PytorchCNN项目搭建3--- Cifar10数据集的处理
PytorchCNN项目搭建3--- Cifar10数据集的处理
- 前期准备:
- 1. Cifar10数据集从官网下载
- 2. 把训练集转换为图片, 并把图片路径及名称保存到txt文件中,还把训练集按照一定的概率分为训练数据集和验证数据集
- 3. 测试集test_dataset也做同样的处理
- 4. 然后将图片转换成数据集,继承torch.utils.data.Dataset的类进行书写
- 5. 对图像数据进行处理
- 参考文献
整体的代码在我的github上面可以查阅
-
在实际卷积神经网络关于图像处理的实验中,我们常常直接处理的是图像本身,而不是数据集,所以我们需要学会怎么把图像转换为数据集,然后进行训练,今天的主要内容就是把图像转换为熟悉的数据集~
-
以Cifar10数据集为例,先从官网下载Cifar10数据集,然后把数据集转换成图片,再把图像转换成数据集。
前期准备:
实验设备说明:
- 我使用的是远程服务器,pycharm编程
- 先建立PytorchCNN文件夹,之后的各种文件和文件夹都会在这个文件中
1. Cifar10数据集从官网下载
Cifar10数据集共有60000张图片,其中包含50000张训练图片和10000张测试图片,每张图片为3*32*32(3通道,图片大小为32*32),
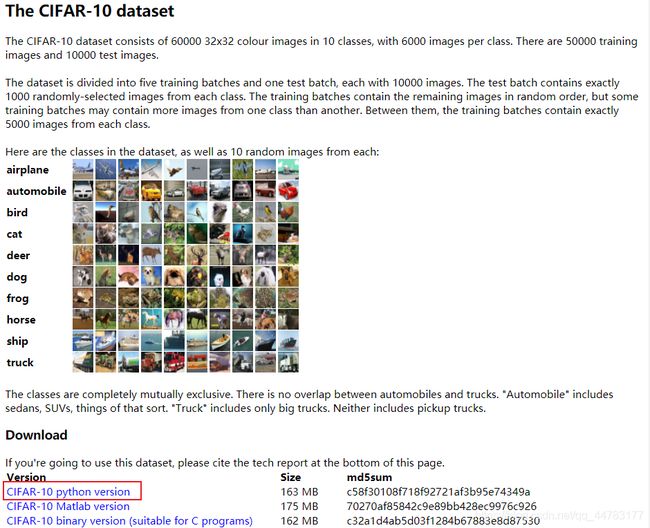
打开Cifar10官网,从Vision下载所需的部分,然后可以按照官网的教程学习后面的压缩过程。
注意:
- 因为数据集比较大,所以最好把数据集下载到根目录下面,每次使用的时候直接调用,可以节省空间。我把Cifar10放在了自己的根目录’/DATASET/Cifar10/’
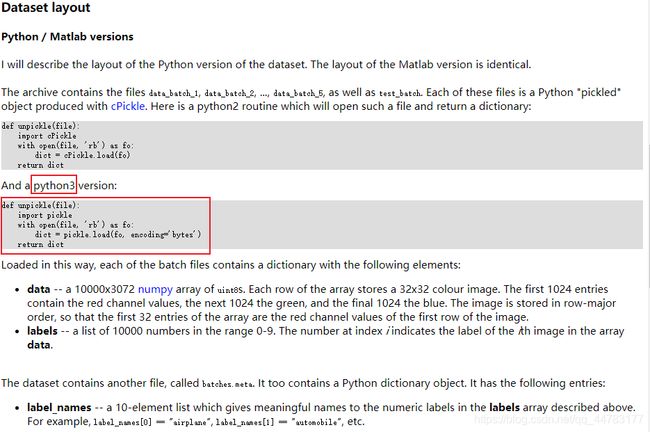
- 我们可以看到,数据集中共包含6个文件, data_batch_1, data_batch_2, …, data_batch_5, 和 test_batch,每个batch为10000张图片,下面就对每个文件进行处理
2. 把训练集转换为图片, 并把图片路径及名称保存到txt文件中,还把训练集按照一定的概率分为训练数据集和验证数据集
'''seg dataset to pic'''
def Trainset2Pic(cfg):
classes = ('airplane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
valid_pic_txt = open(cfg.PARA.cifar10_paths.valid_data_txt, 'w')# 设置为‘w'模式,并且放在最开始,则每次进行时,都会清空重写。
train_pic_txt = open(cfg.PARA.cifar10_paths.train_data_txt, 'w')
for i in range(1, 6):
label_batch = ('A', 'B', 'C', 'D', 'E')
traindata_file = os.path.join(cfg.PARA.cifar10_paths.original_trainset_path, 'data_batch_' + str(i))
with open(traindata_file, 'rb') as f:
train_dict = pkl.load(f,encoding='bytes') # encoding=bytes ,latin1,train_dict为字典,包括四个标签值:b'batch_label',b'labels',b'data',b'filenames'
data_train = np.array(train_dict[b'data']).reshape(10000, 3, 32, 32)
label_train = np.array(train_dict[b'labels'])
num_val = int(data_train.shape[0]*cfg.PARA.cifar10_paths.validation_rate)#验证集的个数
val_list = random.sample(list(range(0,int(data_train.shape[0]))), num_val)
for j in range(10000):
imgs = data_train[j]
r = Image.fromarray(imgs[0])
g = Image.fromarray(imgs[1])
b = Image.fromarray(imgs[2])
img = Image.merge("RGB", (b, g, r))
picname_valid = cfg.PARA.cifar10_paths.after_validset_path + classes[label_train[j]] + label_batch[i - 1] + str("%05d" % j) + '.png'
picname_train = cfg.PARA.cifar10_paths.after_trainset_path + classes[label_train[j]] + label_batch[i - 1] + str("%05d" % j) + '.png'
if (j in val_list):#如果在随机选取的验证集列表中,则保存到验证集的文件夹下
img.save(picname_valid)
valid_pic_txt.write(picname_valid + ' ' + str(label_train[j]) + '\n')
else:
img.save(picname_train)
train_pic_txt.write(picname_train + ' ' + str(label_train[j]) + '\n')
valid_pic_txt.close()
train_pic_txt.close()
3. 测试集test_dataset也做同样的处理
def Testset2Pic(cfg):
classes = ('airplane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
testdata_file = os.path.join(cfg.PARA.cifar10_paths.original_testset_path, 'test_batch')
test_pic_txt = open(cfg.PARA.cifar10_paths.test_data_txt, 'w')
with open(testdata_file, 'rb') as f:
test_dict = pkl.load(f, encoding='bytes') # train_dict为字典,包括四个标签值:b'batch_label',b'labels',b'data',b'filenames'
data_test = np.array(test_dict[b'data']).reshape(10000, 3, 32, 32)
label_test= np.array(test_dict[b'labels'])
test_pic_txt = open(cfg.PARA.cifar10_paths.test_data_txt, 'a')
for j in range(10000):
imgs = data_test[j]
r = Image.fromarray(imgs[0])
g = Image.fromarray(imgs[1])
b = Image.fromarray(imgs[2])
img = Image.merge("RGB", [b, g, r])
picname_test = cfg.PARA.cifar10_paths.after_testset_path + classes[label_test[j]] + 'F' + str("%05d" % j) + '.png'
img.save(picname_test)
test_pic_txt.write(picname_test + ' ' + str(label_test[j]) + '\n')
test_pic_txt.close()
说明:
将图片处理后,我们可以在DATASET/cifar10文件夹下看到对应的txt文件和保存了相应数据集图片的文件夹
4. 然后将图片转换成数据集,继承torch.utils.data.Dataset的类进行书写
'''3. pic to dataset'''
from torch.utils.data import Dataset
class Cifar10Dataset(Dataset):
def __init__(self,txt,transform):
super(Cifar10Dataset,self).__init__()
fh = open(txt, 'r')
imgs = []
for line in fh:
line = line.strip('\n')
words = line.split() # 用split将该行切片成列表
imgs.append((words[0], int(words[1])))
self.imgs = imgs
self.transform = transform
def __getitem__(self, index):
file_path, label = self.imgs[index]
label = ToOnehot(label,10)
img = Image.open(file_path).convert('RGB')
if self.transform is not None:
Trans = DataPreProcess(img)
if self.transform == 'for_train' or 'for_valid':
img = Trans.transform_train()
elif self.transform == 'for_test':
img = Trans.transform_test()
return img,label
def __len__(self):
return len(self.imgs)
5. 对图像数据进行处理
class DataPreProcess():
def __init__(self,img):
self.img = img
def transform_train(self):
return transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),#三个均值,三个方差。
])(self.img)
def transform_test(self):
return transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])(self.img)
说明:
图像数据处理里有标准化操作,即进行0-1归一化,之后的训练便更易于收敛,但是为什么是这几个数字呢?我们来根据图像自己算一下吧~
class Normalization():
def __init__(self):
super(Normalization, self).__init__()
def Mean_Std(self, file_path):#计算所有图片的均值和方差
MEAN_B, MEAN_G, MEAN_R = 0, 0, 0
STD_B, STD_G, STD_R = 0, 0, 0
count = 0
with open(file_path, 'r') as f:
for line in f.readlines():
count += 1
words = line.strip('\n').split()
img = torch.from_numpy(cv2.imread(words[0])).float()
MEAN_B += torch.mean(img[:, :, 0] / 255)
MEAN_G += torch.mean(img[:, :, 1] / 255)
MEAN_R += torch.mean(img[:, :, 2] / 255)
STD_B += torch.std(img[:, :, 0] / 255)
STD_G += torch.std(img[:, :, 1] / 255)
STD_R += torch.std(img[:, :, 2] / 255)
MEAN_B, MEAN_G, MEAN_R = MEAN_B / count, MEAN_G / count, MEAN_R / count
STD_B, STD_G, STD_R = STD_B / count, STD_G / count, STD_R / count
return (MEAN_B, MEAN_G, MEAN_R), (STD_B, STD_G, STD_R)
def Normal(self,img, mean, std):#将一张图片,由正态分布变成0-1分布
img = img/255
img = img.transpose(2, 0, 1) #[H,W,C]-->[C,H,W],与pytorch的ToTensor做相同的变换,便于比较
img[0, :, :] = (img[0, :, :] - mean[0]) / std[0]
img[1, :, :] = (img[1, :, :] - mean[1]) / std[1]
img[2, :, :] = (img[2, :, :] - mean[2]) / std[2]
return img
def test():
img = cv2.imread('../../DATASET/cifar10/trainset/airplaneA00029.png')#读取一张图片,cv读取结果为[b,g,r] [H,W,C]
my_normal = Normalization()
img1 = my_normal.Normal(img, (0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
normal = transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
converToTensor = transforms.ToTensor()
img2 = converToTensor(img) #[H,W,C]-->[C,H,W]
img2 = normal(img2)
print(img1)
print(img2)
if __name__ == '__main__':
test()
参考文献
Cifar10官网
最后还要感谢我的师兄,是他手把手教我搭建了整个项目,还有实验室一起学习的小伙伴~ 希望他们万事胜意,鹏程万里!