卷积神经网络(二)- 深度卷积网络:实例研究
本次学习笔记主要记录学习深度学习时的各种记录,包括吴恩达老师视频学习、花书。作者能力有限,如有错误等,望联系修改,非常感谢!
卷积神经网络(二)- 深度卷积网络:实例研究
- 一、为什么要进行实例研究(Why look at case studies?)
- 二、经典网络(Classic networks)
- 三、残差网络(Residual Networks-ResNets)
- 四、残差网络为什么有用(Why ResNets work?)
- 五、网络中的网络以及1x1卷积(Network in Network and 1x1 convolutions)
- 六、谷歌Inception网络简介(Inception network motivation)
- 七、Inception网络(Inception network)
- 八、使用开源的实现方案(Using open-source implementations)
- 九、迁移学习(Transfer Learning)
- 十、数据增强(Data augmentation)
- 十一、计算机视觉现状(The state of computer vision)
第一版 2022-07-16 初稿
一、为什么要进行实例研究(Why look at case studies?)
提纲:
经典网络:
1.LeNet-5
2.AlexNet
3.VGG
ResNet
Inception
二、经典网络(Classic networks)
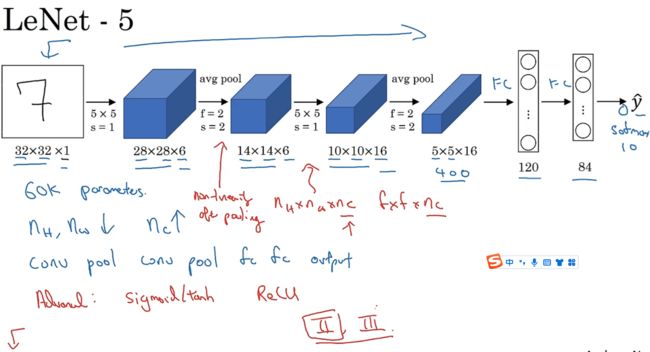
LeNet-5识别手写数字:针对灰度图片训练
输入图片32x32x1,使用6个5x5过滤器,s=1;然后平均池化操作,然后卷积,接着池化;最后全连接层有400个节点,每个节点有120个神经元,再接着全连接层,得84个特征,根据其加上softmax函数得到输出。之前LeNet-5用到的是另一种分类器。
此网络还有一种模式:即一个或多个卷积层后跟一个池化层。
过去人们常用sigmoid函数和tanh函数,而非ReLu函数。
论文链接:https://ieeexplore.ieee.org/abstract/document/726791
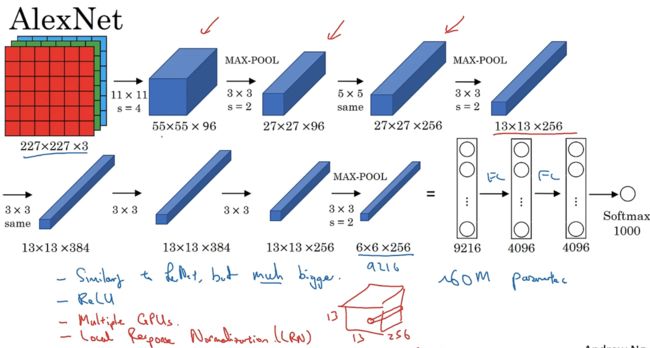
AlexNet:
input:227x227x3的图片
第一层:96个11x11的过滤器,步幅4
池化层:3x3的过滤器构建最大池化层,步幅为2
第三层:5x5卷积
最大池化
same卷积
same卷积
same卷积
最大池化层
池化层为6x6x256=9216,展开9216个单元
两个全连接层FC
最后softmax函数输出识别的结果。
AlexNet和LeNet相似,但LeNet需6万个参数,AlexNet需6000万个参数。
AlexNet更出色原因:
1.能处理包含大量隐藏单元的基本构造模块;
2.使用了ReLu激活函数。
AlexNet在两个GPU上进行训练
经典的AlexNet还有一种层叫“局部响应归一化层(Local Response Normalization,LRN)”,
基本思想是:假如有网络的一块13x13x256,LRN做的是选取一个位置,得到256个数字,并进行归一化。
动机是:对于此图像的每个位置来说,可能并不需要太多的高激活神经元。但被发现LRN好像起不到太大的作用。

VGG网络没有那么多超参数,是一种需要构建卷积层的简单网络。
输入为224x224x64:;
1.64个3x3,步幅1的过滤器构建卷积层,padding为same卷积中的参数,卷积2次;
2.2x2,步幅2的过滤器构建最大池化层;
3.多层卷积池化后,得到7x7x512的特征图进行全连接操作,然后进行softmax激活。
16指的是包含16个卷积层和全连接层,包含1.38亿个参数。
三、残差网络(Residual Networks-ResNets)
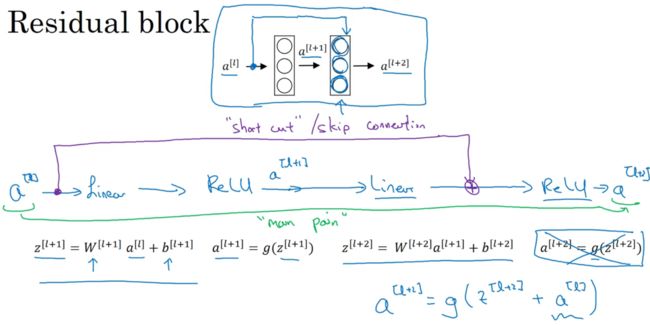
跳跃连接:可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。
ResNets是由残差块(Residual block)构建的,残差块是两层神经网络,在L层进行激活,得到a[l+1],从L层进行激活,首先线性激活,由a[l]计算出z[l+1],然后通过ReLu非线性激活函数得到a[l+1]=g(z[l+1]),依次计算。
残差网络中有一点变化,将a[l]直接向后,拷贝到神经网络的深层,最后操作变为a[l+2]=g(z[l+2]+a[l])。
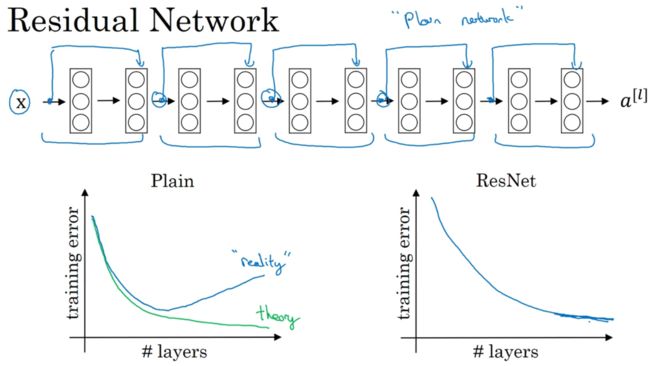
没跳跃前为普通网络(Plain network)
如图左,普通神经网络,现实中往往先好,然后再坏;而理论应该一直好。
如图右,ResNet中,即使网络再深,训练表现不错。
四、残差网络为什么有用(Why ResNets work?)
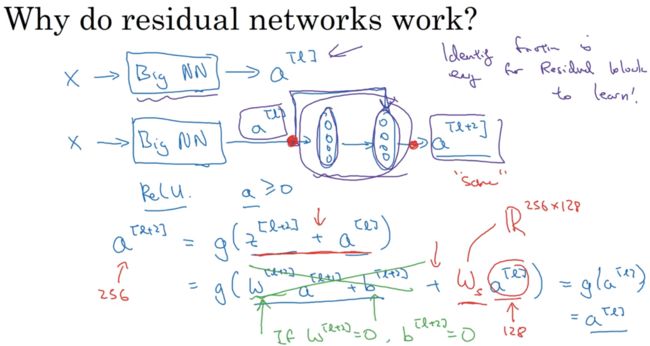
训练ResNets,假设一大型神经网络,输入x,输出a[l],如图上,再添加两层,如图下。假设整个网络使用Relu函数,激活值大于等于0。
假设w和b为0,z便没有了。a[l+2]=a[l]。
不仅要保持网络的效率,还要提升它的效率。ResNets使用了很多same卷积,使得a[l]维度和z[l+2]的维度相等。输入输出维度不同时,增加W,维度为256x128,维度便相同了,网络通过学习能得到合适的W。
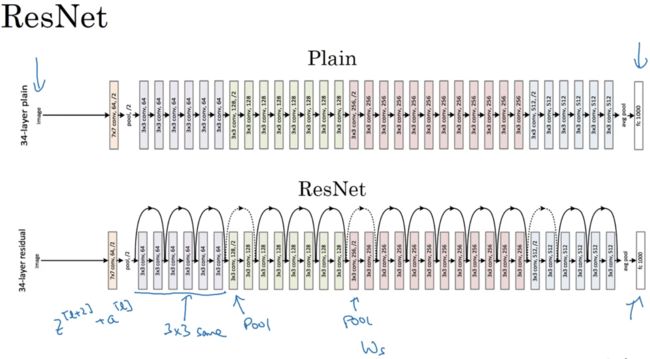
如图Plain,有多个卷积层,最后输出一个softmax。
如图ResNets,只需在Plain中添加跳跃连接,便成为ResNets。
五、网络中的网络以及1x1卷积(Network in Network and 1x1 convolutions)

过滤器为1x1,使用32个。对6x6用途不大,但对6x6x32的卷积效果更好,其计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用ReLu非线性函数。输出为6x6x过滤器数量。
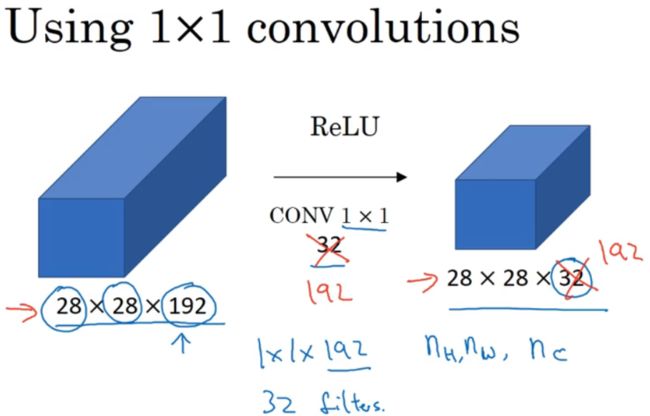
input:28x28x192,使用卷积层,32个1x1x192的过滤器,压缩了通道数。
NIN就是给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变。
六、谷歌Inception网络简介(Inception network motivation)
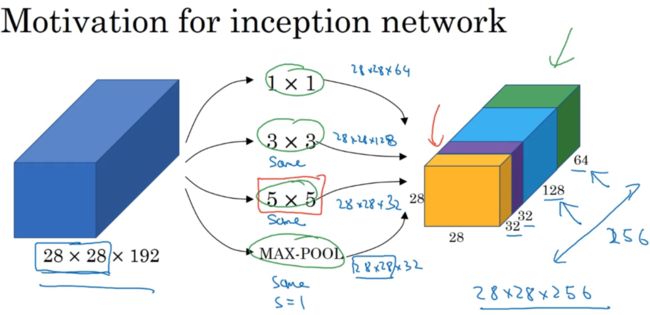
构建卷积层时,要决定过滤器大小,或加不加池化层。而Inception的作用是帮助你做决定。
若为1x1卷层,输出结果为28x28x64;使用3x3;使用5x5;使用池化,为匹配维度加入padding。
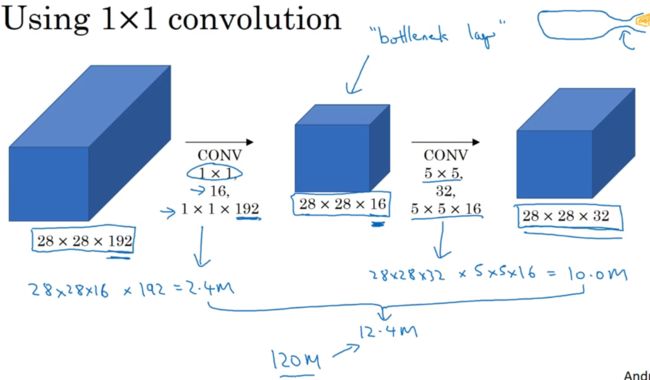
1.第一个架构(只有右半部分)32个5x5过滤器,5x5x192 乘以 28x28x32,约为1.2亿。
2.另一个架构输入28x28x192,输出为28x28x32。使用1x1卷积把输入值从192个通道减少到16个通道,然后对较小的层使用5x5。中间层称为瓶颈层(bottleneck lag)。
接下来看看计算成本:
28x28x16层的计算成本为28x28x16x192约为240万。
第二个卷积层,28x28x32 乘以 5x5x16 约为1000万。
计算成本即为两层之和。与第一个架构比较,成本下降到了原本的十分之一。
七、Inception网络(Inception network)
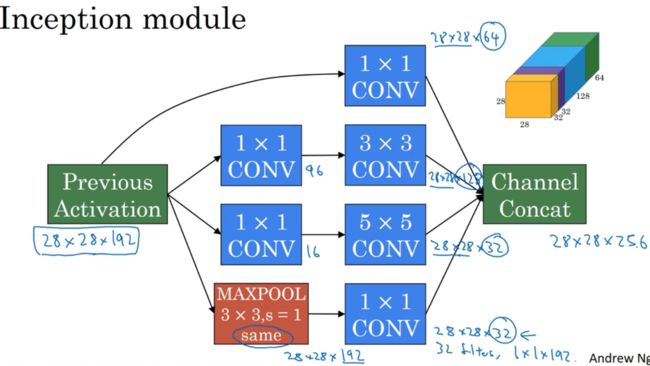
Inception模块会将之前层的激活或者输出作为它的输入,然后先通过一个1x1的层,再通过一个5x5的层。还有其他等类似操作。
为了最后将输出连接起来,使用same类型的padding来池化,进行最大池化时,输出将是和输入层一样,实际上加上一个1x1的卷积层,通道将缩小。
最后组合在一起,得到28x28x256。
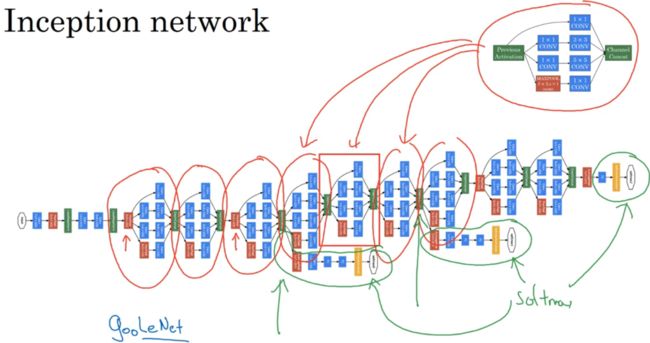
如图有多个Inception模块,有些输入中多加个池化层修改高和宽的维度。
论文中除了如上所述的Inception模块中的,还多了一个全连接层,最后softmax输出。可看成是其一个细节,确保了即便是隐藏单元和中间层也参与了特征计算,并防止了过拟合。
Inception Network 被称为GoogleLeNet,向LeNet致敬。
八、使用开源的实现方案(Using open-source implementations)
很多神经网络复杂细致难以复制,参数调整的细节问题。通过github找源码。
九、迁移学习(Transfer Learning)

假设构建一个猫咪检测器,现在判断猫是Tigger还是Mity还是都不是。
当包含上述猫的图片较少时,训练集会很小,可以从网上下载一些神经网络开源的实现,代码权重都下载下来。例如:ImageNet数据集有1000个不同类别,会有一个softmax激活。可以去掉softmax层,创建自己的softmax层,用来输出三类。可以把所有层看作是冻结的,只需训练和自己softmax层相关的参数。会有trainableParameter=0的参数,不训练这些参数,会有freeze=1的参数。
第二种技巧,由于前面的层都冻结了,可把输入图像X映射到softmax前一层,计算特征或激活值,然后存到硬盘,然后在此之上训练softmax分类器,存到硬盘优点是不需要每次遍历训练集。
若有较多猫图,1.应冻结更少的层,训练后边的层,建立自己的分类器。2.同样可以取后边几层权重,用作初始化,然后梯度下降。3.可直接去掉后几层,换成自己的隐藏单元和softmax输出层。数据越多,冻结层就越少。
若有大量猫图,用开源的网络和权重用作初始化训练,softmax改为自己的。
十、数据增强(Data augmentation)
1.首先最简单的方法是垂直镜像对称(Mirroring)。
2.接着是随机裁剪(random cropping)。
3.还可用旋转,剪切,扭曲变形引入局部弯曲…
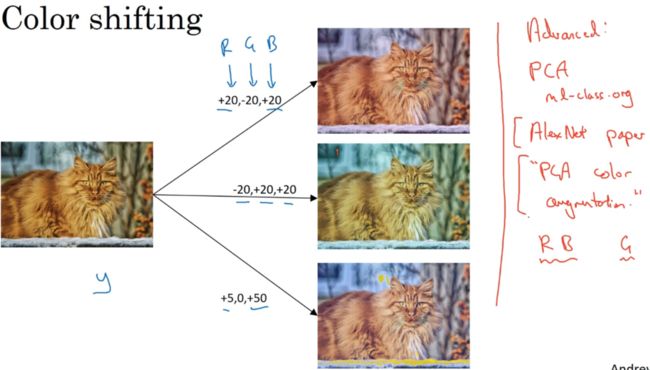
彩色转换,给R、G、B三个通道加上不同的失真值。实践中可根据某种概率分布来决定。
对RGB有不同的采样方式,1.影响颜色失真的算法PCA,若图中红蓝多,绿色少,PCA颜色增强算法对红蓝增减很多,绿色变化相对少。
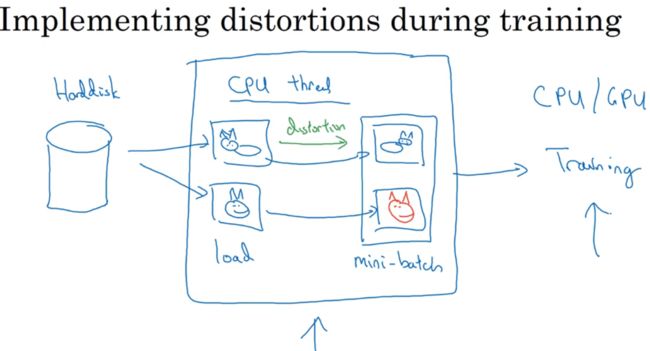
可能有存好的数据在硬盘上,有小数据集可以做任何事情,数据集够用了。
若有较大的训练集,可能用CPU线程,不停从硬盘读数据,可用CPU线程实现变形失真。与此同时,CPU线程持续加载数据,然后实现失真变形,从而构建批数据,数据持续输出到其他线程或进程,开始训练,可在CPU或GPU上训练。
十一、计算机视觉现状(The state of computer vision)
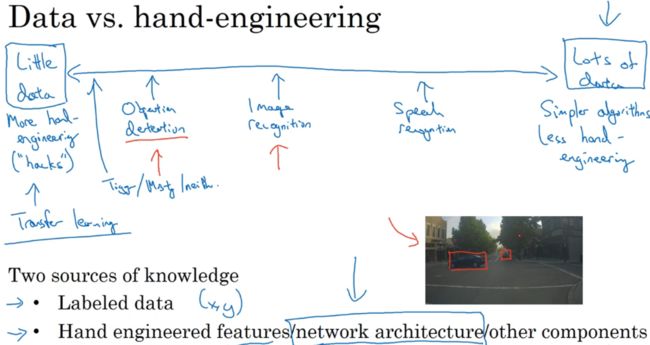
可认为大部分机器学习问题是结余少量数据和大量数据范围之间的,如语音识别、图像识别或分类、目标检测。
当有很多数据时,倾向更简单的算法和更少的手工工程。没那么多数据时,则相反。
我们的学习算法有两种知识来源:
1.被标记的数据
2.手工工程
有少量数据时,迁移学习会有很多帮助。

基准测试的小技巧:
1.集成,想好NN后,可独立训练几个NN,并平均输出。可能要从3-15个不同网络中运行一个图像。
集成要保持所有不同神经网络,占用了更多的计算机内存。
2.Multi-crop at test time,将数据增强应用到测试图像中,去中心的crop,再取四个角落的crop,如图会有10种不同图像的crop,叫做10-crop。

1
深度学习-吴恩达 ↩︎