自然语言处理系列十三》中文分词》机器学习统计分词》隐马尔可夫模型HMM分词
注:此文章内容均节选自充电了么创始人,CEO兼CTO陈敬雷老师的新书《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
文章目录
- 自然语言处理系列十三
-
- 中文分词
-
- 隐马尔可夫模型HMM分词
- 总结
自然语言处理系列十三
中文分词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。我们知道,在英文的行文中,单词之间是以空格作为自然分界符的,而中文的词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比英文要复杂得多、困难得多。
隐马尔可夫模型HMM分词
隐马尔可夫模型(Hidden Markov Model,HMM)是用来描述一个含有隐含未知参数的马尔可夫过程。
- 理解隐马尔科夫
我们通过举例和抽象来理解隐马尔科夫的原理。
1)举例理解
假设我手里有三个不同的骰子。第一个骰子是我们平常见的骰子(称这个骰子为D6),6个面,每个面(1,2,3,4,5,6)出现的概率是1/6。第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
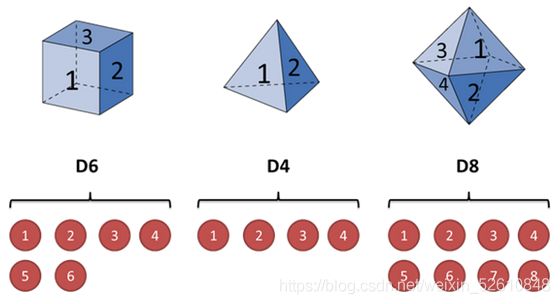
当我们无法观测到时使用哪个骰子投掷,仅仅能看到投掷的结果的时候。例如我们得到一个序列值:1 6 3 5 2 7 3 5 2 4。
它其实包含了:1、隐含的状态,选择了哪个骰子;2、可见状态,使用该骰子投出数值。如下:
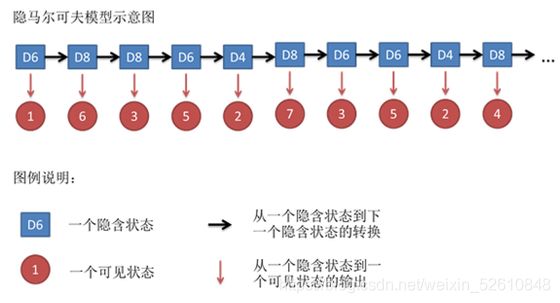
而假设,每个状态间转移的概率(选择骰子的概率)是固定的(即为不因观测值的数值而改变)。可以得到状态转移矩阵。

那么我们得到观测值序列(1 6 3 5 2 7 3 5 2 4)出现概率的计算公式:
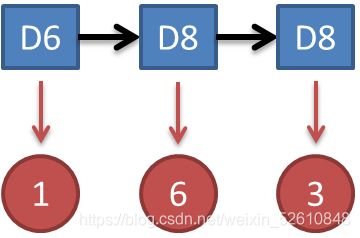
举前3个观测值(1 6 3)的例子,计算如下:
P=P(D6)P(D6→1) P(D6→D8)* P(D8→6)* P(D8→D8)* P(D8→3)=1/31/61/31/81/3*1/8
以上计算中,假设选择3个骰子的概率是相同的,都是1/3。
2)例子抽象
通过以上例子可以抽象一下,上面的例子中:
3种不同情况的骰子,即为:状态值集合(StatusSet)
所有可能出现的结果值(1、2、3、4、5、6、7、8):观察值集合(ObservedSet)
选择不同骰子之间的概率:转移概率矩阵(TransProbMatrix ),状态间转移的概率
在拿到某个骰子,投出某个观测值的概率:发射概率矩阵(EmitProbMatrix )-即:拿到D6这个骰子,投出6的概率是1/6。
最初一次的状态:初始状态概率分布(InitStatus )
所以,很容易得到,计算概率的方法就是,初始状态概率分布(InitStatus )、发射概率矩阵(EmitProbMatrix )、转移概率矩阵(TransProbMatrix )的乘积。
当某个状态序列的概率值最大,则该状态序列即为,出现该观测值的情况下,最可能出现的状态序列。
2. HMM中文分词
怎么使用隐马尔科夫链作分词,原理使用上面的作为理解。下文中提到的SBME4个状态可以类比为上文提到的3个骰子。中文文字即为上文提到的投出的数字。
1)模型
HMM的典型模型是一个五元组:
StatusSet: 状态值集合
ObservedSet: 观察值集合
TransProbMatrix: 转移概率矩阵
EmitProbMatrix: 发射概率矩阵
InitStatus: 初始状态分布。
1)基本假设
HMM模型的三个基本假设如下:
有限历史性假设:
P(Status[i]|Status[i-1],Status[i-2],… Status[1]) = P(Status[i]|Status[i-1])
齐次性假设(状态和当前时刻无关):
P(Status[i]|Status[i-1]) = P(Status[j]|Status[j-1])
观察值独立性假设(观察值只取决于当前状态值):
P(Observed[i]|Status[i],Status[i-1],…,Status[1]) = P(Observed[i]|Status[i])
3)五元组
(1)状态值集合(StatusSet)
为(B, M, E, S): {B:begin, M:middle, E:end, S:single}。分别代表每个状态代表的是该字在词语中的位置,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。
如:
给你一个隐马尔科夫链的例子。
可以标注为:
给/S 你/S 一个/BE 隐马尔科夫链/BMMMME 的/S 例子/BE 。/S
(2)观察值集合(ObservedSet)
为就是所有汉字(东南西北你我他…),甚至包括标点符号所组成的集合。
状态值也就是我们要求的值,在HMM模型中文分词中,我们的输入是一个句子(也就是观察值序列),输出是这个句子中每个字的状态值。
(3)初始状态概率分布(InitStatus)
如:
B -0.26268660809250016
E -3.14e+100
M -3.14e+100
S -1.4652633398537678
数值是对概率值取【对数】之后的结果(可以让概率【相乘】的计算变成对数【相加】)。其中-3.14e+100作为负无穷,也就是对应的概率值是0。
也就是句子的第一个字属于{B,E,M,S}这四种状态的概率。
(4)转移概率矩阵(TransProbMatrix)
【有限历史性假设】
转移概率是马尔科夫链。Status(i)只和Status(i-1)相关,这个假设能大大简化问题。所以,它其实就是一个4x4(4就是状态值集合的大小)的二维矩阵。矩阵的横坐标和纵坐标顺序是BEMS x BEMS。(数值是概率求对数后的值)
(5)发射概率矩阵(EmitProbMatrix)
【观察值独立性假设】
P(Observed[i], Status[j]) = P(Status[j]) * P(Observed[i]|Status[j])
其中,P(Observed[i]|Status[j])这个值就是从EmitProbMatrix中获取。
3)使用Viterbi算法
这五元的关系是通过一个叫Viterbi的算法串接起来,ObservedSet序列值是Viterbi的输入,而StatusSet序列值是Viterbi的输出,输入和输出之间Viterbi算法还需要借助三个模型参数,分别是InitStatus, TransProbMatrix, EmitProbMatrix。
定义变量
二维数组 weight[4][15],4是状态数(0:B,1:E,2:M,3:S),15是输入句子的字数。比如 weight[0][2] 代表 状态B的条件下,出现’硕’这个字的可能性。
二维数组 path[4][15],4是状态数(0:B,1:E,2:M,3:S),15是输入句子的字数。比如 path[0][2] 代表 weight[0][2]取到最大时,前一个字的状态,比如 path[0][2] = 1, 则代表 weight[0][2]取到最大时,前一个字(也就是明)的状态是E。记录前一个字的状态是为了使用viterbi算法计算完整个 weight[4][15] 之后,能对输入句子从右向左地回溯回来,找出对应的状态序列。
代码如下:
B:-0.26268660809250016
E:-3.14e+100
M:-3.14e+100
S:-1.4652633398537678
且由EmitProbMatrix可以得出
Status(B) -> Observed(小) : -5.79545
Status(E) -> Observed(小) : -7.36797
Status(M) -> Observed(小) : -5.09518
Status(S) -> Observed(小) : -6.2475
所以可以初始化 weight[i][0] 的值如下:
weight[0][0] = -0.26268660809250016 + -5.79545 = -6.05814
weight[1][0] = -3.14e+100 + -7.36797 = -3.14e+100
weight[2][0] = -3.14e+100 + -5.09518 = -3.14e+100
weight[3][0] = -1.4652633398537678 + -6.2475 = -7.71276
注意上式计算的时候是相加而不是相乘,因为之前取过对数的原因。
//遍历句子,下标i从1开始是因为刚才初始化的时候已经对0初始化结束了
for(size_t i = 1; i < 15; i++)
{
// 遍历可能的状态
for(size_t j = 0; j < 4; j++)
{
weight[j][i] = MIN_DOUBLE;
path[j][i] = -1;
//遍历前一个字可能的状态
for(size_t k = 0; k < 4; k++)
{
double tmp = weight[k][i-1] + _transProb[k][j] + _emitProb[j][sentence[i]];
if(tmp > weight[j][i]) // 找出最大的weight[j][i]值
{
weight[j][i] = tmp;
path[j][i] = k;
}
}
}
}
确定边界条件和路径回溯
边界条件如下:
对于每个句子,最后一个字的状态只可能是 E 或者 S,不可能是 M 或者 B。
所以在本文的例子中我们只需要比较 weight[1(E)][14] 和 weight[3(S)][14] 的大小即可。
在本例中:
weight[1][14] = -102.492;
weight[3][14] = -101.632;
所以 S > E,也就是对于路径回溯的起点是 path[3][14]。
回溯的路径是:
SEBEMBEBEMBEBEB
倒序一下就是:
BE/BE/BME/BE/BME/BE/S
所以切词结果就是:
小明/硕士/毕业于/中国/科学院/计算/所
接下来的自然语言处理系列将详细讲解感知器分词和CRF分词的原理,并给大家代码演示。
总结
此文章有对应的配套视频,其它更多精彩文章请大家下载充电了么app,可获取千万免费好课和文章,配套新书教材请看陈敬雷新书:《分布式机器学习实战》(人工智能科学与技术丛书)
【新书介绍】
《分布式机器学习实战》(人工智能科学与技术丛书)【陈敬雷编著】【清华大学出版社】
新书特色:深入浅出,逐步讲解分布式机器学习的框架及应用配套个性化推荐算法系统、人脸识别、对话机器人等实战项目
【新书介绍视频】
分布式机器学习实战(人工智能科学与技术丛书)新书【陈敬雷】
视频特色:重点对新书进行介绍,最新前沿技术热点剖析,技术职业规划建议!听完此课你对人工智能领域将有一个崭新的技术视野!职业发展也将有更加清晰的认识!
【精品课程】
《分布式机器学习实战》大数据人工智能AI专家级精品课程
【免费体验视频】:
人工智能百万年薪成长路线/从Python到最新热点技术
从Python编程零基础小白入门到人工智能高级实战系列课
视频特色: 本系列专家级精品课有对应的配套书籍《分布式机器学习实战》,精品课和书籍可以互补式学习,彼此相互补充,大大提高了学习效率。本系列课和书籍是以分布式机器学习为主线,并对其依赖的大数据技术做了详细介绍,之后对目前主流的分布式机器学习框架和算法进行重点讲解,本系列课和书籍侧重实战,最后讲几个工业级的系统实战项目给大家。 课程核心内容有互联网公司大数据和人工智能那些事、大数据算法系统架构、大数据基础、Python编程、Java编程、Scala编程、Docker容器、Mahout分布式机器学习平台、Spark分布式机器学习平台、分布式深度学习框架和神经网络算法、自然语言处理算法、工业级完整系统实战(推荐算法系统实战、人脸识别实战、对话机器人实战)、就业/面试技巧/职业生涯规划/职业晋升指导等内容。
【充电了么公司介绍】
充电了么App是专注上班族职业培训充电学习的在线教育平台。
专注工作职业技能提升和学习,提高工作效率,带来经济效益!今天你充电了么?
充电了么官网
http://www.chongdianleme.com/
充电了么App官网下载地址
https://a.app.qq.com/o/simple.jsp?pkgname=com.charged.app
功能特色如下:
【全行业职位】 - 专注职场上班族职业技能提升
覆盖所有行业和职位,不管你是上班族,高管,还是创业都有你要学习的视频和文章。其中大数据智能AI、区块链、深度学习是互联网一线工业级的实战经验。
除了专业技能学习,还有通用职场技能,比如企业管理、股权激励和设计、职业生涯规划、社交礼仪、沟通技巧、演讲技巧、开会技巧、发邮件技巧、工作压力如何放松、人脉关系等等,全方位提高你的专业水平和整体素质。
【牛人课堂】 - 学习牛人的工作经验
1.智能个性化引擎:
海量视频课程,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习课程。
2.听课全网搜索
输入关键词搜索海量视频课程,应有尽有,总有适合你的课程。
3.听课播放详情
视频播放详情,除了播放当前视频,更有相关视频课程和文章阅读,对某个技能知识点强化,让你轻松成为某个领域的资深专家。
【精品阅读】 - 技能文章兴趣阅读
1.个性化阅读引擎:
千万级文章阅读,覆盖所有行业、所有职位,通过不同行业职位的技能词偏好挖掘分析,智能匹配你目前职位最感兴趣的技能学习文章。
2.阅读全网搜索
输入关键词搜索海量文章阅读,应有尽有,总有你感兴趣的技能学习文章。
【机器人老师】 - 个人提升趣味学习
基于搜索引擎和智能深度学习训练,为您打造更懂你的机器人老师,用自然语言和机器人老师聊天学习,寓教于乐,高效学习,快乐人生。
【精短课程】 - 高效学习知识
海量精短牛人课程,满足你的时间碎片化学习,快速提高某个技能知识点。
上一篇:自然语言处理系列十二》中文分词》机器学习统计分词
下一篇:自然语言处理系列十四》中文分词》机器学习统计分词》感知器分词