Kafka Producer 开发
Kafka Producer 开发
kafka包含5个核心的API接口定义:
- Producer API - 允许应用程序往kafka集群中的topic中发送事件消息
- Consumer API - 允许应用程序从kafka topic 中读取数据
- Streams API - 允许对输入数据流进行数据计算、转换,并发送到其他主题进行消费
- Connect API - 实现connector API,从某个源系统、应用程序持续的拉入数据至kafka,或者从kafka推数据至sink 应用
- Admin API - 允许管理、监控 消息主题、broker、其它kafka元数据对象
简单的理解,kafka Producer 就是向kafka写入数据的应用程序,接下来实现一个最简单的 Producer 生产者程序。
Maven依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>3.3.1version>
dependency>
程序代码
public class SimpleProducer {
public static void main(String[] args) {
String topicName = "simple_topic";
Properties props = new Properties();
//指定kafka 服务器连接地址
props.put("bootstrap.servers", "localhost:9092");
// ack 机制
props.put("acks", "all");
// 发送失败 重试次数
props.put("retries", 0);
// 消息发送延迟时间 默认为0 表示消息立即发送,单位为毫秒
props.put("linger.ms", 1);
// 序列化方式
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for(int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<>(topicName,
Integer.toString(i), "message : " + i));
}
System.out.println("Message sent successfully");
producer.close();
}
}
验证测试
创建topic
$ ./bin/kafka-topics.sh --create --topic simple_topic --bootstrap-server localhost:9092
启动消费者
# 启动kafka自带的消费者脚本
$ ./bin/kafka-console-consumer.sh --topic simple_topic --bootstrap-server localhost:9092
测试结果
首先,启动生产者代码,消费者控制台输出如下

发送机制
同步获取结果
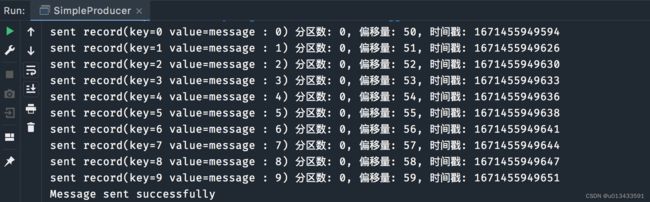
Kafka提供了一种同步发送方法,用于向主题发送记录。让我们使用这个方法向我们之前创建的Kafka主题发送一些消息id和消息。
for(int i = 0; i < 10; i++) {
try {
ProducerRecord<String, String> record = new ProducerRecord<>(topicName,
Integer.toString(i), "message : " + i);
Future<RecordMetadata> send = producer.send(record);
//同步等待 发送结果
RecordMetadata metadata = send.get();
System.out.println(String.format("sent record(key=%s value=%s) 分区数: %d, 偏移量: %d, 时间戳: %d",
record.key(),
record.value(),
metadata.partition(),
metadata.offset(),
metadata.timestamp()
));
}catch (Exception e){
e.printStackTrace();
}
}
异步回调
Kafka提供了一种异步发送方法,用于向主题发送记录。生产者发送成功后,自动调用回调方法输出消息的元数据,这里的最大区别是使用lambda表达式来定义回调。
for(int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>(topicName,
Integer.toString(i), "message : " + i);
// 发送成功 执行callback回调函数
producer.send(record, (metadata, exception) -> {
if (metadata != null) {
System.out.println(String.format("sent record(key=%s value=%s) 分区数: %d, 偏移量: %d, 时间戳: %d",
record.key(),record.value(),
metadata.partition(), metadata.offset(),metadata.timestamp()
));
}
});
}
//等待回调执行完毕
TimeUnit.SECONDS.sleep(1);
批量发送
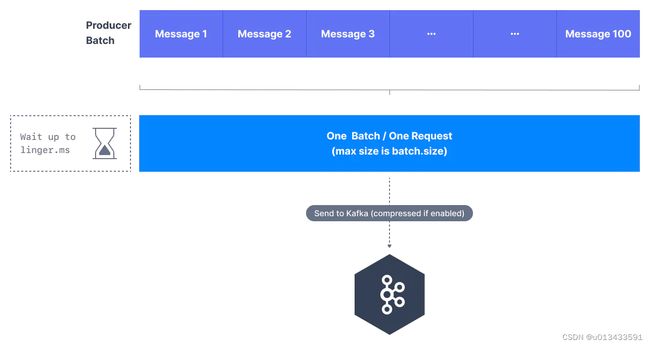
默认情况下,kafka会尽快的发送message至Broker,这对于消息有时效性的场景非常的有效,但是却降低了kafka的吞吐量,原因是每次发送数据都需要进行一次网络传输。如果允许一定时间的延迟(通常情况下,是毫秒级别),且消息吞吐量非常大的场景,可以采用批量发送方式。
kafka批处理机制允许Kafka提高吞吐量,同时保持非常低的延迟。批处理具有更高的压缩比,因此具有更好的磁盘和网络效率。对开发这而言,kafka的批量发送机制,并不需要更改任何业务代码,主要由两个生成器设置控制:linger.ms和batch.size。
如下图所示,生产者允许等待指定的时间,将等待时间内的消息 M0 - M100 一次性发送到服务端。这里有两种情况
-
batch.size
Producer生产者的最重要的参数之一,对于调优producer吞吐量和延迟性指标有非常重要的作用。producer将发往同一分区的消息封装到一个batch中,当batch中的消息数量,满足指定的 大小时 ,producer 会发送batch中的所有消息。
但是,考虑一个极端的场景,由于消息迟迟不能满足 batch.size的大小,导致消息不能发送到服务端,那么消息就会出现延迟,甚至是丢失的风险,此时 linger.ms参数派上用场
-
linger.ms
该参数是控制消息延迟发送行为,默认为0,表示立即发送数据,并不关心 batch 是否已满。上面提到的极端情况,可以允许指定消息延迟发送时间,单位是毫秒,时间到达,不管batch是否满足,立即发送。
实际上该参数是系统吞吐量和延迟时间之间的权衡。
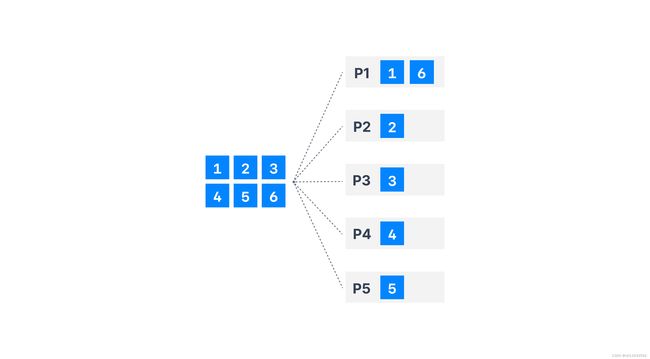
分区机制
kafka是一个分布式流处理系统,当kafka集群部署时,如上图所示,一个topic可能存在N个分区。那么producer生产者将如何选择对应的分区进行数据发送呢?
核心接口
kafka提供了分区策略以及默认的分区方式供用户使用,分区策略的核心接口定义:
public interface Partitioner extends Configurable, Closeable {
/**
* 根据指定记录 计算分区
*/
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
/**
* 分区关闭时 调用该方法
*/
void close();
@Deprecated
default void onNewBatch(String topic, Cluster cluster, int prevPartition) {
}
}
默认分区算法

在3.3.1的版本中,提供了三个分区方法,其中两个已经过期,不建议使用,RoundRobin轮训算法分区策略的核心代码如下
public class RoundRobinPartitioner implements Partitioner {
private final ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 获取集群分区数
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
int numPartitions = partitions.size();
//根据topic 累加
int nextValue = nextValue(topic);
List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);
if (!availablePartitions.isEmpty()) {
// 累加值取模 计算分区数
int part = Utils.toPositive(nextValue) % availablePartitions.size();
return availablePartitions.get(part).partition();
} else {
return Utils.toPositive(nextValue) % numPartitions;
}
}
private int nextValue(String topic) {
AtomicInteger counter = topicCounterMap.computeIfAbsent(topic, k -> new AtomicInteger(0));
return counter.getAndIncrement();
}
//...
}
轮训策略效果如下图