卷积神经网络实战二 电机轴承故障分类
项目导论
最近实验室要接一个故障分类的项目,数据主要是传感器测得的各种数据,现在先用网上的数据集学习一下怎么处理。
数据集介绍
采用由凯斯西储大学轴承数据中心网站发布的电机轴承数据。此网站提供正常运行状态的电机轴承数据和不同部位发生故障是运行状态的电机轴承数据。在研究电机轴承故障诊断方面起到了重要作用。
通过电火花方式加工电机轴承的各种故障。在内圈、滚动体(即滚动体)和外圈分别制作损坏直径大小分别为0.007inch、0.014inch、0.021inch的故障。(1 inch=25.4 毫米)
不同的故障直径体现不同的损伤程度。将制作的故障轴承安装到测试电机上进行测试。电机轴承在运行过程中的振动数据通过安装在电机的驱动部位和风扇部位的加速度计采集。
实验分别记录了电机转速1797rpm、1772rpm、1750rpm和1730rpm下采集到的数据。
数据存储为Matlab格式。
之前在原网站上下载和整理数据花了很多时间,这里直接提供百度云链接。
链接:https://pan.baidu.com/s/1nXLCE9nXucQhY72rkYN7ZQ
提取码:nzig
另外,人工智能入门四件套免费分享(统计学习方法、机器学习、机器学习实战、深度学习)
链接:https://pan.baidu.com/s/1kG3cRvto75krhjz1Ow4ANw 提取码:b8r1
数据集准备
先用48K采样频率、转速1730的数据进行实验,这样一共可以分为十类。


在工程下新建一个data文件夹,将这十个文件拖进去,接下来载入数据,观察里面的结构。
import pandas as pd
import scipy
from scipy import io
import os
matPath='.\\data\\'
for i in os.listdir(matPath):
inputFile = os.path.join(matPath,i)
feature_struct = scipy.io.loadmat(inputFile)
print(feature_struct)
观察输出可以看到每个文件的结构类似,都是字典,字典最后一个键是转速,倒数第二个是FE_time(风扇端测得的数据),倒数第三个是DE_time(驱动端测得的数据),对应的值是存储传感器数据的数组。
第一个文件的结构

这样我们就可以得到观测数据。
DE_time = list(feature_struct.values())[-3]
FE_time = list(feature_struct.values())[-2]
但一个数据集里的观测数据很多,
![]()
为了后期的训练,需要将整个数据集分割,在这里每取1024个数据点制作1个样本。里面包括了两种观测数据,我在这暂时只使用驱动端观测数据进行训练。
切割完后分别将3/4的样本存入train以及1/4的样本存入test文件夹。
完整的数据处理代码
import pandas as pd
import scipy
from scipy import io
import os
matPath='.\\data\\'
outPath_train='.\\train\\'
outPath_test ='.\\test\\'
for i in os.listdir(matPath):
inputFile = os.path.join(matPath,i)
feature_struct = scipy.io.loadmat(inputFile)
#print(feature_struct)
DE_time = list(feature_struct.values())[-3]
#FE_time = list(feature_struct.values())[-2]
lst = []
j = 0
for a, b in enumerate(DE_time):
if a / 1024 < j + 1:
lst.extend(b)
else:
j += 1
if j <= int((len(DE_time) / 1024) * 3/4):
outputFile = os.path.join(outPath_train, os.path.split(i)[1][:-4])
data = pd.DataFrame(data=lst)
dfdata = pd.DataFrame(data=data)
datapath1 = outputFile + '_' + str(j) + '.csv'
dfdata.to_csv(datapath1, index=False)
else:
outputFile = os.path.join(outPath_test, os.path.split(i)[1][:-4])
data = pd.DataFrame(data=lst)
dfdata = pd.DataFrame(data=data)
datapath1 = outputFile + '_' + str(j) + '.csv'
dfdata.to_csv(datapath1, index=False)
lst = []
lst.extend(b)
if j == int(len(DE_time) / 1024):break
train文件夹部分显示

每个分类可以得到三百五十几个样本,有点少,先用着处理,后期提高模型训练准确度时再把12K采样频率得到的同类型数据加进来。
test文件夹部分显示

数据预处理
输入信号是一维加速度数据,在这里先直接把数据扔进模型里训练,预处理步骤仅制作Onehot编码和打乱顺序。
import numpy as np
import os
import pandas as pd
from sklearn.utils import shuffle
import keras
import tensorflow as tf
os.environ["CUDA_VISIBLE_DEVICES"] = "2" #使用GPU2
n_classes = 10
def data_processing(Datapath):
X = []
Data_num = len(os.listdir(Datapath))
data_labels = []
for filename in os.listdir(Datapath):
category = filename.split('_', 1)[0]
if category == 'Normal':
data_labels.append(0)
elif category == 'B007':
data_labels.append(1)
elif category == 'B014':
data_labels.append(2)
elif category == 'B021':
data_labels.append(3)
elif category == 'IR007':
data_labels.append(4)
elif category == 'IR014':
data_labels.append(5)
elif category == 'IR021':
data_labels.append(6)
elif category == 'OR007@6':
data_labels.append(7)
elif category == 'OR014@6':
data_labels.append(8)
elif category == 'OR021@6':
data_labels.append(9)
inputFile = os.path.join(Datapath, filename)
data = pd.DataFrame(pd.read_csv(inputFile, header=0))
X.append(np.array(data))
train_x = np.array(X).reshape(-1,1024)
train_y = np.array(data_labels).reshape(-1,1)
indx = np.arange(0,Data_num)
indx = shuffle(indx)
train_x = train_x[indx]
train_y = train_y[indx]
train_y = keras.utils.to_categorical(train_y,n_classes)
return train_x.reshape(-1,1024,1,1),train_y
test_x,test_y = data_processing("test")
train_x,train_y = data_processing("train")
模型搭建
先使用简单的网络结构,观察训练效果。
#神经网络参数
batch_size = 128
training_epochs = 20
learning_rate = 0.001
data_num = train_x.shape[0]
def weight_variable(shape,stddev=0.1):
initial = tf.truncated_normal(shape,stddev=stddev)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape=shape)
return tf.Variable(initial)
#网络结构
x = tf.placeholder(tf.float32,[None,1024,1,1])
y = tf.placeholder(tf.float32,[None,10])
#conv1
w_conv1 = weight_variable([5,1,1,64])
b_conv1 = bias_variable([64])
conv1 = tf.nn.relu(tf.nn.conv2d(x,w_conv1,strides=[1,1,1,1],padding='SAME')+b_conv1)
pool1 = tf.nn.max_pool(conv1,ksize=[1,2,1,1],strides=[1,2,1,1],padding="SAME")
#conv2
w_conv2 = weight_variable([5,1,64,128])
b_conv2 = bias_variable([128])
conv2 = tf.nn.relu(tf.nn.conv2d(pool1,w_conv2,strides=[1,1,1,1],padding='SAME')+b_conv2)
pool2 = tf.nn.max_pool(conv2,ksize=[1,2,1,1],strides=[1,2,1,1],padding="SAME")
#fc1
flatten = tf.reshape(pool2,[-1,256*128])
w_fc1 = weight_variable([256*128,1024])
b_fc1 = bias_variable([1024])
fc1 = tf.nn.relu(tf.add(tf.matmul(flatten,w_fc1),b_fc1))
#out
w_out = weight_variable([1024,10])
b_out = bias_variable([10])
prediction = tf.add(tf.matmul(fc1,w_out),b_out)
#Loss
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=prediction,labels=y))
tf.summary.scalar("loss",loss)
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(loss)
correct_pred = tf.equal(tf.argmax(prediction,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred,tf.float32))
tf.summary.scalar("accuray",accuracy)
#保存模型
saver = tf.train.Saver()
savedir = 'log/CNN(3)_model'
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
merged_summary_op = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('log/summary', sess.graph)
for epoch in range(training_epochs):
total_batch = int(data_num/batch_size)
for i in range(total_batch):
batch_x = train_x[i * batch_size:batch_size * (i + 1), :]
batch_y = train_y[i * batch_size:batch_size * (i + 1), :]
_,acc,Loss = sess.run([optimizer,accuracy,loss],feed_dict={x:batch_x,y:batch_y})
if i%10==0 :print("Epoch:", '%04d' % (epoch + 1), "i:",i,"cost=", "{:.9f}".format(Loss), "Training accuracy", "{:.5f}".format(acc))
summary_str = sess.run(merged_summary_op, feed_dict={x: batch_x, y: batch_y})
summary_writer.add_summary(summary_str, epoch)
print(" Finished!")
saver.save(sess, savedir)
test_feed = {x: test_x, y: test_y}
print('Testing Accuracy:', sess.run(accuracy, feed_dict=test_feed))
Loss、Accuracy、Testing Accuracy


Testing Accuracy:0.7984887
分析1
训练时后期的准确率已经在100%左右,损失值也收敛为0,但是测试准确率只有80%左右,最低只有70多,说明模型发生了过拟合现象。
卷积神经网络中改善过拟合的方式有:dropout、正则化、增大数据集以及批量归一化,之后将分别使用这些方法进行优化。
模型优化
网络结构参数优化
CNN训练时,一开始卷积核的个数尽量设大一些,这是为了训练出过拟合模型,之后再逐步调小,找出最优的参数。这样可以节省寻找参数的时间。

选择用最后一组参数进行接下来的优化。
dropout

注1:dropout<=0.5时,20次训练,后面的训练准确率在90%出头;
可见dropout确实降低了模型的过拟合,提高了测试准确率,选择dropout=0.5,继续进行接下来的优化。
批量归一化

在加入批量归一化后,模型的测试准确率得到了提高,好几次都在90%左右,相比与一开始的80%左右有了显著提高,接下来我们继续加入正则化看看训练效果。
正则化
loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=prediction,labels=y)) + tf.nn.l2_loss(w_conv1)*reg + \
tf.nn.l2_loss(w_conv2)*reg + tf.nn.l2_loss(w_fc1)*reg



可以看出在reg=0.2时,模型训练准确度和测试准确度相差不大,模型已经不在过拟合状态,这是适当增大dropout以及增加训练次数来进一步优化。
training_epochs = 50
learning_rate = 0.001
dropout = 0.6
reg = 0.02
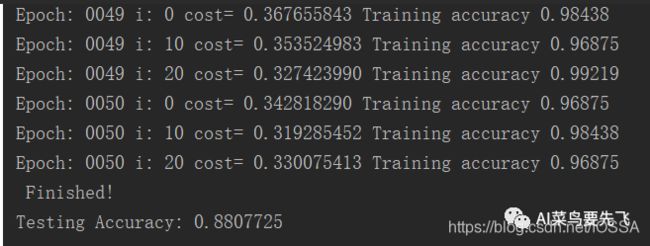
此时,

可以看出,后面的训练准确率一直在波动提不高,说明后期的学习率过高了,在这加入退化学习率。
global_step = tf.Variable(0,trainable=False)
decaylearning_rate = tf.train.exponential_decay(learning_rate,global_step,80,0.9) #退化学习率
分析2
在正则化这一顿操作并没有提高模型准确率,它的作用也是降低过拟合,实际上,批量归一化的收敛非常快,并且具有很强的泛化能力,有时可以完全代替正则化和dropout,它们的作用并不是叠加起来的,在降低过拟合上有些重复了。
到这里,我们的模型准确率相比于一开始提高了10%左右,已经接近90%,但是距离100%还有差距,怎么调模型参数都没有大一点的提高。
这是因为我们的数据量不够,而且没有对数据进行任何预处理,想要进一步提高模型准确率,需要对数据做一些处理。
电机故障检测的后续,将对数据进行处理后再重新训练观察效果。
欢迎交流!
分析3
之前看论文的时候,有几篇都是对这个数据集进行处理,但是不知道为什么每类有上千个样本,我这里只有几百个,之前忙也没在意就扔一边了,今天看到几篇博客都说用重叠取样这个方法,准确率很高,也就是滑动窗口,每隔一段距离就取一个样本,这样可以得到很多样本。
然后我自己实现了一下,准确率确实提高了很多,快接近100%了,不过想了一下,这不相当于基本上全部数据都进去训练过了,得到了一个过拟合模型。不太靠谱,哈哈。