mysql 的Myisam和InnoDB的索引结构
今天更深入的研究了一下索引, 就把我研究的东西给大家分享一下吧, 欢迎大佬指正
先创建两个表

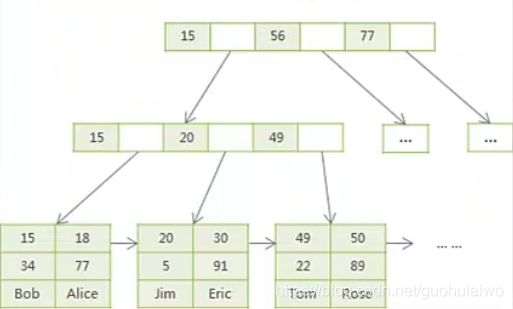
1. Myisam
Myisam的数据文件是三个, 一个是原数据和结构, 一个是索引, 一个是数据, 大家在创建好之后可以看在数据文件里面看下
左侧是主键的索引结构, B+Tree, 叶子节点(最下层)储存的是数据地址, 通过查询条件查询的时候, 查找的是数据地址, 通过数据地址拿到数据,
右侧是普通索引, 拿左侧途中的col2字段作为索引, 和主键查询是一样的, 查找的都是数据地址, 通过数据地址拿到数据


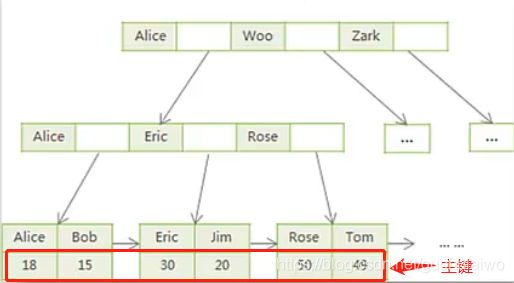
2. InnoDb
InnoDb的数据文件时一个, 所以, 表的索引和数据都是在一起的
左侧图片是主键索引, 索引和数据都是存放在一起的, 通过主键可以直接查询到数据
右侧图片是普通索引, 通过普通索引查询到的数据是主键id, 通过主键id再去查询对应的数据, 这里就存在了一个回表的过程
3. 总结
可以自己试一下, 在插入数据的时候, 主键id可以不按着顺序插入, 我们会发现, myisam在插入之后, 主键id的顺序没有变, 但是, innodb的数据是根据主键id排好序的, 这就是因为, innodb的索引和数据是在一起的, B+Tree叶子节点会排序, 所以在插入的时候会根据主键id排好序,
我们通常用的表数据引擎一般都是innodb, 在构建索引的时候, 普通索引, 查出来的都是对应数据的主键, 然后根据主键去查询的数据, 这里面存在一个回表的过程, 而且主键在排序的时候是按顺序排的, 用整型去查询和排序肯定是最快的, 所以, 由此可见, 主键最好是, 用一个自增的id, 这样查询的会很快, 而且有这个回表, 我们也可以在查询表的时候, 根据普通索引先去查询id, 再根据id去查询想要的数据, 这样就能避免回表, 尤其是在分页, 页数比较大的时候, 效果很明显

数据量越大的的时候InnoDb的抗压能力就越明显, 效果会更好
我表达的可能不是很清楚, 请大佬们指点, 哦对了, 上述截图, 都是我看的 < 柳峰 >大佬的视频的时候截下来的图, 直接用了
小李大人
爱生活爱慧姐
2021年3月3日