3D目标检测之数据集
目录
-
- 1. KITTI Dataset
- 2. Waymo Open Dataset
- 3. NuScenes DataSet
- 4. Appllo Scape
- 5. Lyft L5
- 6. Argoverse
- 7. H3D
- 8. Cityscapes
- 9. CADC
- 10. Oxford RobotCar
先来列几个介绍数据集的论文和一些方便下载数据集的社区或者网站。
论文:
- Deep Learning based Monocular Depth Prediction: Datasets, Methods and Applications(这篇论文里有讲单目深度估计领域常用的数据集,跟单目3D目标检测数据集很多是重合的)
数据集网站:
- 公开数据集下载 | 格物钛,非结构化数据平台,这个是国内地址,下载方便,甚至不用下载就能直接预览数据。
- Open Datasets - Scale,这个网址主要提供数据集汇总列表。
之前在知乎上搜到了一篇讲数据集的文章,太优秀了:自动驾驶开源数据集汇总。虽然网上有很多这类数据集的介绍了,但是我还是想自己整理、输出一下。学习一些知识后,通过自己的理解,整理,再输出一遍,有助于让自己记忆深刻一点。
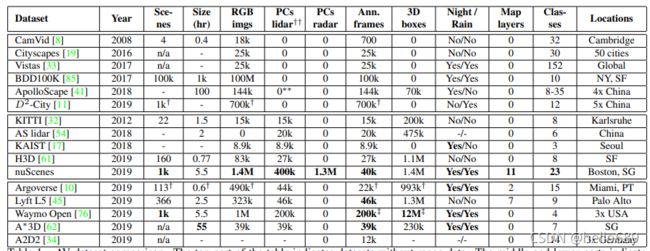
image source: 文献 nuScenes: A multimodal dataset for autonomous driving
1. KITTI Dataset
数据集地址:The KITTI Dataset
论文地址:Vision meets robotics: The KITTI dataset
3D object detection benchmark 由:
- 7481张train image,
- 7518张test image,
- 以及对应的点云组成,
- 共包含80256个标记的目标。
- 9个类别
评价标准:使用PASCAL标准来评估3D目标检测性能。对于汽车,我们要求3D包围盒重叠70%,而对于行人和自行车,我们要求3D包围盒重叠50%。在2019年10月8日,Kitti官网遵循了Mapillary团队在他们的论文 Disentangling Monocular 3D Object Detection中提出的建议,使用40个召回位置取代原来Pascal VOC基准中提出的11个召回位置。这样比较结果比较比较公平。具体数据评估方法,网上有很多博客已经介绍,我就不再赘述:KITTI 3D目标检测的评估指标_W1995S的博客-CSDN博客。这里需要提前了解两个概念:
-
mAP(mean Average Precision,所有类标签的平均精确率)
-
PR曲线

img source: The KITTI Vision Benchmark Suite (cvlibs.net)
标注数据介绍:
000000.txt:
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
- 1 类型: 包括Car、Van、Pedestrian、Cyclist、Truck、DontCare等
- 2 截断: 从0(未截断)到1(截断)浮点数,截断指的是离开图像边界的对象
- 3 遮挡 : 用整数 (0,1,2,3) 来表示几种状态:
0 =完全可见, 1 = 部分遮挡
2 = 大范围遮挡, 3 = 未知 - 4 alpha: 观察物体的角度,范围[-pi , pi]
- 5-8 bbox: contains left, top, right, bottom pixel coordinates
- 9-11 维度外形尺寸: 3D object dimensions: height, width, length (in meters)
- 12-14 位置: 在相机坐标系下3D object location x,y,z(in meters)
- 15 rotation_y: 在相机坐标系中关于关于y-axis的旋转,范围[-pi, pi]
注:在这里,“DontCare”标签表示物体未被标记的区域,因为它们离激光扫描仪太远了。
000000.png

000001.txt:
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 511.35 174.96 527.81 187.45 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 532.37 176.35 542.68 185.27 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 559.62 175.83 575.40 183.15 -1 -1 -1 -1000 -1000 -1000 -10
000001.png

Easy、Moderate、Hard标准定义如下:
-
Easy: Min. bounding box height: 40 Px, Max. occlusion level: Fully visible, Max. truncation: 15 %
-
Moderate: Min. bounding box height: 25 Px, Max. occlusion level: Partly occluded, Max. truncation: 30 %
-
Hard: Min. bounding box height: 25 Px, Max. occlusion level: Difficult to see, Max. truncation: 50 %
2. Waymo Open Dataset
数据集地址:https://waymo.com/open
论文地址:
- Scalability in Perception for Autonomous Driving: Waymo Open Dataset(2020)
- [Large Scale Interactive Motion Forecasting for Autonomous Driving :The WAYMO OPEN MOTION DATASET(2021)]([2104.10133] Large Scale Interactive Motion Forecasting for Autonomous Driving : The Waymo Open Motion Dataset (arxiv.org))
整个数据集包含1150个场景,每个场景时长为20秒,且LiDAR和Camera是经过同步和标定处理过的。 对图像和激光雷达的bounding box进行了仔细的标注,并在各帧之间使用了一致的标识符。
数据集介绍:
-
1150个场景,每个场景时长约为20秒
-
1000个训练集,150个测试集
-
1200万个LiDAR注释框和约1200万个图像注释框
-
Perception Dataset: 标签为Vehicles, Pedestrians, Cyclists, Signs 四类
-
Motion Dataset:标签为Vehicles, Pedestrians, Cyclists三类。
3. NuScenes DataSet
image source: https://www.nuscenes.org/
数据集地址:https://www.nuscenes.org/download
论文地址:nuScenes: A Multimodal Dataset for Autonomous Driving
数据集来源简要介绍:
Motional是由现代汽车集团和Aptiv合资成立的一家无人驾驶公司,致力于使无人驾驶汽车安全,可靠和可达。它具有独特的强大功能,使我们能够从根本上改变人们的生活方式。Motional的使命是创造和发展能够挽救生命、节省时间和金钱的技术,改变世界的运转方式。
nuScenes数据集是由Motional团队开发的用于无人驾驶的公共大型数据集。为了支持公众在计算机视觉和自动驾驶的研究,Motional公开了nuScenes的部分数据。
关于nuScenes:
- 1个LiDAR,5个RADAR,6个camera,IMU,GPS
- 1000 scenes of 20s each
- 1,400,000 camera images
- 390,000 lidar sweeps
- Two diverse cities: Boston and Singapore
- 1.4M 3D bounding boxes manually annotated for 23 object classes
- New: 1.1B lidar points manually annotated for 32 classes
- 300GB
其中激光雷达:32线、范围为80-100m
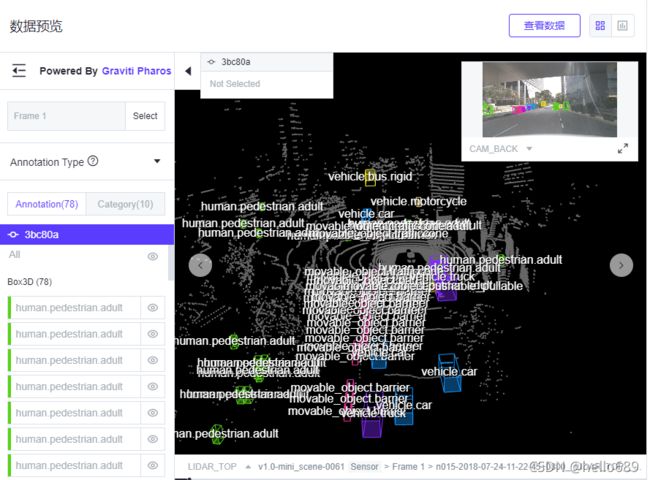
image source: https://gas.graviti.cn/dataset/motional/nuScenes
与其他数据集的对比:
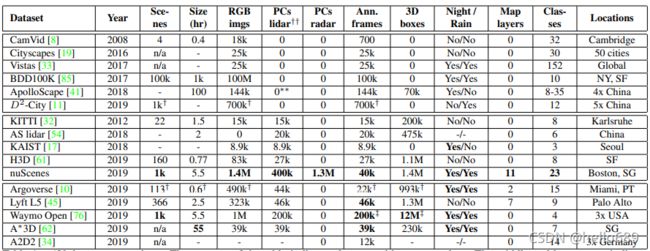
image source: 论文 nuScenes: A multimodal dataset for autonomous driving
4. Appllo Scape
数据集地址:Apollo Scape
论文地址:The ApolloScape Dataset

image source: The ApolloScape Dataset for Autonomous Driving
ApolloScape由RGB视频和对应的稠密点云组成。包含140K张图片,并且每张图片都有像素级的语义信息。在国内采集的数据,所以相比于国外的一些数据集,ApolloScape数据集包含的交通场景还是很复杂的,首先就是图片中的人多,车多,移动物体多。 此外,此数据集还包含基于车道颜色和样式的不同车道标记。

image source: The ApolloScape Dataset for Autonomous Driving
具体特点:
- 与kitti类似,也分为easy、moderate、hard三个子类。
- 标注信息包含28类车道线
- 使用了2D/3D联合标注通道,是包含3D标注信息的开放数据集
与其他数据集的对比:

image source: The ApolloScape Dataset for Autonomous Driving
5. Lyft L5
数据集地址:
- Lyft L5
- Lyft 3D Object Detection for Autonomous Vehicles Challenge
论文地址:
- Self-driving Motion Prediction Dataset
数据集介绍地址:
- Lyft 3D Object Detection for Autonomous Vehicles | Kaggle
- Devkit for the public 2019 Lyft Level 5 AV Dataset
数据介绍:
这个数据集又分为Prediction Dataset和PerceptionDataset。
- Prediction Dataset
此数据集的论文地址:Self-driving Motion Prediction Dataset
超过1000小时的自动驾驶运动数据集。这是一个由20辆自动驾驶汽车组成的车队在加 州Palo Alto的一条固定路线上花了4个月收集的数据。由17万个场景组成,每个场景长25秒, 捕捉自动驾驶系统的感知输出,自动驾驶系统编码附近车辆、自行车和行人的精确位置和动 作。除此之外,该数据集还包含一个包含15242个标记元素的高清晰度语义图和该区域的高清 晰度鸟瞰图。总数据量有1000多个小时,接近90GB。
数据集主要有三部分组成:
- 17万场景,每25秒,捕捉自动驾驶汽车和它周围的交通参与者的运动。
- 一个高清语义地图,捕捉道路规则、车道几何形状和其他交通要素。
- 该地区的高分辨率航拍照片,可以进一步帮助预测。
- Perception Dataset
- 1.3M 3D annotations
- 30K lidar point clouds
- 350+ scenes at 60-90 minutes long
这个数据集包含训练集测试集和验证集,大小为120GB左右。下边的这个网址可以手动的用QWEASD或者上下键来观察点云和对应的RGB图像数据集。

image source: Perception - Level 5 (level-5.global)
6. Argoverse
7. H3D
8. Cityscapes
这个城市景观数据集(Cityscapes)主要侧重于城市街道的2D语义分割,包含30个类别,精标注5000张图,粗标注20 000张图片。2020年10月上线了3D bounding box的标注,标注分结果分为8大类下的30类标签,简化版标签中含有19类。
- 1024x2048RGB图像,采样频率17Hz,16位深HDR;同时也提供压缩的8位深LDR版本。
9. CADC
地址:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/2001.10117
加拿大多伦多大学凭借得天独厚的优势提供的雪天驾驶数据集,场景极具针对性。
- 标注的数据类型太少,只有3D bounding box
- 标签类型也比较粗糙
- 采集路线固定,场景较为单调
- 原始数据量为500GB
10. Oxford RobotCar
全天候全光照超大型数据集。采集的路线是Oxford中心,因为采集了很多遍不同天气和交通状态下的数据,最后体量大得离谱。但是,数据集只提供了图像、雷达、激光雷达和GPS/IMU的原始数据,并没有进行额外的标注。
- 23+TB的原始数据