pytorch学习14:使用CIFAR10数据训练LetNet模型
工具方法和一些设置
这里有一个帮助显示图片的方法和解决图片不显示问题的设置。
### 一些工具方法
import matplotlib.pyplot as plt
import numpy as np
# 如果不加则会出现如下错误,且不会显示图片
# Error #15: Initializing libiomp5md.dll...
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
def imshow(img):
"""
展示图片
:param img:
"""
# 去标准化
img = img / 2 + 0.5
npImg = img.numpy()
# 切换维度
plt.imshow(np.transpose(npImg, (1, 2, 0)))
# 展示图片
plt.show()
创建模型
模型结果如图:
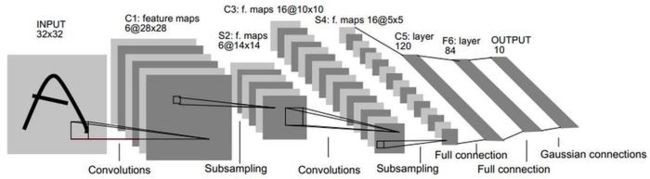
由于CIFAR10数据为彩色图片,因此第一层卷积 c o n v 1 conv1 conv1 将输入设置为 3图像通道。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 因为输入为彩色图片,因此输入设置为3通道图像
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
导入CIFAR10数据
导入数据并对数据进行归一化,便于模型学习。
import torch.utils.data
import torchvision.datasets
import torchvision.transforms as transforms
def load_data():
"""
载入数据并转换为 DataLoader
:return: trainloader, testloader
"""
# 设置数据读取操作
transform = transforms.Compose([
# 导入为 Tensor
transforms.ToTensor(),
# 进行归一化操作,使数据范围变为[-1, 1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 导入CIFAR10训练集
trainset = torchvision.datasets.CIFAR10(
root='./data', # 导入数据路径
train=True, # 导入数据是否为训练集
download=True, # 若未发现数据是否进行下载
transform=transform # 对数据进行处理
)
# 将训练集变为数据加载器,便于数据拿取
trainloader = torch.utils.data.DataLoader(
trainset, # 源数据
batch_size=4, # 批大小
shuffle=True, # 是否打乱
# num_workers=2 # 设置为2会报 [Errno 32] Broken pipe错误
num_workers=0 # 工作进程数
)
# 导入测试集
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=4, shuffle=False, num_workers=2
)
# 定义类名
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
return trainloader, testloader, classes
训练模型
使用交叉熵损失和随机梯度下降训练模型。
import torch.optim as optim
def train(trainloader, _iter=2, lr=0.001):
"""
训练
:param trainloader:
:return:net
"""
# 实例化模型
net = Net()
# 指定损失函数为交叉熵
loss_function = nn.CrossEntropyLoss()
# 绑定优化器
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=0.9)
# 记录每一步的损失
losses = []
# 开始训练
for epoch in range(_iter):
running_loss = 0
for i, data in enumerate(trainloader, 0):
# 获取输入
inputs, labels = data
# 清除累计梯度
optimizer.zero_grad()
# 正向传播
outputs = net(inputs)
# 计算损失
loss = loss_function(outputs, labels)
# 反向传播
loss.backward()
# 梯度下降
optimizer.step()
# 累加损失
running_loss += loss.item()
# 打印状态信息
if i % 2000 == 1999:
# 每2000批次打印一次
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
# 记录损失
losses.append(running_loss / 2000)
# 重置损失
running_loss = 0
print('Finished Training')
# 画出损失折线图
plt.plot(list(range(len(losses))), losses)
plt.show()
return net
测试样例模型
使用训练后的模型对测试集的数据进行预测。
def test(net, testloader, classes):
"""
测试模型
:param net:
:param testloader:
:param classes:
:return:
"""
# 加载数据
dataiter = iter(testloader)
images, labels = dataiter.next()
# 显示图片
# torchvision.utils.make_grid 将多张图片拼成一张
imshow(torchvision.utils.make_grid(images))
# 输出正确分类
print('正确分类:', ' '.join([classes[i] for i in labels]))
# 预测
outputs = net(images)
print('预测分类:', ' '.join([classes[i] for i in outputs.argmax(dim=1)]))
测试集总体评估
在测试集上对模型总体效率进行评估。
def eval(net, testloader):
# 记录正确个数
correct = 0
# 记录所有样例数
total = 0
for data in testloader:
# 预测数据
imgs, labels = data
outputs = net(imgs)
# 利用 argmax 来获得最大预测的索引
preds = outputs.argmax(dim=1)
# 记录数量和正确情况
total += labels.size(0)
correct += (preds == labels).sum()
print('在整个测试集上的正确率为:%d %%' % (100 * correct / total))
对每个类进行评估
对模型在每个类的识别能力进行评估。
def eval_for_each_class(net, testloader, classes):
# 记录每个类的正确数和总数
class_correct = list(0 for i in range(len(classes)))
class_total = list(0 for i in range(len(classes)))
for data in testloader:
# 预测数据
imgs, labels = data
outputs = net(imgs)
preds = outputs.argmax(dim=1)
c = (preds == labels)
# 记录数据和正确情况
for index, label in enumerate(labels):
class_correct[label] += c[index].item()
class_total[label] += 1
for i, c in enumerate(classes):
print('%5s 类的正确率为:%2d %%' %
(c, 100 * class_correct[i] / class_total[i]))
测试代码
用于走完训练和测试流程。
if __name__ == '__main__':
trainloader, testloader, classes = load_data()
final_net = train(trainloader)
test(final_net, testloader, classes)
eval(final_net, testloader)
eval_for_each_class(final_net, testloader, classes)
结果展示
训练损失曲线

可以看出后面的线条已经较为平缓,损失函数已经开始收敛。
测试样例模型结果
正确分类: cat ship ship plane
预测分类: cat ship ship ship
可以看出有3个样例预测正确,1个样例预测错误。
测试集总体评估结果
在整个测试集上的正确率为:56 %
各类评估结果
plane 类的正确率为:64 %
car 类的正确率为:58 %
bird 类的正确率为:38 %
cat 类的正确率为:25 %
deer 类的正确率为:51 %
dog 类的正确率为:43 %
frog 类的正确率为:74 %
horse 类的正确率为:62 %
ship 类的正确率为:80 %
truck 类的正确率为:63 %
总结
由上面的各项结果可以看出,此次训练的LetNet模型准确率远低于现在的模型。这是由于LetNet模型是结构较为简单经典模型,且只进行了简单的训练。
虽然结果并不理想,但通过这次练习了解到了用pytorch进行训练的基本流程和实现。
完整代码
### 一些工具方法
import matplotlib.pyplot as plt
import numpy as np
# 如果不加则会出现如下错误,且不会显示图片
# Error #15: Initializing libiomp5md.dll...
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
#
def imshow(img):
"""
展示图片
:param img:
"""
# 去标准化
img = img / 2 + 0.5
npImg = img.numpy()
# 切换维度
plt.imshow(np.transpose(npImg, (1, 2, 0)))
# 展示图片
plt.show()
###
### 1、创建模型
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 因为输入为彩色图片,因此输入设置为3通道图像
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
### 2、导入数据
import torch.utils.data
import torchvision.datasets
import torchvision.transforms as transforms
def load_data():
"""
载入数据并转换为 DataLoader
:return: trainloader, testloader
"""
# 设置数据读取操作
transform = transforms.Compose([
# 导入为 Tensor
transforms.ToTensor(),
# 进行归一化操作,使数据范围变为[-1, 1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 导入CIFAR10训练集
trainset = torchvision.datasets.CIFAR10(
root='./data', # 导入数据路径
train=True, # 导入数据是否为训练集
download=True, # 若未发现数据是否进行下载
transform=transform # 对数据进行处理
)
# 将训练集变为数据加载器,便于数据拿取
trainloader = torch.utils.data.DataLoader(
trainset, # 源数据
batch_size=4, # 批大小
shuffle=True, # 是否打乱
# num_workers=2 # 设置为2会报 [Errno 32] Broken pipe错误
num_workers=0 # 工作进程数
)
# 导入测试集
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=4, shuffle=False, num_workers=2
)
# 定义类名
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
return trainloader, testloader, classes
### 3、开始训练
import torch.optim as optim
def train(trainloader, _iter=2, lr=0.001):
"""
训练
:param trainloader:
:return:net
"""
# 实例化模型
net = Net()
# 指定损失函数为交叉熵
loss_function = nn.CrossEntropyLoss()
# 绑定优化器
optimizer = optim.SGD(net.parameters(), lr=lr, momentum=0.9)
# 记录每一步的损失
losses = []
# 开始训练
for epoch in range(_iter):
running_loss = 0
for i, data in enumerate(trainloader, 0):
# 获取输入
inputs, labels = data
# 清除累计梯度
optimizer.zero_grad()
# 正向传播
outputs = net(inputs)
# 计算损失
loss = loss_function(outputs, labels)
# 反向传播
loss.backward()
# 梯度下降
optimizer.step()
# 累加损失
running_loss += loss.item()
# 打印状态信息
if i % 2000 == 1999:
# 每2000批次打印一次
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
# 记录损失
losses.append(running_loss / 2000)
# 重置损失
running_loss = 0
print('Finished Training')
# 画出损失折线图
plt.plot(list(range(len(losses))), losses)
plt.show()
return net
### 4、测试模型
def test(net, testloader, classes):
"""
测试模型
:param net:
:param testloader:
:param classes:
:return:
"""
# 加载数据
dataiter = iter(testloader)
images, labels = dataiter.next()
# 显示图片
# torchvision.utils.make_grid 将多张图片拼成一张
imshow(torchvision.utils.make_grid(images))
# 输出正确分类
print('正确分类:', ' '.join([classes[i] for i in labels]))
# 预测
outputs = net(images)
print('预测分类:', ' '.join([classes[i] for i in outputs.argmax(dim=1)]))
### 5、评估整个测试集
def eval(net, testloader):
# 记录正确个数
correct = 0
# 记录所有样例数
total = 0
for data in testloader:
# 预测数据
imgs, labels = data
outputs = net(imgs)
# 利用 argmax 来获得最大预测的索引
preds = outputs.argmax(dim=1)
# 记录数量和正确情况
total += labels.size(0)
correct += (preds == labels).sum()
print('在整个测试集上的正确率为:%d %%' % (100 * correct / total))
### 6、对每个类进行评估
def eval_for_each_class(net, testloader, classes):
# 记录每个类的正确数和总数
class_correct = list(0 for i in range(len(classes)))
class_total = list(0 for i in range(len(classes)))
for data in testloader:
# 预测数据
imgs, labels = data
outputs = net(imgs)
preds = outputs.argmax(dim=1)
c = (preds == labels)
# 记录数据和正确情况
for index, label in enumerate(labels):
class_correct[label] += c[index].item()
class_total[label] += 1
for i, c in enumerate(classes):
print('%5s 类的正确率为:%2d %%' %
(c, 100 * class_correct[i] / class_total[i]))
if __name__ == '__main__':
trainloader, testloader, classes = load_data()
final_net = train(trainloader)
test(final_net, testloader, classes)
eval(final_net, testloader)
eval_for_each_class(final_net, testloader, classes)