基于秘密共享和压缩感知的通信高效联邦学习
论文链接:基于秘密共享和压缩感知的通信高效联邦学习 - 中国知网
摘要:
面临情况:隐私数据保护,联邦学习下共享梯度仍然会泄漏,联邦学习高通信代价
解决方案:
1、Top-k稀疏及压缩感知技术:减少梯度传输的通信开销
2、安全多方计算的加法秘密共享:对重要梯度测量值加密,减少通信开销增强安全性
二者区别:客户端和服务器通信时传递的分别是梯度测量值与梯度测量值的量化结果
为防止梯度泄漏而使用的技术:
差分隐私(DP):平衡模型精确度及隐私保护
同态加密(HE):计算及通信代价高
安全多方计算(MPC):通信消耗
梯度压缩:
联邦学习中,服务器和本地客户端需要多次上传、下发,中间的参数(梯度)是主要的通信
梯度压缩机制:(1)梯度稀疏 (2)梯度量化 (3)梯度压缩感知
梯度稀疏:
(1)确定阈值,只传输大于阈值的梯度给服务器
(2)将梯度进行排序,仅传输前P%的梯度给服务器
存在的问题:只对上传的梯度进行处理,未对下发的全局模型梯度处理
梯度量化:可以压缩上传和下发的通信量
(1)1比特量化:客户端只需要上传局部模型梯度的符号给服务器
(2)稀疏三元化压缩:在梯度传输前通过稀疏、三元化及编码方式对梯度压缩
梯度压缩感知:
满足一定条件的测量矩阵将稀疏或可压缩的高维信号投影到低维空间,求解一个优化问题高概率恢复信号
李刚教授:Communication-Efficient Federated Learning Based on Compressed Sensing将压缩感知应用于联邦学习中,每一轮训练均包含2阶段,2个阶段都需要客户端与服务器交互,会产生额外的通信负担,将压缩测量值直接传给服务器,会有泄漏信息的风险s
基于压缩感知和安全多方计算,针对联邦学习中通信开销、隐私泄漏、设备资源有限提出2个算法:ICFM算法和ICFM_1bit算法
ICFM算法客户端上传是被部分加密后的压缩测量值
ICFM_1bit算法上传是压缩测量值量化后再部分加密结果

ICFM算法:

ICFM_1bit算法:

实验:
对ICFM和ICFM_1bit算法性能进行分析
数据集:使用MNIST和Fashion-MNIST数据集对图像分类任务精确度测量、评估通信开销
对比算法:CS_FL ,CS_FL_1bit
基线算法:FedAvg,SignSGD
传给服务器数据为梯度测量值或原始梯度值:ICFM、CS_FL、FedAvg
传给服务器数据为梯度测量值或原始梯度值的1比特量化数据:CS_FL_1bit、SignSGD
模型:CNN模型,6层网络模型,2层卷积层、2层池化层、2层全连接层,卷积核大小5*5
考虑独立同分布和非独立同分布情况下算法性能,稀疏等级l=0.05 压缩率samplerate=0.1
假设100个客户端,通过frac的值调节参与迭代计算的客户端的数量,采用0.5SGD优化器
实验结果:
1、MNIST数据集,客户端参与率0.3
独立同分布情况下:(右边为左图的放大部分)

FedAvg:传输梯度原始数据,未对数据压缩量化,分类精度最高99.96
SignSGD:精度最低,96.96,(可能未对数据预处理而粗暴量化)
CS_FL_1bit与ICFM_1bit分类精度、收敛速度接近
ICFM收敛速度稍快于CS_FL,收敛精度高0.2
ICFM_1bit比CS_FL_1bit高0.12
非独立同分布情况下:

FedAvg:精度最高、收敛速度最快
ICFM比CS_FL收敛速度稍快精度高0.12
ICFM_1bit远好于CS_FL_1bit精度高1.2
CS_FL_1bit震荡大,比SignSGD高2.7
ICFM_1bit前期收敛速度略低于ICFM,最后精度收敛值几乎相同且精度收敛值非常接近基线FedAvg
结论:ICFM_1bit在MNIST的非独立同分布情况下能在通信代价更低的情况下保证分类精度于IVFM算法及FedAvg相差不多
2、Fashion-MNIST数据集,客户端参与率0.3
独立同分布情况下:
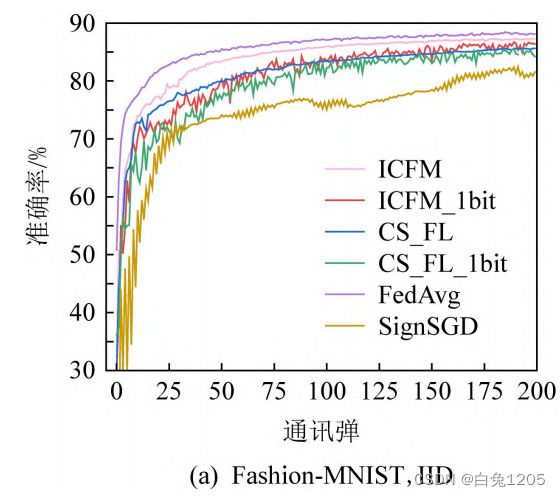
FedAvg:精度及收敛速度最快
ICFM:仅次于FedAvg,精度相差0.8
ICFM比CS_FL收敛速度快,精度高1.8
ICFM_1bit比CS_FL_1bit收敛速度快,精度高1.2
SignSGD:收敛速度最慢精度最低
非独立同分布情况下:
ICFM、CS_FL、FedAvg比较:(non-IID)

ICFM前期收敛速度快于CS_FL,精度高于1.3
ICFM_1bit、CS_FL_1bit、SignSGD比较:(non-IID)
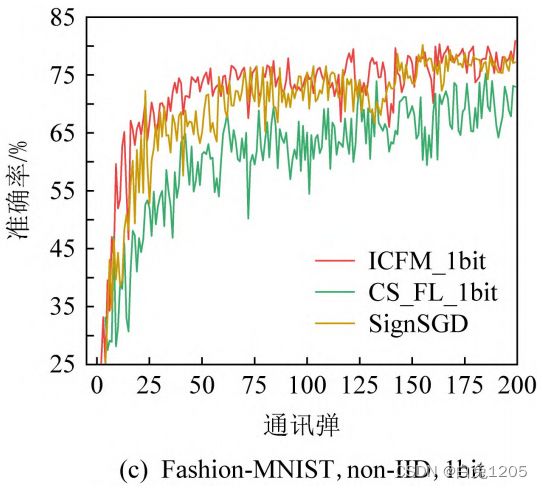
算法振幅比较大,ICFM_1bit优于CS_FL_1bit和SignSGD
MNIST不同参与率情况下:
独立同分布情况下:(不同算法在不同参与率情况下测试精度最大值)

从参与率0.1上升到0.3时,除了SignSGD,其它算法精度都提升,对CS_FL_1bit影响最大,上升4.7
非独立同分布情况下:(不同算法在不同参与率情况下测试精度最大值)
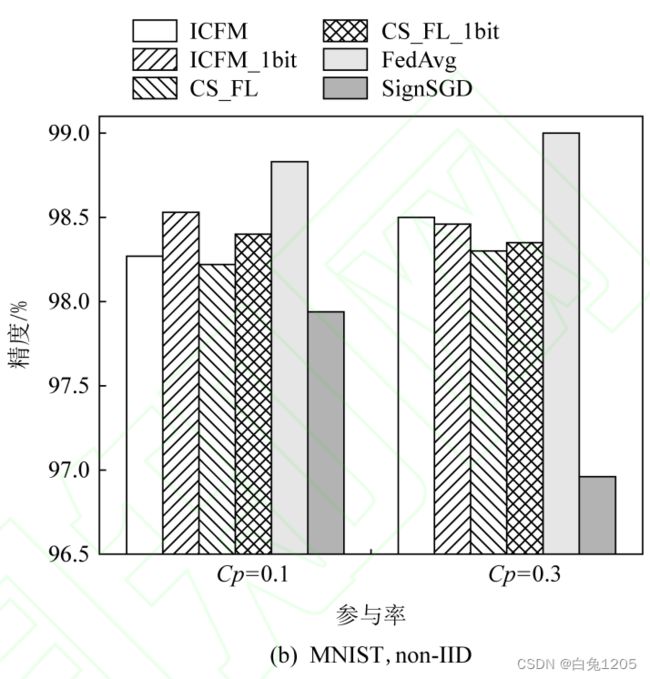
从参与率0.1上升到0.3时,ICFM、CS_FL、FedAvg精度增加,ICFM_1bit、CS_FL_1bit、SignSGD精度下降
结论:在非独立同分布情况下,参与率0.1更适合1比特类型算法
通信效率实验:
通信消耗对象:参与通信的客户端数量、模型参数个数、执行算法本身
使用6层CNN网络与VGG16网络测试不同算法下通信消耗:
6层CNN网络:

FedAvg传输原始梯度(没有经过压缩量化)通信消耗呈指数性增长
结论:ICFM未加安全性时比CS_FL高效,增加安全性后通信消耗也可接受;ICFM_1bit随着参与者个数增加比CS_FL_1bit通信消耗更少,效率更高
ICFM与ICFM_1bit在每轮训练只需要与服务器交互一次,CS_FL_1bit需要交互两次,可以用更少的额外通信消耗获得更强安全性
VGG16网络下通信消耗:
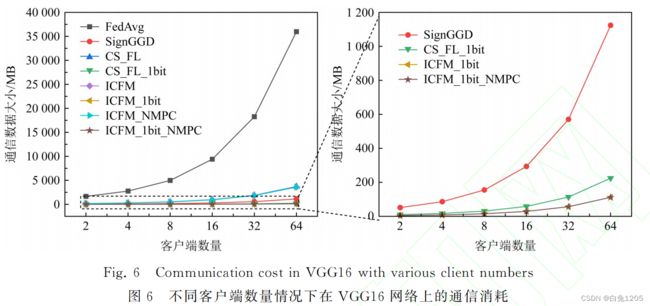
结论:在VGG16下网络通信效率更高