SLIP 多模态 文本图像对比学与图像图像对比学习结合
参考:https://github.com/facebookresearch/SLIP
原理:相当于结合clip和simclr两个对比学习的损失,等于文本图像对比学与图像图像对比学习结合

1、离线图像或者文本计算保存
需要先下载预训练好的模型:https://dl.fbaipublicfiles.com/slip/slip_base_100ep.pt
from torchvision import transforms
import torch
from PIL import Image
import models
from tokenizer import SimpleTokenizer
import utils
import sys
from tqdm import tqdm
from collections import OrderedDict
# sys.path.append(r'D:\SLIP')
import pathlib
temp = pathlib.PosixPath
pathlib.PosixPath = pathlib.WindowsPath
import numpy as np
kkk_all = np.load(r"D:\*****媒资aid为键8万左右.npy",allow_pickle=True)
class SLIP_Base():
def __init__(self, model_name):
# self.device = "cuda"
if model_name == "SLIP_VITB16":
ckpt_path = "slip_base_100ep.pt"
elif model_name == "SLIP_VITS16":
ckpt_path = "/home/GitHub_Projects/SLIP/pretrained_models/slip_small_100ep.pt"
self.preprocess_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
lambda x: x.convert('RGB'),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
self.tokenizer = SimpleTokenizer()
ckpt = torch.load(ckpt_path, map_location='cpu')
state_dict = OrderedDict()
for k, v in ckpt['state_dict'].items():
state_dict[k.replace('module.', '')] = v
# create model
old_args = ckpt['args']
old_args.model = model_name
model = getattr(models, old_args.model)(rand_embed=False,
ssl_mlp_dim=old_args.ssl_mlp_dim, ssl_emb_dim=old_args.ssl_emb_dim)
model.requires_grad_(False).eval()
model.load_state_dict(state_dict, strict=True)
n_params = sum(p.numel() for p in model.parameters())
print("Loaded perceptor %s: %.2fM params" %(model_name, (n_params/1000000)))
self.model = utils.get_model(model)
def encode_img(self, imgs, apply_preprocess = True):
if apply_preprocess:
imgs = self.preprocess_transform(imgs).unsqueeze(0)
# print(imgs.shape,imgs)
image_features = self.model.encode_image(imgs)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
return image_features
def encode_text(self, texts):
texts = self.tokenizer(texts)
texts = texts.view(-1, 77).contiguous()
text_embeddings = self.model.encode_text(texts)
text_embeddings = text_embeddings / text_embeddings.norm(dim=-1, keepdim=True)
return text_embeddings.unsqueeze(1)
clip_perceptor = SLIP_Base("SLIP_VITB16")
#print(clip_perceptor.encode_text("i love you"))
# 计算缩略图向量
aidss=[]
imgss=[]
for i in tqdm(list(kkk_all.tolist().keys())[:20000]):
try:
aidss.append(i)
# print(image1.type(dtype))
with torch.no_grad():
image_features = clip_perceptor.encode_img(Image.open(r"D:\媒资少儿动漫母婴图片\{}.jpg".format(i)))
imgss.append(image_features)
print(type(image_features))
except Exception as e:
print(e)
print("####")
aidss.pop()
pass
val= torch.tensor([item.detach().numpy() for item in imgss])
# 保存
np.save("媒资少儿动漫母婴_aidss.npy", aidss)
np.save("媒资少儿动漫母婴_image_features_embs.npy", val)
以文搜图与以图搜图
"""
缩略图向量语义召回
"""
from torchvision import transforms
import torch
from PIL import Image
import models
from tokenizer import SimpleTokenizer
import utils
import sys
from tqdm import tqdm
import random
import numpy as np
from collections import OrderedDict
from flask import Flask
from flask import render_template, request
import requests
# sys.path.append(r'D:\SLIP')
import pathlib
temp = pathlib.PosixPath
pathlib.PosixPath = pathlib.WindowsPath
app = Flask(__name__)
## 全部信息字典
kkk_all = np.load(r"D:\****媒资aid为键8万左右.npy",allow_pickle=True).item()
# 加载图像数据
# kkk_dict_all = np.load(r"少儿动漫母婴媒资信息111.npy", allow_pickle=True).item()
image1 = np.load(r"媒资少儿动漫母婴_image_features_embs.npy", allow_pickle=True)
# aidss = list(kkk_dict_all.keys())
image = torch.Tensor(image1)
print(image.shape)
aidss1 = np.load(r"媒资少儿动漫母婴_aidss.npy", allow_pickle=True)
aidss = aidss1.tolist()
# 加载模型
class SLIP_Base():
def __init__(self, model_name):
# self.device = "cuda"
if model_name == "SLIP_VITB16":
ckpt_path = "slip_base_100ep.pt"
elif model_name == "SLIP_VITS16":
ckpt_path = "/home/GitHub_Projects/SLIP/pretrained_models/slip_small_100ep.pt"
self.preprocess_transform = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
lambda x: x.convert('RGB'),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
self.tokenizer = SimpleTokenizer()
ckpt = torch.load(ckpt_path, map_location='cpu')
state_dict = OrderedDict()
for k, v in ckpt['state_dict'].items():
state_dict[k.replace('module.', '')] = v
# create model
old_args = ckpt['args']
old_args.model = model_name
model = getattr(models, old_args.model)(rand_embed=False,
ssl_mlp_dim=old_args.ssl_mlp_dim, ssl_emb_dim=old_args.ssl_emb_dim)
model.requires_grad_(False).eval()
model.load_state_dict(state_dict, strict=True)
n_params = sum(p.numel() for p in model.parameters())
print("Loaded perceptor %s: %.2fM params" %(model_name, (n_params/1000000)))
self.model = utils.get_model(model)
def encode_img(self, imgs, apply_preprocess = True):
if apply_preprocess:
imgs = self.preprocess_transform(imgs).unsqueeze(0)
print(imgs.shape,imgs)
image_features = self.model.encode_image(imgs)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
return image_features
def encode_text(self, texts):
texts = self.tokenizer(texts)
texts = texts.view(-1, 77).contiguous()
text_embeddings = self.model.encode_text(texts)
text_embeddings = text_embeddings / text_embeddings.norm(dim=-1, keepdim=True)
return text_embeddings
clip_perceptor = SLIP_Base("SLIP_VITB16")
@app.route('/', methods=['GET', 'POST'])
def build_plot():
query = request.args.get('query')
psword = request.args.get('psword')
print(query,psword)
if "陀螺" not in query:
# query翻译成英文
data22 = {
"i": query,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false"
}
response = requests.post("http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule", data=data22).json()
bb = response["translateResult"][0][0]["tgt"]
print(bb)
else:
bb = "beyblade"
print(bb)
# 文本向量化计算
# text1 = clip.tokenize(["Ulraman"]).to(device)
# text1 = clip.tokenize([bb]).to(device)
# text1 = clip.tokenize([bb]).to(device)
with torch.no_grad():
text_features = clip_perceptor.encode_text(bb)
# text_features /= text_features.norm(dim=-1, keepdim=True)
# 文本与图形相似度计算召回
print(text_features.shape)
similarities = (image @ text_features.T).squeeze(1)
best_photo_idx = np.argsort(similarities[:, 0].numpy())[::-1]
print(best_photo_idx)
rank_results = [aidss[i] for i in best_photo_idx[:50]]
# 召回结果封装
infos1 = []
pics1 = []
alls1=[]
for j in rank_results:
# print(j)
items = kkk_all[j]
infos1.append(items[0]+"_"+ j+"_"+items[1])
pics1.append(kkk_all[j][2])
alls1.append((j,items[0],items[1]))
print(rank_results, infos1,alls1)
if titles:
return render_template('display1.html', query=query, translate=bb, lis1=titles[:10], lis2=pics[:10], lis3=infos1,
lis4=pics1,lis6=alls1, aid_lists=rank_results, idx_lists=best_photo_idx[:50])
else:
return render_template('display2.html', query=query, translate=bb, lis3=infos1, lis4=pics1,lis6=alls1,
aid_lists=rank_results, idx_lists=best_photo_idx[:50])
# if titles:
# return render_template('display1.html', query=query, translate=bb, lis1=titles[:10], lis2=pics[:10], lis3=titles1, lis4=pics1, lis5=titles2, lis6=pics2, aid_lists=rank_results)
# else:
# return render_template('display2.html', query=query, translate=bb, lis3=titles1, lis4=pics1, lis5=titles2, lis6=pics2, aid_lists=rank_results)
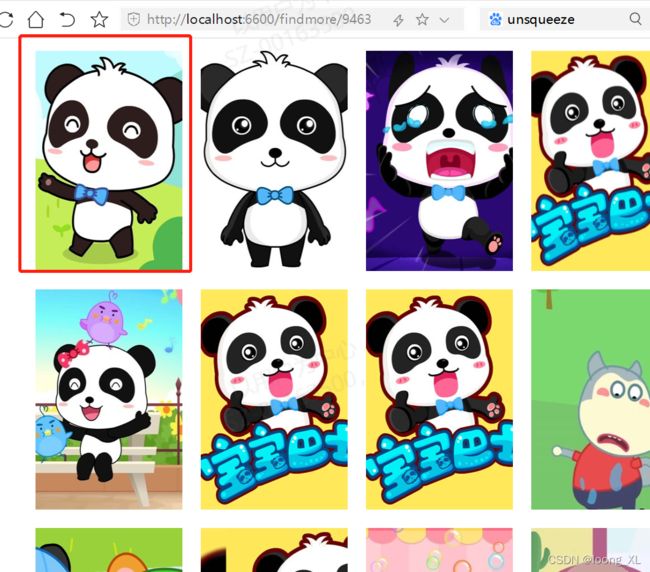
@app.route('/findmore/', methods=['GET'])
def myinfohtml(username):
print(username)
print(type(username))
# image to image
# source_image = r"D:\tcl\媒资图\图\{}.jpg".format(username)
# with torch.no_grad():
# image_feature = model.encode_image(preprocess(Image.open(source_image)).unsqueeze(0).to(device))
# image_feature = (image_feature / image_feature.norm(dim=-1, keepdim=True)).cpu().numpy()
image_feature = image.index_select(0, torch.tensor([int(username)]))
# print(image_feature)
image_feature = image_feature.squeeze(1).cpu().numpy()
##图搜图
best_photo_ids1 = (image @ image_feature.T).squeeze(1)
best_photo_idx2 = np.argsort(best_photo_ids1[:, 0].numpy())[::-1]
rank_results2 = [aidss[i] for i in best_photo_idx2[:50]]
# ##图搜文
# best_title_ids1 = (text @ image_feature.T).squeeze(1)
# best_title_idx2 = np.argsort(best_title_ids1[:, 0].numpy())[::-1]
# rank_results3 = [text_aidss[i] for i in best_title_idx2[:50]]
# rank_results3_titles = [ text_dicts[i][0] for i in rank_results3 ]
# rank_results3_pics = [ text_dicts[i][1] for i in rank_results3 ]
# print(rank_results3_titles,rank_results3_pics)
# 召回结果封装
# titles3 = []
# pics3 = []
# for j in rank_results2:
# titles3.append(kkk_dict_all[j][0])
# pics3.append(kkk_dict_all[j][1])
# print(titles3, pics3)
# 召回结果封装
infos3 = []
pics3 = []
alls3 = []
for j in rank_results2:
# print(j)
items = kkk_all[j]
infos3.append(items[0]+"_"+ j+"_"+items[1])
pics3.append(kkk_all[j][2])
alls3.append((j,items[0],items[1]))
# print(infos3, pics3)
return render_template('display3.html', lis31=infos3, lis32=pics3, lis6=alls3,aid_lists=rank_results2, idx_lists=best_photo_idx2[:50])
if __name__ == '__main__':
app.run("0.0.0.0", 6600, debug=True, threaded=True)
以文搜图
1、搜索小狗狗
2、两只小猫
3、雪地上的动物
以图搜图