Redis Pipeline实战及序列化问题避坑,Redis List,Set实战,缓存需要更新怎么解决缓存击穿?一文带你进阶Redis使用!
前言
注:
大家好我是妈妈的好大儿,
笔者联系方式
QQ:3302254385
微信:yxc3302254385
交个朋友!
文章内容很多不想看业务场景的,可以直接通过目录找到需要的代码cv!
创作不易,三连十分感谢!!!
业务场景分析
先从业务场景说起:
类似于下图的这种小程序,投票排行榜的场景!!!
先进行分析
- 第一能够投票的爱豆很多,切需要排名
- 第二对于用户的投票数据的需要进行统计,通常并发很高
- 第三用户使用这个小程序,一进来的主页面就是这个排行榜,作为一个访问量很高的热点数据
技术解决方案
根据分析的业务场景我们应该使用什么技术解决方案更好,会产生什么问题呢!!
- 对于这种投票的场景其实数据的实时性是要求不高的,我们可以使用缓存全盘替代我们的数据库,因为1.并发高,访问量大的特点,不可能使用数据库直接去进行查询和同步更新,单机必炸!!!2.使用缓存节省数据库成本3.缓存速度快
- 由于我们使用缓存来全盘代替数据库,需要将爱豆点赞数,爱豆排行榜,用户的点赞记录等!!!将缓存数据异步更新到数据库或异步将数据库数据更新到缓存
更新爱豆点赞数:
我们可以去使用Redis中的ZSet通过她的权重系数(点赞量)进行爱豆的排名,每次用户点赞只需要去增加缓存中的这个权重系数即可,然后再将这个(点赞量定时更新到数据库)
更新爱豆排行榜:
因为爱豆的基本信息可能会存在修改,但是爱豆的点赞数是通过缓存去统计的,所以先点赞量更新到数据库,再将数据库的数据排序更新到缓存中!
查询全部爱豆排行数据,将数据放在Redis中的List类型通过我们的range方法和分页算法去取出数据!
更新用户的点赞记录
一.每个用户都会有自己的点赞票数,且每日刷新,对于点赞的这个事件,一般用户都是在一分钟只能完成所有的票数投递的!!所以在扣减用户的每日票数时,也可以使用缓存作为票数扣减而不必用户点赞10次就查询10次数据库!!
二.对于用户的每条点赞操作都会有所记录,当高峰期进行数据库插入操作是完成没有必要的,我们可以把数据放入缓存,作为一个中间件一样,对流量进行削峰,然后再批量,写入到数据库中!可以使用Redis的List作为一个双端队列,FIFO(先进先出)的形式批量的刷回到我们的数据库中! - 那么数据在更新的过程中,缓存失效了导致缓存击穿怎么办?要是直接打到我们数据库会导致db挂掉(采用缓存副本的方式,或者也可以进行限流,只有一个线程可以访问数据库并更新缓存使用JUC包下的Semaphore)
- 对于大批量的缓存操作,不单单只是我们存个简单的token这样的key,value那么简单,那么多数据怎么一次性或者批量写入到我们的缓存中,来节省类似于连接的这种不必要的耗时(使用Pipeline管道进行优化,来减少服务器连接中消耗的资源和时间,也就是减少)
Redis知识回顾Or补充
为了帮助大家回顾知识点,也为了帮助小白理解,就不涉及到具体的命令了!!!主要是数据结构和使用场景
List
- 单值多Value,有序集合,不唯一
- 它是一个字符串链表,left,right 都可以插入添加
- 如果键不存在,创建新的链表,如果值全移除,对应的键也就消失
- 使用Lists结构,我们可以轻松地实现最新消息排行等功能。List的另一个应用就是消息队列,可以利用List的PUSH操作,将任务存在List中,然后工作线程再用POP操作将任务取出进行执行。
- Redis的list是每个子元素都是String类型的双向链表,可以通过push和pop操作从列表的头部或者尾部添加或者删除元素,这样List即可以作为栈,也可以作为队列

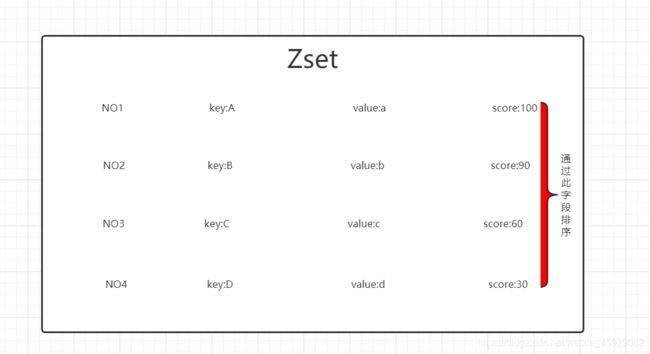
ZSet
- 与集合一样,排序集合由唯一的、不重复的字符串元素组成,类似于Set和Hash之间的混合
- 虽然集合内的元素不是有序的,但有序集合中的每个元素都与一个称为score的浮点值相关联,(这就是为什么该类型也类似于散列,因为每个元素都映射到一个值)。
- ZADD类似于SADD,但是有一个额外的参数(放置在要添加的元素之前),即分数。ZADD也是可变的,因此您可以自由指定多个得分-值对
- 排序集是通过一个双端口数据结构实现的,其中包含一个跳跃表和一个哈希表,所以每次我们添加一个元素,Redis执行O(log(N))操作。这很好,但当我们要求排序的元素时,Redis根本不需要做任何工作,它已经全部排序了
Pipeline
Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。
这意味着通常情况下一个请求会遵循以下步骤:
客户端向服务端发送一个查询请求,并监听Socket返回,通常是以阻塞模式,等待服务端响应。
服务端处理命令,并将结果返回给客户端。
因此,例如下面是4个命令序列执行情况:
Client: INCR X
Server: 1
Client: INCR X
Server: 2
Client: INCR X
Server: 3
Client: INCR X
Server: 4
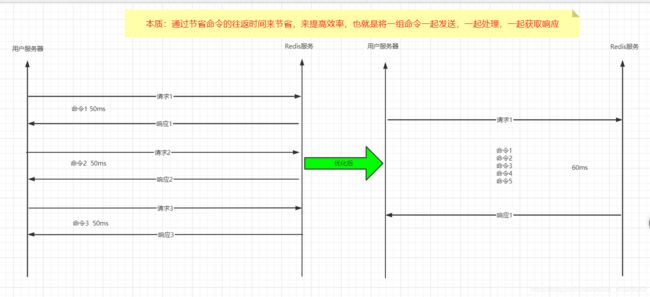
客户端和服务器通过网络进行连接。这个连接可以很快(loopback接口)或很慢(建立了一个多次跳转的网络连接)。无论网络延如何延时,数据包总是能从客户端到达服务器,并从服务器返回数据回复客户端。
这个时间被称之为 RTT (Round Trip Time - 往返时间). 当客户端需要在一个批处理中执行多次请求时很容易看到这是如何影响性能的(例如添加许多元素到同一个list,或者用很多Keys填充数据库)。例如,如果RTT时间是250毫秒(在一个很慢的连接下),即使服务器每秒能处理100k的请求数,我们每秒最多也只能处理4个请求。
如果采用loopback接口,RTT就短得多(比如我的主机ping 127.0.0.1只需要44毫秒),但它任然是一笔很多的开销在一次批量写入操作中。幸运的是有一种方法可以改善这种情况。
Redis 管道(Pipelining)
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多POP3协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
Redis很早就支持管道(pipelining)技术,因此无论你运行的是什么版本,你都可以使用管道(pipelining)操作Redis。下面是一个使用的例子:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379
+PONG
+PONG
+PONG
这一次我们没有为每个命令都花费了RTT开销,而是只用了一个命令的开销时间。
非常明确的,用管道顺序操作的第一个例子如下:
Client: INCR X
Client: INCR X
Client: INCR X
Client: INCR X
Server: 1
Server: 2
Server: 3
Server: 4
重要说明:
使用管道发送命令时,服务器将被迫回复一个队列答复,占用很多内存。所以,如果你需要发送大量的命令,最好是把他们按照合理数量分批次的处理,例如10K的命令,读回复,然后再发送另一个10k的命令,等等。这样速度几乎是相同的,但是在回复这10k命令队列需要非常大量的内存用来组织返回数据内容。
管道(Pipelining) VS 脚本(Scripting)
大量 pipeline 应用场景可通过 Redis 脚本(Redis 版本 >= 2.6)得到更高效的处理,后者在服务器端执行大量工作。脚本的一大优势是可通过最小的延迟读写数据,让读、计算、写等操作变得非常快(pipeline 在这种情况下不能使用,因为客户端在写命令前需要读命令返回的结果)。
应用程序有时可能在 pipeline 中发送 EVAL 或 EVALSHA 命令。Redis 通过 SCRIPT LOAD 命令(保证 EVALSHA 成功被调用)明确支持这种情况。
(ZSet,Lits)实现用户点赞功能
注:
这里有一个基于ip地址限速的注解:IpInterceptor,具体实现查看我这篇博文!
Java接口限速器—>注解与反射,枚举,AOP拦截器,异常处理中心,Redis实战
/**
* 用户点赞操作
* @param likeUserOpenId 点赞的爱豆id
* @param userSession 基于小程序用户的opendId生成第三方session令牌
* @return
*/
@IpInterceptor(requestCounts = 20,expiresTimeSecond = 60,isRestful = true,restfulParamCounts = 2)
@GetMapping("/userLikeDemo/{userSession}/{likeUserOpenId}")
public Result userLikeDemo(@PathVariable("likeUserOpenId") String likeUserOpenId,@PathVariable("userSession")String userSession) {
//1.获取用户当前的身份 通过3rdsession从redis中置换出当前报名用户的OpenId
String openId = (String)redisUtil.get(userSession);
if(SuperUtil.isNullOrEmpty(openId)){
return Result.handelLose("用户身份异常!!!",200);
}
//进行点赞操作
boolean clickFlag = userService.userLikeDemo(openId, likeUserOpenId);
//代表点赞成功
if(clickFlag){
return Result.handelSuccess("点赞成功");
//代表点赞失败
}else {
return Result.handelLose500("点赞失败,没有票数了");
}
}
//--------------------------------------------------------------------------------------------------------------
/**
* 用户点赞功能实现
* 1.通过userOpenId查看用户是否还有点赞的次数
* 2.如果有,给此likeUserOpenId用户点赞
* 3.并且生成点赞记录
* @param userOpenId
* @param likeUserOpenId
* @return true点赞成功 false点赞失败,没有票数
*/
@Override
public boolean userLikeDemo(String userOpenId, String likeUserOpenId) {
//初始参数准备
//记录标志 true减的是默认的票数 false减的是购买的票数
boolean recordFlag = true;
//是否有票数的标志位
boolean hasCountFlag=true;
//.先查询redis中 是否存在此用户的点赞次数
Integer defaultCount = (Integer) redisUtil.hget(USER_LIKE_COUNTS_PREFIX + userOpenId, "DEFAULT");//默认的点赞次数
Integer buyCount = (Integer) redisUtil.hget(USER_LIKE_COUNTS_PREFIX + userOpenId, "BUY"); //刷礼物的点赞次数
//如果缓存中没有数据
if (SuperUtil.isNullOrEmpty(defaultCount) || SuperUtil.isNullOrEmpty(buyCount)) {
//1.那么就根据用户编号,先查询数据库
User user = userMapper.selectOne(new QueryWrapper<User>().eq("user_open_id", userOpenId));
//2.判断用户 是否有默认的票数?使用默认票数:使用购买票数
if (user.getUserDefaultLikeCount() >= 1) {
//使用默认票数-1
user.setUserDefaultLikeCount(user.getUserDefaultLikeCount() - 1);
} else if (user.getUserBuyLikeCount() >= 1) {
//使用购买的票数-1
user.setUserBuyLikeCount(user.getUserBuyLikeCount() - 1);
recordFlag = false;
} else {
hasCountFlag=false;
}
//3.把数据写回到 redis中设置30分钟过期
redisUtil.hset(USER_LIKE_COUNTS_PREFIX + user.getUserOpenId(), "DEFAULT", user.getUserDefaultLikeCount(), 30 * 60);
redisUtil.hset(USER_LIKE_COUNTS_PREFIX + user.getUserOpenId(), "BUY", user.getUserBuyLikeCount(), 30 * 60);
//代表没有票点赞失败 等到缓存加载成功直接return
if(!hasCountFlag){
return false;
}
//代表用户的数据在缓存中有
} else {
//因为点赞功能是基于redis实现的,用户的点赞数会有半小时的失效期,这个失效期也就是帮助我们,将用户的点赞记录刷回到数据库中保证数据库和缓存的一致性
//但是如果用户卡bug,等待到最后一分钟,进行点赞,但是我们缓存中的点赞数据还没有更新到数据库中,数据库的数据又代替了缓存中的数据就会导致 多投的问题
//所以我们每次点赞是重新刷新缓存的过期时间 保证最后一次点赞都能有半小时的时间给我们把数据刷回到数据库中
//1.刷新缓存时间
redisUtil.expire(USER_LIKE_COUNTS_PREFIX+userOpenId,30*60);
//2.判断用户 是否有票数
if (defaultCount >= 1) {
//使用默认票数-1
redisUtil.hdecr(USER_LIKE_COUNTS_PREFIX + userOpenId, "DEFAULT", 1);
recordFlag = true;
} else if (buyCount >= 1) {
//使用购买的票数-1
redisUtil.hdecr(USER_LIKE_COUNTS_PREFIX + userOpenId, "BUY", 1);
recordFlag = false;
} else {
//直接返回没有票数
return false;
}
}
//END 如果成功减了票数才会 将用户的点赞操作记录插入到redis(List)列表中
StringBuilder record=new StringBuilder(userOpenId).append("_").append(likeUserOpenId).append("_").append((recordFlag)?1:2);
//刷新爱豆票数
redisTemplate.opsForZSet().incrementScore(USER_LIKE_PREFIX,likeUserOpenId,1);
//将点赞记录推送到缓存中
redisUtil.lLeftPush(LIKE_RECORED_PREFIX,record);
return true;
}
(List,Pipeline避坑)实现用户点赞数据同步
注:
这里需要通过缓存中的点赞记录,计算用户使用的点赞数,并将用户的点赞记录和点赞数进行数据库同步更新!
在使用Pipeline执行命令集前,有一个很坑的点,也就是关于序列化的问题,在不配置redisTemplate的序列化方式时很容易出错!!
让我们看一下redisTemplate的源码,默认加载的是JdkSerializationRedisSerializer

在不设置序列化方式,使用默认的序列化方式时!使用FastJson反序列化对象时会报错!
org.springframework.data.redis.serializer.SerializationException: Could not deserialize: syntax error, pos 1, line 1, column 2sb; nested exception is com.alibaba.fastjson.JSONException: syntax error, pos 1, line 1, column 2sb
at com.alibaba.fastjson.support.spring.FastJsonRedisSerializer.deserialize(FastJsonRedisSerializer.java:67)
at org.springframework.data.redis.core.RedisTemplate.deserializeMixedResults(RedisTemplate.java:617)
at org.springframework.data.redis.core.RedisTemplate.lambda$executePipelined$1(RedisTemplate.java:335)
at org.springframework.data.redis.core.RedisTemplate.execute(RedisTemplate.java:228)
at org.springframework.data.redis.core.RedisTemplate.execute(RedisTemplate.java:188)
at org.springframework.data.redis.core.RedisTemplate.execute(RedisTemplate.java:175)
at org.springframework.data.redis.core.RedisTemplate.executePipelined(RedisTemplate.java:324)
at org.springframework.data.redis.core.RedisTemplate.executePipelined(RedisTemplate.java:314)
在使用Pipeline执行命令集的时候,如果命令有各种返回值,建议使用StringRedisSerializer序列化方式不然也会导致序列化问题,如下列子所示
List<Object> resultList = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
connection.lRange("USER_LIST".getBytes(),0,-1);
connection.set("cc".getBytes(),"test".getBytes());
connection.get("cc".getBytes());
connection.set("user".getBytes(),JSON.toJSONBytes(new User().setUserOpenId("6666").setUserCity("上海")));
return null;
}
});//这里一定要用String的序列化 因为会存在很多的返回结果 因此统一将结果按照String处理

好啦!开始我们正式的项目实战代码!!
/**
* 每分钟都会同步 用户的点赞记录和剩余票数到数据库中
*/
@Scheduled(cron = "0 0/1 * * * ?")
public void synLikeRecordDemo(){
//用于存储点赞记录批量新增的集合
List<LikeRecord> likeRecordList=new LinkedList<LikeRecord>();
//统计用户各种点赞数的使用情况
Map<String,Integer> map = new HashMap(256);
//统计当前哪些用户使用了点赞数 用户解析对象
Set<String> userOpenIdSet = new HashSet(128);
//批量修改的集合
List<User> userCountList = new LinkedList<User>();
//更新 投票记录
executorService.execute(()->{
//需要访问的Redis key
byte[] key =LIKE_RECORED_PREFIX.getBytes();
log.info("-----------------------------------------------------------------------更新投票记录,以及用户的剩余票数-----------------------------------------------------------------------");
//总共循环的次数外循环一次(执行一次Pipelined) 内循环100次
int allLoopCount=0;
//最后一次 内循环的次数(执行一次Pipelined,里面包含的命令集)
int endInnerLoopCount=100;
//1.查询出当前队列的长度
Long listSize = redisTemplate.opsForList().size("test_list");
//2.计算外循环的次数,和最后一次内循环的次数 每次最多执行1000条命令
if(listSize>=1000){
allLoopCount=10;
}else{
endInnerLoopCount=(int)(listSize%100);
endInnerLoopCount=(endInnerLoopCount==0)?100:endInnerLoopCount;
allLoopCount=(int)Math.ceil(listSize / 100.0);
}
for (int i = 1; i <=allLoopCount ; i++) {
//内循环的次数默认100 当外到最后一次时,根据上面的计算数据,最后一次的循环次数进行循环
AtomicInteger innerLoopCount=new AtomicInteger(100);
if(i==allLoopCount){
innerLoopCount.set(endInnerLoopCount);
}
//3.开启Pipelined执行命令 执行命令的返回结果都在--->pipelinedList
List<Object> pipelinedList = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
//执行多个取出数据的命令
for (int j = 1; j <= innerLoopCount.get(); j++) {
connection.listCommands().rPop(key);
}
//这里一定要返回null,最终pipeline的执行结果,才会返回给最外层
return null;
}
//这里一定要用String的序列化 因为会存在很多的返回结果 因此统一将结果按照String处理
},new StringRedisSerializer());
//4.处理数据
pipelinedList.forEach(item->{
String[] params =String.valueOf(item).split("_");
//解析出用户到底是用默认的还是购买的票数 1是默认票数 2是礼物赠送的票数
Integer likeType=Integer.parseInt(params[2]);
//生成点赞记录对象并,添加到批量修改的集合中
likeRecordList.add(new LikeRecord().setClickUserOpenid(params[0]).setLikeUserOpenid(params[1]).setIsDefault(Integer.parseInt(params[2])));
//--------------------------------计算每个用户使用的票数,以及分别使用了哪些票数--------------------------------------
//将用户的id存入到set中 用户计算那些用户的票数是需要修改的
userOpenIdSet.add(params[0]);
//计算用户点赞使用的票数类型以及是哪个用户的 key key=用户ID+用户的点赞类型
StringBuilder hashKey =new StringBuilder(params[0]).append("_") .append((likeType == 1) ? "default" : "buy");
//根据hashKey来获取,已经计算的票数
Integer userUseCount = map.get(hashKey);
//如果为空,代表第一次统计,此用户的点赞数
if(SuperUtil.isNullOrEmpty(userUseCount)){
//.将用户的key和count点赞数 存入到map中
map.put(hashKey.toString(),1);
}else {
//.此条记录不是用户第一次点赞 叠加点赞次数
userUseCount++;
map.put(hashKey.toString(),userUseCount);
}
});//处理管道数据end
}//最外层循环
//解析出具体某个用户 点赞数,以及分别使用了哪些票数
if(!userOpenIdSet.isEmpty()){
userOpenIdSet.forEach(userOpenId->{
//根据用户的编号 分别解析出对应使用的票数
Integer defaultCount = map.get(userOpenId + "_default");
Integer buyCount =map.get(userOpenId+"_buy");
//将对应的用户编号 和用户分别使用的票数 存入到对象中 再存入到需要修改的集合中
userCountList.add( new User().setUserOpenId(userOpenId).setUserDefaultLikeCount(defaultCount).setUserBuyLikeCount(buyCount));
});
}
//点赞记录批量插入到数据库
if(!likeRecordList.isEmpty()){
likeRecordService.saveBatch(likeRecordList,likeRecordList.size());
}
//更新用户使用的点赞数
if(!userCountList.isEmpty()){
userMapper.upadateUserCountByOpenId(userCountList);
}
});//子线程end
}
(Zset)实现爱豆票数同步
同步缓存中ZSet的爱豆票数,到数据库!
/**
* 每隔4分钟半,同步选手点赞数
*/
@Scheduled(cron = "0/30 0/4 * * * ?")
public void synUserRanking(){
//用户存储更新用户 点赞数据集合
List<User> userList = new LinkedList<>();
//创建子线程 执行任务
executorService.execute(()-> {
System.out.println("-----------------------------------------------------------------------同步选手点赞数-----------------------------------------------------------------------");
//1.从redis中 取出全部选手点赞数从set里 以及 选手的OpenId
Set<ZSetOperations.TypedTuple<Object>> userLikeSet = redisTemplate.opsForZSet().rangeWithScores("USER_LIKE", 0, -1);
//2.如果set集合不为空 那么进行遍历取值
if (SuperUtil.notNull(userLikeSet)) {
//3.将对应的用户编号 和 点赞数遍历出来存入到User对象中 再存入到集合中等待统一的修改
for (ZSetOperations.TypedTuple<Object> typedTuple : userLikeSet) {
userList.add(new User().setUserOpenId((String) typedTuple.getValue()).setUserLike(new BigInteger(String.valueOf(typedTuple.getScore().intValue()))));
}
}
//4.end 最后值将选手点赞数 批量修改到数据库
if (!userList.isEmpty()) {
userMapper.updateBatchByOpenId(userList);
}
});
}
(List)实现爱豆列表查询,更新,缓存需要更新怎么解决缓存击穿?
第一点 保证用户全部访问的是缓存并定时更新缓存,但缓存不被击穿
大家还记得我们初学Java都会遇到的一道小列题吗?
/**
*现在有变量int a=6; int b=10;交换2个变量值!!!
*/
public static void exchangeNumber(int a,int b){
int c=0;
c=a;
a=b;
b=c;
System.out.println(a+"--"+b);
}
public static void main(String[] args) {
exchangeNumber(6,10);
}
我们一般都会使用一个中间变量,来进行交换!!!
这里我的解决思路也是基于这样的一个中间变量!!!
1.我们把数据加载到缓存加载2份不设置过期时间,在我们更新缓存的时候,先删除第一份缓存,直到第一份缓存更新成功,再删除第二份缓存,并更新第二份缓存
2.用户请求时先查询第一份缓存,由于缓存需要更新,在加载数据和更新时存在的空档时间,于是我们去访问第二份缓存,由于它是不失效的,就可以保证不管多少用户线程我们走的都是缓存数据,不存在缓存空档期导致穿透!
用户读取数据具体实现:
/**
* 查询用户列表 根据点赞排名
* @param pageIndex 当前页码
* @return
*/
@GetMapping("/userMatchData/{pageIndex}")
public Result userMatchData(@PathVariable("pageIndex")Long pageIndex ){
Long pageStart=(pageIndex-1)*10;
Long pageEnd=(pageIndex*10)-1;
//首先判断缓存中是否有数据
if(redisUtil.hasKey("USER_LIST")){
//1.从缓存中查询出此数据
List user_list = redisTemplate.opsForList().range("USER_LIST", pageStart, pageEnd);
//2.将结果返回到前端
return Result.handelSuccess("查询用户排行榜成功",user_list);
//没有 走缓存副本查询
}else {
List user_list_copy = redisTemplate.opsForList().range("USER_LIST_COPY", pageStart, pageEnd);
//2.将结果返回到前端
return Result.handelSuccess("查询用户排行榜成功",user_list_copy);
}
}
更新缓存时,采用类似自旋锁的方式,保证缓存必须更新完成,才能释放掉副本缓存!!
更新排名数据:
/**
* 每隔5分钟更新一次redis中的用户排名数据
*/
@Scheduled(cron = "0 0/5 * * * ?")
public void repalceUserList(){
executorService.execute(()->{
//1.查询全部参加比赛的用户
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//查询条件 首先是参赛选手 以用户的点赞数按照降序查询
queryWrapper.eq("user_type",2).orderBy(true,false,"user_like");
//查询
List<User> userList = userMapper.selectList(queryWrapper);
//2.将redis中的用户排名数据删除 这个时候所有的用户访问量都打到了我们的副本中
redisUtil.del("USER_LIST");
//3.将新查询出来的结果设置到 redis中
redisTemplate.opsForList().rightPushAll("USER_LIST",userList);
//4.线程休眠50ms 保证数据能同步到redis中
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
//5.使用自旋锁的方式判断用户排名数据缓存是否设置成功
while (redisUtil.hasKey("USER_LIST")){
//6.删除缓存副本
redisUtil.del("USER_LIST_COPY");
//7.再更新缓存副本
redisTemplate.opsForList().rightPushAll("USER_LIST_COPY",userList);
log.info("更新redis用户排名数据成功!!!");
return;
}
});
}
注:这里有个坑啊,为什么要去使用线程池的子线程去执行更新缓存的任务呢!!主要原因是:Spring自带的定时任务,默认只有一个线程去执行定时任务,意思就是有多个定时任务需要每隔5分钟执行一次,他并不是并行而是串行,一个定时任务没有执行完就不会执行另外一个定时任务,这里需要配置(很多教程里都没有提到很坑)或者可以使用Quarzt!!!可以去看看我写的另外一篇博客 (还没写呢!!)
线程池创建
由于我们需要使用到线程池,一般不会使用默认的策略,根据的你的业务场景来,默认的线程池创建方式可能会导致资源浪费或者创建的线程数过多服务器根本不支持就不详说了,创建的详细参数写的很明确直接参考即可!!!这里呢就通过配置类统一创建,并注入Spring容器方便,其他地方进行调用!!
**
* @Author: Joker-CC
* @Path:
* @Date 2021/05/29 23:52
* @Description:
* @Version: 1.0
*/
@Configuration
public class ThreadConfig {
//创建线程池
//七大参数
//int corePoolSize 1.核心线程数6个--->相当于银行柜台的默认开放区
//int maximumPoolSize 2.最大线程数16个--->相当于银行柜台的最大开放量--->优化1.对于cpu密集型,电脑有几核就设置几核 2.io密集型通常就需要开cpu核数的两倍的线程 只有当核心线程数 +阻塞队列的长度<请求的线程数就会触发最大线程数 不然就使用核心线程
//long keepAliveTime 3.多余的空闲线程的存活时间10分钟,当前池中线程数量超过corePoolSize时,当空闲时间达keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为止。
//TimeUnit unit 4.keepAliveTime参数的时间单位 --->TimeUnit.MINUTES分钟
//BlockingQueue workQueue 5.工作队列(阻塞队列) 按照FIFO(first input first out) 相当于银行的排队等候区
//ThreadFactory threadFactory 6.线程工程 使用默认的线程工厂
//RejectedExecutionHandler handler 7.四种拒绝策略 当工作队列中的任务已满并且线程池中的线程数量也达到最大,这时如果有新任务提交进来,拒绝策略就是解决这个问题的
//①CallerRunsPolicy 哪来的去哪里!
//在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。
//②AbortPolicy 银行满了,还有人进来,不处理这个人的,抛出异常
//直接丢弃任务,并抛出RejectedExecutionException异常。
//③DiscardPolicy 队列满了,丢掉任务,不会抛出异常!
//直接丢弃任务,什么都不做。
//④DiscardOldestPolicy //队列满了,尝试去和最早的竞争,也不会抛出异常!
//抛弃最早进入队列的那个任务,然后尝试把这次拒绝的任务放入队列。
@Bean(name = "diyThreadPool")
public ExecutorService createExecutorService(){
return new ThreadPoolExecutor(6,16,10L, TimeUnit.MINUTES,new LinkedBlockingQueue<>(1000), Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());
}
}