系 VMware 中国研发云原生实验室工程师,联邦学习开源项目 KubeFATE / FATE-Operator 维护者。)
需要加入KubeFATE开源项目讨论群的同学,请关注亨利笔记公众号后回复 “kubefate” 即可。
VMware招聘联邦学习、隐私计算开发工程师
相关文章
在Juypter Notebook中构建联邦学习任务
云原生联邦学习平台 KubeFATE 原理详解
用KubeFATE在K8s上部署联邦学习FATE v1.5
使用Docker Compose 部署FATE v1.5
在上篇文章 在Juypter Notebook中构建联邦学习任务 构建任务中提到,FATE 1.5 LTS 版本支持用户使用 Spark 作为底层的计算引擎,本文将对其实现细节以及使用进行简单介绍,方便用户在实际的使用过程中进行调优或者排查错误。
使用分布式计算引擎的意义
在 FATE 中一个比较重要的组件是 "FATE Flow",它负责对用户任务的管理和调度。如官方文档所示,"FATE Flow" 的工作模式有两种,分别为单机 (standalone) 和集群(cluster) 模式。单机模式中,数据的存储以及计算都在 "FATE Flow" 本地执行因此无法有效扩展,所以单机模式主要用于学习以及测试。而在集群模式中,数据的存储以及计算不再通过本地而是下发到分布式的集群中执行,而集群的大小可以根据实际的业务需求来进行伸缩,可满足不同数据集规模的需求。
FATE 默认支持使用 "eggroll" 作为其底下计算和存储的集群,在经过了不断的迭代和优化之后目前已经能够满足大多数联邦学习应用场景的需求。eggroll 本身是一个相对独立的集群,它对外提供一个统一的入口以及一组API,外部应用可以通过 RPC 调用的方式把任务发送到 eggroll 集群上执行,而 eggroll 本身是支持横向扩展的因此用户可以根据实际场景调整集群的规模。
FATE 在 v1.5 中彻底重构了 Apache Spark 作为计算引擎部分,并提供正式支持。Spark 是一个得到业界广泛认可的内存型 (in-memory) 计算引擎,由于其简单、高效和集群管理工具成熟等特性,因此在许多公司的生产环境中被大规模部署和使用。这也是FATE支持使用它的主要原因之一。由于技术原因,目前FATE 对使用 Spark 的支持还不够完善,暂时还不能满足大规模样本(千万级别)的训练任务,但优化的工作已在进行中。
KubeFATE 在 1.5 版本支持了 FATE On Spark 的部署,它可以通过容器的方式启动一个 Spark 集群来为 FATE 提供计算服务,详情可参考下面的章节:使用 Spark 作为计算引擎。
与具体计算引擎进行对接的是 FATE FLow 服务,因此我们将简单分析该服务的结构,以弄明白它是如何跟不同的计算引擎交互。
FATE Flow 结构简介
在 FATE 1.5 中,"FATE Flow" 服务迎来了比较重大的重构,它把存储、计算、联邦传输(federation)等操作抽象成了不同的接口以供上层的应用使用。而接口在具体的实现中可以通过调用不同的库来访问不同的运行时 (runtime),通过这种方式可以非常容易地扩展对其他计算 (如spark) 或存储 (HDFS、MySQL) 服务的支持。一般来说使用FATE进行联邦学习任务可分为以下步骤(假设组网已完成):
调用 FATE Flow 提供的接口上传训练用的数据集
定义训练任务的 pipeline 并调用 FATE Flow 接口上传任务
根据训练的结果不断调整训练参数并得到最终模型
通过 FATE Flow 上传预测用的数据集
定义预测任务并通过 FATE Flow 执行
在上述的步骤中,除了任务的调度必需要 FATE Flow 参与之外,存储和计算等其他部分的工作都可以借助别的服务来完成。
如下图所示,"FATE Flow" 这个方框内列出了部分接口,其中:
"Storage Interface"用于数据集的管理,如上传本地数据、删除上传的数据等。
"Storage Meta Interface"用于数据集的元数据管理。
"Computing Interface"用于执行计算任务。
"Federation Interface"用于在各个训练参与方之间传输数据。
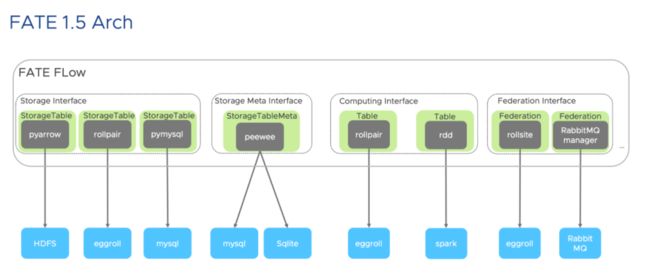
绿色的方格是接口的具体实现,深灰色方格是用于跟远端服务进行交互的客户端,而蓝色的方格则对应着独立于 FATE Flow 服务之外的其他运行时。例如,对于计算接口来说,具体实现了该接口的类是 "Table",而 Table 的类型又分为了两种,其中一种使用 "rollpair" 来跟 "eggroll" 集群交互;而另一种则使用 "pyspark" 中的 "rdd" 来跟 "spark" 集群进行交互。
使用不同计算引擎之间的差异
在上一节中提到,FATE Flow 通过抽象出来的接口可以使用不同的计算、存储等服务,但由于依赖以及实现机制等原因,这些服务在选择上有一定的制约,但具体可分为两类:
使用eggroll作为计算引擎
使用spark作为计算引擎
当使用 eggroll 作为计算引擎时,FATE 的整体架构如下:
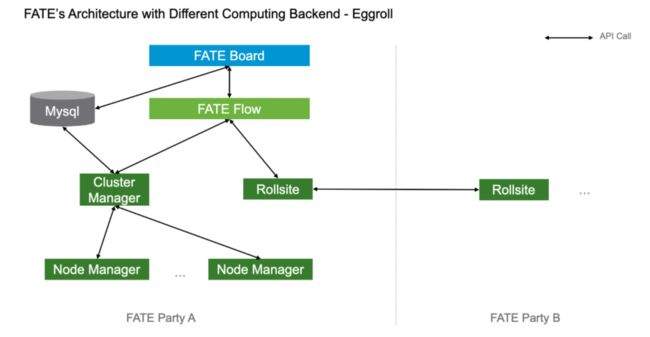
eggroll 集群中有三种不同类型的节点,分别是 Cluster Manager、Node Manager 和 Rollsite,其中 Cluster Manager 负责提供服务入口以及分配资源,Node Manager 是实际执行计算和存储的节点,而 Rollsite 则提供传输服务。
而当使用 Spark 作为计算引擎时,FATE 的整体架构如下:
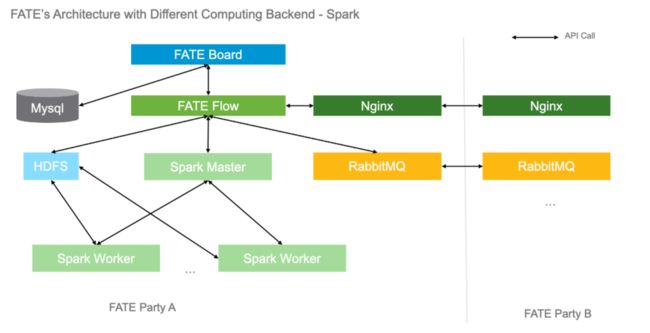
由于Spark 本身是一个内存 (in-memory) 计算框架,一般需要借助其他服务来持久化输出,因此,要在 FATE 中使用 Spark 作为计算引擎还需要借助 HDFS 来实现数据的持久化。至于联邦传输则分为了两部分,分别是指令 (pipeline) 的同步和训练过程中消息的同步,它们分别借助 nginx 和 rabbitmq 服务来完成。
使用Spark作为计算引擎
前置条件
前面的小节提到,要使用 Spark 作为计算引擎还需要依赖于 Nginx、RabbitMQ 以及HDFS 等服务,对于完整的服务安装部署以及配置有三种方式可供参考:
基于裸机的集群安装部署可以参考FATE ON Spark部署指南。
基于 "docker-compose" 的集群安装部署可以参考使用Docker Compose 部署 FATE,只需要把配置文件中的
computing_backend设置成spark即可,在真正部署的时候会以容器的方式拉起 HDFS、Spark 等服务。基于 Kubernetes 的集群部署可以参考Kubernetes部署方案,创建集群时使用 cluster-spark.yaml 文件即可创建一个基于 K8s 的 FATE On Spark 集群,至于Spark 节点的数量也可以在这个文件中定义。
注意:目前经过验证的 Spark、HDFS 以及 RabbitMQ 的版本分别为2.4,2.7和3.8
对于想要利用现有 Spark 集群的用户来说,除了需要部署其他依赖的服务之外还需要解决 FATE 的 python 包依赖,具体措施是给所有要运行联邦学习工作负载的Spark节点进行如下操作:
创建新目录放置文件
$ mkdir -p /data/projects
$ cd /data/projects下载和安装"miniconda"
$ wget https://repo.anaconda.com/miniconda/Miniconda3-4.5.4-Linux-x86_64.sh
$ sh Miniconda3-4.5.4-Linux-x86_64.sh -b -p /data/projects/miniconda3
$ miniconda3/bin/pip install virtualenv
$ miniconda3/bin/virtualenv -p /data/projects/miniconda3/bin/python3.6 --no-wheel --no-setuptools --no-download /data/projects/python/venv下载FATE项目代码
$ git clone https://github.com/FederatedAI/FATE/tree/v1.5.0
// 添加python依赖路径
$ echo "export PYTHONPATY=/data/projects/fate/python" >> /data/projects/python/venv/bin/activate
进入python的虚拟环境
$ source /data/projects/python/venv/bin/activate修改并下载python库
// 剔除tensorflow和pytorch依赖
$ sed -i -e '23,25d' ./requirements.txt
$ pip install setuptools-42.0.2-py2.py3-none-any.whl
$ pip install -r /data/projects/python/requirements.txt至此,依赖安装完毕,之后在 FATE 中提交任务时还需通过配置spark.pyspark.python来指定使用该 python 环境。
示例
当 Spark 集群准备完毕后就可以在 FATE 中使用它了,使用的方式则是在任务的定义中把backend设置为1,这样 "FATE Flow" 就会在后续的调度中,通过 "spark-submit" 工具把提交到 Spark 集群上执行。
需要注意的是,虽然 Spark 集群的 master 可以在任务的配置中指定,但是 HDFS、RabbitMQ 以及 Nginx 等服务需要在 FATE Flow 启动之前通过配置文件的方式指定,因此当这些服务地址发生改变时,需要更新配置文件并重启 FATE Flow 服务。
当 FATE Flow 服务正常启动后,可以使用"toy_example"来验证环境。步骤如下:
修改toy_example_config文件如下:
{
"initiator": {
"role": "guest",
"party_id": 9999
},
"job_parameters": {
"work_mode": 0,
"backend": 1,
"spark_run": {
"executor-memory": "4G",
"total-executor-cores": 4
}
},
"role": {
"guest": [
9999
],
"host": [
9999
]
},
"role_parameters": {
"guest": {
"secure_add_example_0": {
"seed": [
123
]
}
},
"host": {
"secure_add_example_0": {
"seed": [
321
]
}
}
},
"algorithm_parameters": {
"secure_add_example_0": {
"partition": 4,
"data_num": 1000
}
}
}其中spark_run里面定义了要提供给"spark-submit"的参数,因此还可以通过master来指定master的地址、或者conf来指定spark.pyspark.python的路径等,一个简单的例子如下:
...
"job_parameters": {
"work_mode": 0,
"backend": 0,
"spark_run": {
"master": "spark://127.0.0.1:7077"
"conf": "spark.pyspark.python=/data/projects/python/venv/bin/python"
},
},
...如果没有设置spark_run字段则默认读取${SPARK_HOME}/conf/spark-defaults.conf中的配置。更多的关于spark的参数可参考Spark Configuration。
提交任务以及查看任务状态 运行以下命令提交任务运行"toy_example"。
$ python run_toy_example.py -b 1 9999 9999 1查看 fate_board :

查看 Spark 的面板 :
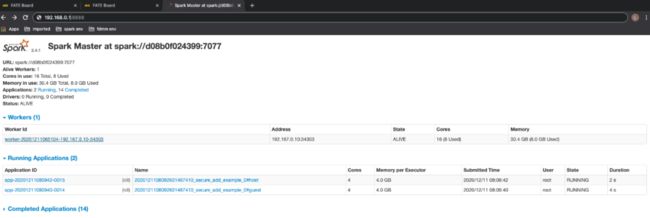
根据上面的输出可以看到,FATE 通过 Spark 集群成功运行了"toy_example"的测试。
总结
本文主要梳理了分布式系统对FATE的重要性,同时也对比了 FATE 所支持两种计算引擎 "eggroll" 和 "spark" 之间的差异,最后详细描述了如何在 FATE 中使用 Saprk 运行任务。由于篇幅有限,关于在如何 FATE 中使用 Spark 的部分只作了简单介绍,更多的内容如节点资源分配、参数调优等还待用户探索。
与 EggRoll 相比,目前 FATE 对 Spark 作为计算引擎的支持还在完善中,相信再经过几个版本的迭代,其使用体验和稳定性以及效率上会达到更高的水准。
需要加入KubeFATE开源项目讨论群的同学,请先关注亨利笔记公众号,然后回复 “kubefate” 即可。
相关链接
KubeFATE:https://github.com/FederatedAI/KubeFATE
FATE:https://github.com/FederatedAI/FATE
要想了解云原生、人工智能和区块链等技术原理,请立即长按以下二维码,关注本公众号亨利笔记 ( henglibiji ),以免错过更新。

欢迎转发、收藏和点 “在看”,或者点击阅读原文。