df.to html函数,pd.DataFrame 数据的保存和读取((df.to_csv、df.to_json、df.to_html、df.to_excel))...
DataFrame 数据的保存和读取
df.to_csv 写入到 csv 文件
pd.read_csv 读取 csv 文件
df.to_json 写入到 json 文件
pd.read_json 读取 json 文件
df.to_html 写入到 html 文件
pd.read_html 读取 html 文件
df.to_excel 写入到 excel 文件
pd.read_excel 读取 excel 文件
pandas.DataFrame.to_csv
将 DataFrame 写入到 csv 文件
DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True,
index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"',
line_terminator='\n', chunksize=None, tupleize_cols=None, date_format=None, doublequote=True,
escapechar=None, decimal='.')
参数:
path_or_buf : 文件路径,如果没有指定则将会直接返回字符串的 json
sep : 输出文件的字段分隔符,默认为 “,”
na_rep : 用于替换空数据的字符串,默认为''
float_format : 设置浮点数的格式(几位小数点)
columns : 要写的列
header : 是否保存列名,默认为 True ,保存
index : 是否保存索引,默认为 True ,保存
index_label : 索引的列标签名
.
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
list_l = [[11, 12, 13, 14, 15], [21, 22, 23, 24, 25], [31, 32, 33, 34, 35]]
date_range = pd.date_range(start="20180701", periods=3)
df = pd.DataFrame(list_l, index=date_range,
columns=['a', 'b', 'c', 'd', 'e'])
print(df)
"""
a b c d e
2018-07-01 11 12 13 14 15
2018-07-02 21 22 23 24 25
2018-07-03 31 32 33 34 35
"""
df.to_csv("tzzs_data.csv")
"""
csv 文件内容:
,a,b,c,d,e
2018-07-01,11,12,13,14,15
2018-07-02,21,22,23,24,25
2018-07-03,31,32,33,34,35
"""
read_csv = pd.read_csv("tzzs_data.csv")
print(read_csv)
"""
Unnamed: 0 a b c d e
0 2018-07-01 11 12 13 14 15
1 2018-07-02 21 22 23 24 25
2 2018-07-03 31 32 33 34 35
"""
df.to_csv("tzzs_data2.csv", index_label="index_label")
"""
csv 文件内容:
index_label,a,b,c,d,e
2018-07-01,11,12,13,14,15
2018-07-02,21,22,23,24,25
2018-07-03,31,32,33,34,35
"""
read_csv2 = pd.read_csv("tzzs_data2.csv")
print(read_csv2)
"""
index_label a b c d e
0 2018-07-01 11 12 13 14 15
1 2018-07-02 21 22 23 24 25
2 2018-07-03 31 32 33 34 35
"""
1.首先查询当前的工作路径:
import os
os.getcwd() #获取当前工作路径
2.to_csv()是DataFrame类的方法,read_csv()是pandas的方法
dt.to_csv() #默认dt是DataFrame的一个实例,参数解释如下
路径 path_or_buf: A string path to the file to write or a StringIO
dt.to_csv('Result.csv') #相对位置,保存在getwcd()获得的路径下
dt.to_csv('C:/Users/think/Desktop/Result.csv') #绝对位置
分隔符 sep : Field delimiter for the output file (default ”,”)
dt.to_csv('C:/Users/think/Desktop/Result.csv',sep='?')#使用?分隔需要保存的数据,如果不写,默认是,
替换空值na_rep: A string representation of a missing value (default ‘’)
dt.to_csv('C:/Users/think/Desktop/Result1.csv',na_rep='NA') #确实值保存为NA,如果不写,默认是空
格式 float_format: Format string for floating point numbers
dt.to_csv('C:/Users/think/Desktop/Result1.csv',float_format='%.2f') #保留两位小数
是否保留某列数据 cols: Columns to write (default None)
dt.to_csv('C:/Users/think/Desktop/Result.csv',columns=['name']) #保存索引列和name列
是否保留列名 header: Whether to write out the column names (default True)
dt.to_csv('C:/Users/think/Desktop/Result.csv',header=0) #不保存列名
是否保留行索引index: whether to write row (index) names (default True)
dt.to_csv('C:/Users/think/Desktop/Result1.csv',index=0) #不保存行索引
pandas.DataFrame.to_json
将 Dataframe 写入到 json 文件
DataFrame.to_json(path_or_buf=None, orient=None, date_format=None, double_precision=10, force_ascii=True,
date_unit='ms', default_handler=None, lines=False, compression=None, index=True)
参数:
path_or_buf : 文件路径,如果没有指定则将会直接返回字符串的 json。
代码:
df.to_json("tzzs_data.json")
read_json = pd.read_json("tzzs_data.json")
print(read_json)
"""
a b c d e
2018-07-01 11 12 13 14 15
2018-07-02 21 22 23 24 25
2018-07-03 31 32 33 34 35
"""
json:
{
"a": {
"1530403200000": 11,
"1530489600000": 21,
"1530576000000": 31
},
"b": {
"1530403200000": 12,
"1530489600000": 22,
"1530576000000": 32
},
"c": {
"1530403200000": 13,
"1530489600000": 23,
"1530576000000": 33
},
"d": {
"1530403200000": 14,
"1530489600000": 24,
"1530576000000": 34
},
"e": {
"1530403200000": 15,
"1530489600000": 25,
"1530576000000": 35
}
}
pandas.DataFrame.to_html
将 Dataframe 写入到 html 文件
DataFrame.to_html(buf=None, columns=None, col_space=None, header=True, index=True, na_rep='NaN', formatters=None,
float_format=None, sparsify=None, index_names=True, justify=None, bold_rows=True, classes=None,
escape=True, max_rows=None, max_cols=None, show_dimensions=False, notebook=False, decimal='.',
border=None, table_id=None)
df.to_html("tzzs_data.html")
read_html = pd.read_html("tzzs_data.html")
print(read_html)
"""
[ Unnamed: 0 a b c d e
0 2018-07-01 11 12 13 14 15
1 2018-07-02 21 22 23 24 25
2 2018-07-03 31 32 33 34 35]
"""
#
print(read_html[0])
"""
Unnamed: 0 a b c d e
0 2018-07-01 11 12 13 14 15
1 2018-07-02 21 22 23 24 25
2 2018-07-03 31 32 33 34 35
"""
HTML:
abcde
2018-07-0111121314152018-07-0221222324252018-07-033132333435在浏览器中打开:

df.to_html 生成的是一个 html 格式的 table 表,我们可以在前后加入其他标签,丰富页面。ps:如果有中文字符,需要在 head 中设置编码格式。
# -*- coding: utf-8 -*-
"""
@author: tz_zs
"""
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
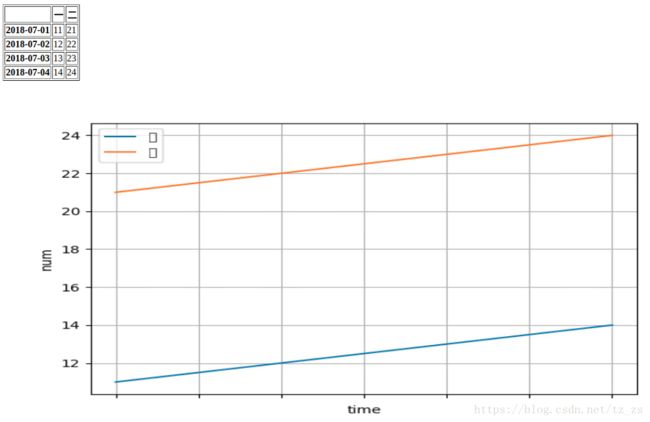
index = ["2018-07-01", "2018-07-02", "2018-07-03", "2018-07-04"]
df = pd.DataFrame(index=index)
df["一"] = [11, 12, 13, 14]
df["二"] = [21, 22, 23, 24]
print(df)
"""
一 二
2018-07-01 11 21
2018-07-02 12 22
2018-07-03 13 23
2018-07-04 14 24
"""
axes_subplot = df.plot()
# print(type(axes_subplot)) #
plt.xlabel("time")
plt.ylabel("num")
plt.legend(loc="best")
plt.grid(True)
plt.savefig("test.png")
HEADER = '''
'''
FOOTER = '''
''' % ("test.png")
with open("test.html", 'w') as f:
f.write(HEADER)
f.write(df.to_html(classes='df'))
f.write(FOOTER)
.
.
pandas.DataFrame.to_excel
将 DataFrame 写入 excel 文件
DataFrame.to_excel(excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None,
header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None,
merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None)
#!/usr/bin/python2.7
# -*- coding:utf-8 -*-
"""
@author: tz_zs
"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
list_l = [[1, 3, 3, 5, 4], [11, 7, 15, 13, 9], [4, 2, 7, 9, 3], [15, 11, 12, 6, 11]]
index = ["2018-07-01", "2018-07-02", "2018-07-03", "2018-07-04"]
df = pd.DataFrame(list_l, index=index, columns=['a', 'b', 'c', 'd', 'e'])
print(df)
"""
a b c d e
2018-07-01 1 3 3 5 4
2018-07-02 11 7 15 13 9
2018-07-03 4 2 7 9 3
2018-07-04 15 11 12 6 11
"""
df.to_excel("test.xls")

pandas.read_excel
读取 excel
可能遇到的报错:ImportError: Missing optional dependency 'xlrd'. Install xlrd >= 1.0.0 for Excel support Use pip or conda to install xlrd.
解决方法:安装 xlrd 包。
其他文章: