数析三剑客 numpy pandas matplotlib 基础操作
NUMPY[一]:
NumPy是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多。NumPy(Numeric Python)提供了许多高级的数值编程工具。Numpy的一个重要特性是它的数组计算,是我们做数据分析必不可少的一个包。
import numpy as np- 数组基本操作
赋值

加减乘除 一个数

两个数组加减乘除
注:与矩阵乘法不同

np.zeros() 函数 返回全0数组
np.ones() 函数 返回全1数组

a.fill(x) 使 a 所有元素变为x (注:若x与a类型不同,自动x变astype后的元素)
a.fill(x) 返回值为None

np.linspace(start,stop,s) 返回等差数列
右边是包括在里面的,从a-b一共c个数的等差数列,其实np.arange好像也可以做...

np.random.rand(num) 返回num个【0:1】个随机数组

np.random.randn(num) 返回num个标准正态分布随机数组

np.random.randint(start,stop,num) 返回随机整数,从start-stop中随机num个

a.size 返回a元素个数

np.asarray() 可以设置array的参数,如dtype

a.dtype 返回查看数组类型
a.astype('需要转化成的类型') 返回转化后类型的数组

a.shape 返回元组表示形状

shape与reshape
a.shape赋值直接改变a的形状
a.reshape(x,y) 返回形状改变后的数组
a.transpose() 同 a.T

a.ndim 返回该维度

进行切片 和数列一样

切片在内存中使用的是引用机制;引用机制意味着,Python并没有为b分配新的空间来存储它的值,而是让b指向了a所分配的内存空间,因此,改变b会改变a的值:(注意:列表没有这个问题)


防止上述问题方法:
使用copy()方法返回一个复制,这个复制会申请新的内存:
a.copy()

numpy 中arange() 与range()类似
使用布尔数组来索引:

where (a)语句
where(array)where函数会返回所有非零元素的索引 由此可以条件判断筛选出符合条件的index

sort(a)函数 返回a数组排序后的数组

argsort(a) 返回a数组从小到大的排列在数组中的索引位置

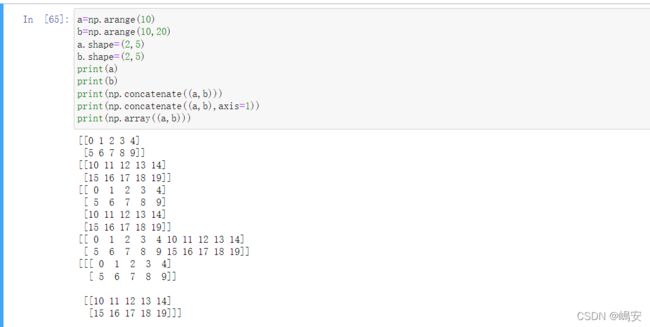
concatenate((a0,a1,...,aN),axis = 0) 返回连接后的数组
axis=0(默认) 以增加行的方式连接(第一维度)
axis=1 以增列行的方式连接(第二维度)
np.array((a0,a1,...,aN)) 返回第三维度连接后的数组
对应这三种情况的函数:
- vstack
- hstack
- dstack
Numpy 内置函数大全
np.sum(a) 求和
np.max(a)
np.min(a)
np.mean(a) 均值
np.std(a) 标准差
np.cov(a1,a2)相关系数矩阵
np.abs(a) 绝对值
np.exp(a) e的次幂数组
np.median(a) 中值
np.cumsum(a)累计和

================================================================================================================================================================================================================================================================================================= ================================================================================================================================================================================================================================================================================================= ================================================================================================================================================================================================================================================================================================= =============================================================================================================================================================================================================================================================================================================
- PANDAS [二]
Python Data Analysis Library 或 Pandas是基于Numpy的一种工具,该工具是为了解决数据分析任务而创建的。Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
Series
一维数组,与Numpy中的一维array类似。二者与Python基本的数据结构List也很接近。Series能保存不同种数据类型,字符串、boolean值、数字等都能保存在Series中。
DataFrame
二维的表格型数据结构。很多功能与R中的data.frame类似。可以将DataFrame理解为Series的容器。以下的内容主要以DataFrame为主。
import pandas as pd
import numpy as npSeries 初始化 index默认range(len(s))
s.index
s.values 可以返回s的索引与值(返回值及s可以切片)
s.index.name 可以返回s的index名字
通过赋值可以改变或添加名字

pd.date_range('日期',freq='D',periods)

pd.DataFrame()

除了向DataFrame中传入二维数组,我们也可以使用字典传入数据:
字典的每个key代表一列,其value可以是各种能够转化为Series的对象。
与Series要求所有的类型都一致不同,DataFrame只要求每一列数据的格式相同

df2.dtypes 返回各个列的数据类型

df.head(num=5)
df.tial(num=5) 返回最前面几行和最后面几行的数据(默认为5)

pd.read_excel() 使用pandas打开excel转换为DataFrame

df.loc[:]
df.iloc[:] loc——通过行标签索引行数据
iloc——通过行号索引行数据 
df.append() 添加一行 返回添加后的数据,并不会改变原来的数据

df.drop(inplace=False) 默认不改变原数据

双中括号索引:前面用两个中括号将想要的columns括起来,后面中括号表示只想看到的行数

增加一列

删除一列

条件选择

使用 & | 符号把用()括号括起来的条件同时筛选
返回条件符合的数据

缺失值及异常值处理
dropna根据标签中的缺失值进行过滤,删除缺失值
fillna对缺失值进行填充
isnull返回一个布尔值对象,判断哪些值是缺失值
notnullisnull的否定式
df.dropna(inplace=False) inplace默认False



数据保存
df.to_excel("1.xlsx")格式
df.dtype 返回数据格式
df.astype() 返回修改后的数据
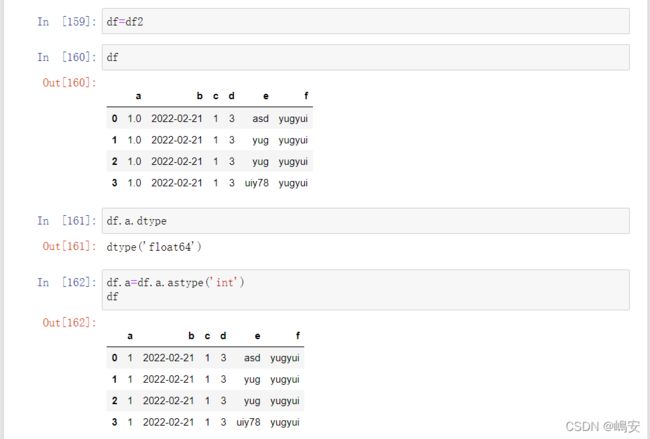
若是数据无法转换,则会报错,利用报错信息找出信息坐标,删除或更改成可以转换的数据



排序
df.sort_values() ascending默认为True(升序)

多个值排序(优先排前面的参数,在第一个参数同一等级里排下一个参数........)

描述性统计
df.describe()
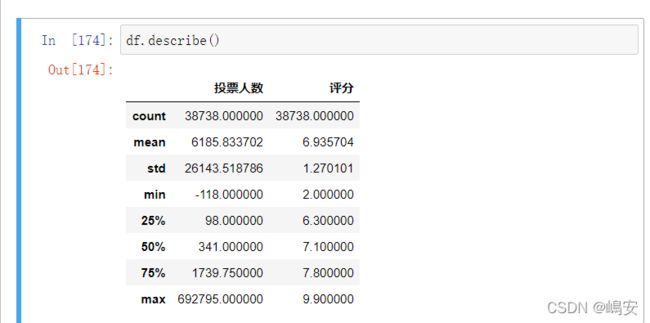
通过描述性统计,可以发现一些异常值,很多异常值往往是需要我们逐步去发现的。

其他操作

df.unique() 返回df.values 集合化后的数组 
df.replace(A,B) 第一个参数是要替换的值,第二个参数是替换后的值

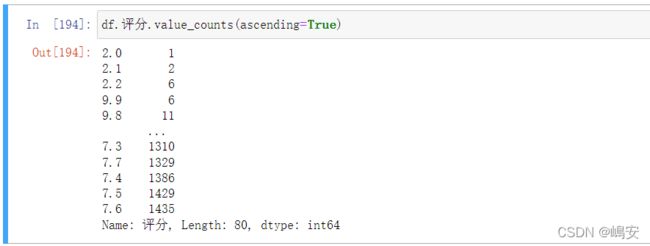
df.value_counts() 默认从大到小
Excel中数据透视表的使用非常广泛,其实Pandas也提供了一个类似的功能,名为pivot_table。
pivot_table非常有用,我们将重点解释pandas中的函数pivot_table。
使用pandas中的pivot_table的一个挑战是,你需要确保你理解你的数据,并清楚地知道你想通过透视表解决什么问题。虽然pivot_table看起来只是一个简单的函数,但是它能够快速地对数据进行强大的分析。
pd.set_option() 设置可展示的行和列,让数据进行完整展示

pd.pivot_table() 返回以index赋值后的数据为新index(索引),返回将剩下数据为数值的数据在新index的参考下(默认求平均数)的DataFrame

也可以有多个索引。实际上,大多数的pivot_table参数可以通过列表获取多个值

也可以指定需要统计汇总的数据;还可以指定函数,来统计不同的统计值
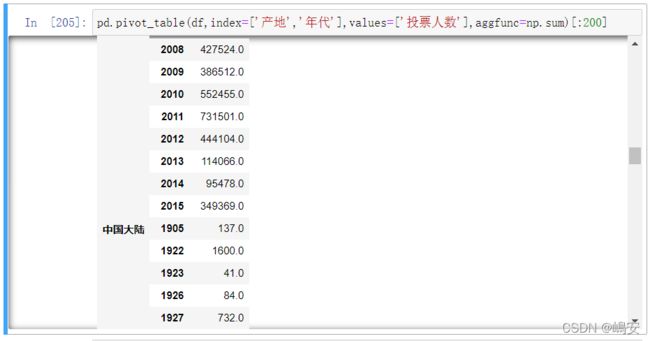
通过将“投票人数”列和“评分”列进行对应分组,对“产地”实现数据聚合和总结

对不同值执行不同的函数:可以向aggfunc传递一个字典。不过,这样做有一个副作用,那就是必须将标签做的更加整洁才行。

非数值(NaN)难以处理。如果想移除它们,可以使用“fill_value”将其设置为0。
则np.nan 变为0
margins=False (默认为False) 作用为求和

层次化索引是pandas的一项重要功能,它能使我们在一个轴上拥有多个索引。
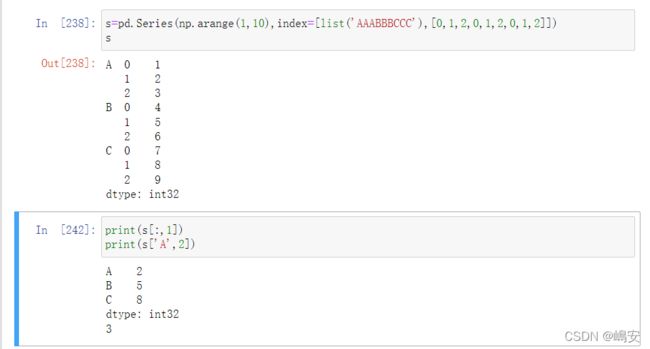
s.unstack()
通过unstack方法可以将Series变成一个DataFrame

s.stack() 进行unstack()相反操作

对于DataFrame来说,行和列都能进行层次化索引。

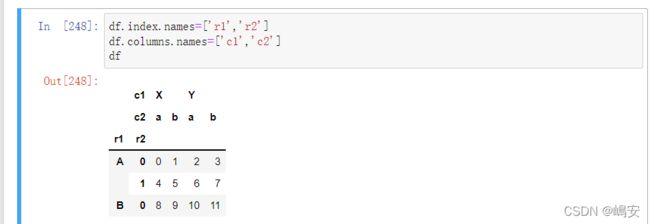
df.swaplevel(name1.name2) 返回将name1与name2位置进行调整的DataFrame
默认axis=0


set_index可以把列变成索引
reset_index是把索引变成列


DataFrame同样可以转置

dataframe也可以使用stack和unstack,转化为层次化索引的Series

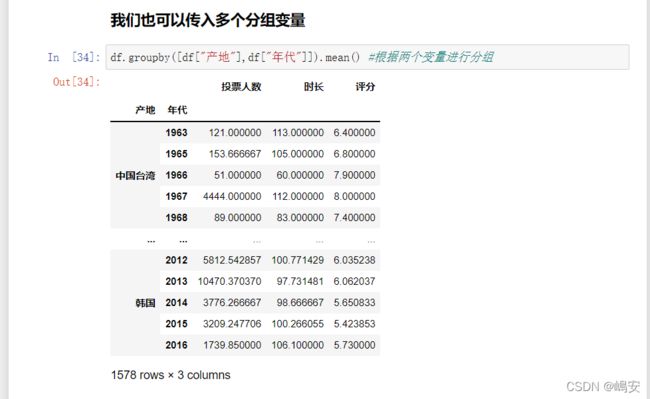
数据分组,分组运算
GroupBy技术:实现数据的分组,和分组运算,作用类似于数据透视表




离散化处理
离散化也可称为分组、区间化。
Pandas为我们提供了方便的函数cut():
pd.cut(x,bins,right = True,labels = None, retbins = False,precision = 3,include_lowest = False) 参数解释:
x:需要离散化的数组、Series、DataFrame对象
bins:分组的依据,right = True,include_lowest = False,默认左开右闭,可以自己调整。
labels:是否要用标记来替换返回出来的数组,retbins:返回x当中每一个值对应的bins的列表,precision精度。

合并数据集
( 1 )append

( 2 )merge
pd.merge(left, right, how = 'inner', on = None, left_on = None, right_on = None,
left_index = False, right_index = False, sort = True,
suffixes = ('_x', '_y'), copy = True, indicator = False, validate=None) left : DataFrame
right : DataFrame or named Series Object to merge with.
how : {'left', 'right', 'outer', 'inner'}, default 'inner' Type of merge to be performed.
* left: use only keys from left frame, similar to a SQL left outer join;
preserve key order.
* right: use only keys from right frame, similar to a SQL right outer join;
preserve key order.
* outer: use union of keys from both frames, similar to a SQL full outer
join; sort keys lexicographically.
* inner: use intersection of keys from both frames, similar to a SQL inner
join; preserve the order of the left keys.

( 3 )concat
将多个数据集进行批量合并

==================================================================================================================================================================================== ==================================================================================================================================================================================== ==================================================================================================================================================================================== ==================================================================================================================================================================================== ==================================================================================================================================================================================== ==================================================================================================================================================================================== ==================================================================================================================================================================================== =======================================================================================================================================================================================================
-
Matplotlib [ 三 ]
matplotlib是一个Python的 2D 图形包。pyplot封装了很多画图的函数
导入相关的包:
import matplotlib.pyplot as plt
import numpy as np
matplotlib.pyplot包含一系列类似MATLAB中绘图函数的相关函数。每个matplotlib.pyplot中的函数对当前的图像进行一些修改,例如:产生新的图像,在图像中产生新的绘图区域,在绘图区域中画线,给绘图加上标记,等等......matplotlib.pyplot会自动记住当前的图像和绘图区域,因此这些函数会直接作用在当前的图像上。
在实际的使用过程中,常常以plt作为matplotlib.pyplot的省略。
plt.show()函数
默认情况下,matplotlib.pyplot不会直接显示图像,只有调用plt.show()函数时,图像才会显示出来。
plt.show()默认是在新窗口打开一幅图像,并且提供了对图像进行操作的按钮。
不过在ipython命令中,我们可以将它插入notebook中,并且不需要调用plt.show()也可以显示:
%matplotlib notebook%matplotlib inline
不过在实际写程序中,我们还是习惯调用plt.show()函数将图像显示出来。
plt.plot()画折线图

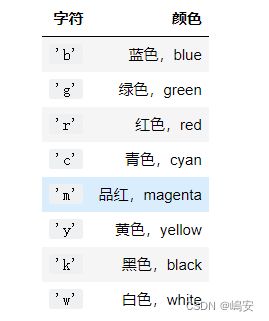
字符参数


这里可以使用axis函数指定坐标轴显示的范围:
plt.axis([xmin, xmax, ymin, ymax]) 
在一个图里面画多条线

之前提到,我们可以用字符串来控制线条的属性,事实上还可以用关键词来改变线条的性质,例如linewidth可以改变线条的宽度,color可以改变线条的颜色:

使用plt.plot()的返回值来设置线条属性
plot函数返回一个Line2D对象组成的列表,每个对象代表输入的一对组合,例如:
- line1,line2 为两个 Line2D 对象
line1, line2 = plt.plot(x1, y1, x2, y2) - 返回3个 Line2D 对象组成的列表
lines = plt.plot(x1, y1, x2, y2, x3, y3)
我们可以使用这个返回值来对线条属性进行设置:
line2.set_antialiased(False) 抗锯齿取消

plt.setp() 修改线条性质

figure()函数会产生一个指定编号为num的图:
plt.figure(num)这里,figure(1)其实是可以省略的,因为默认情况下plt会自动产生一幅图像。
使用subplot可以在一幅图中生成多个子图,其参数为:
plt.subplot(numrows, numcols, fignum)当numrows * numncols < 10时,中间的逗号可以省略,因此plt.subplot(211)就相当于plt.subplot(2,1,1)。

import warnings
warnings.filterwarnings("ignore") #关闭一些可能出现但对数据分析并无影响的警告
plt.rcParams["font.sans-serif"] = ["SimHei"] #解决中文字符乱码的问题
plt.rcParams["axes.unicode_minus"] = False #正常显示负号

柱状图(bar chart),是一种以长方形的长度为变量的表达图形的统计报告图,由一系列高度不等的纵向条纹表示数据分布的情况,用来比较两个或以上的价值(不同时间或者不同条件),只有一个变量,通常利用较小的数据集分析。柱状图亦可横向排列,或用多维方式表达
plt.figure(figsize = (a,b)) #设置图片大小
plt.bar(x,y,color = ) #绘制柱状图,表格给的数据是怎样就怎样,不会自动排序plt.title() #设置标题
plt.ylabel() #对横纵轴进行说明
plt.tick_params(labelsize = ) #设置标签字体大小
plt.xticks(rotation = 90) #标签转90度
for a,b in zip(x,y): #数字直接显示在柱子上(添加文本)
#a:x的位置,b:y的位置,加上10是为了展示位置高一点点不重合,
#第二个b:显示的文本的内容,ha,va:格式设定,center居中,top&bottom在上或者在下,fontsize:字体指定
plt.text(a,b+10,b,ha = "center",va = "bottom",fontsize = 10)
plt.grid() #画网格线,有失美观因而注释点


曲线图又称折线图,是利用曲线的升,降变化来表示被研究现象发展趋势的一种图形。它在分析研究社会经济现象的发展变化、依存关系等方面具有重要作用。
绘制曲线图时,如果是某一现象的时间指标,应将时间绘在坐标的横轴上,指标绘在坐标的纵轴上。如果是两个现象依存关系的显示,可以将表示原因的指标绘在横轴上,表示结果的指标绘在纵轴上,同时还应注意整个图形的长宽比例。

标记特殊点如极值点,xy设置箭头尖的坐标,xytext注释内容起始位置,arrowprops对箭头设置,传字典,facecolor填充颜色,edgecolor边框颜色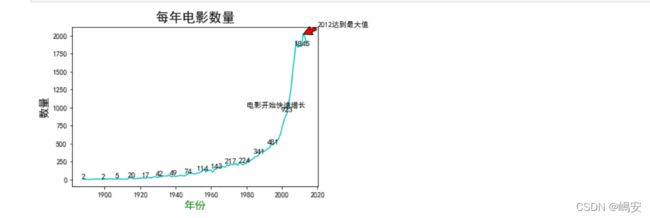
仅排列在工作表的一列或一行中的数据可以绘制到饼图中。饼图显示一个数据系列(数据系列:在图表中绘制的相关数据点,这些数据源自数据表的行或列。图表中的每个数据系列具有唯一的颜色或团并且在图表中的图例中表示。可以在图表中绘制一个或多个数据系列。饼图只有一个数据系列。)中各项的大小与各项总和的比例。饼图中的数据点(数据点:在图表中绘制的单个值,这些值由条形,柱形,折线,饼图或圆环图的扇面、圆点和其他被称为数据标记的图形表示。相同颜色的数据标记组成一个数据系列。)显示为整个饼图的百分比。
函数原型:
pie(x, explode = None, labels = None, colors = None, autopct = None, pctdistance = 0.6,
shadow = False, labeldistance = 1.1, startangle = None, radius = None)参数:
x: (每一块)的比例,如果sum(x)>1会使用sum(x)归一化
labels: (每一块)饼图外侧显示的说明文字
explode: (每一块)离开中心距离
startangle: 起始绘制角度,默认图是从x轴正方向逆时针画起,如设定=90则从y轴正方向画起
shadow: 是否阴影
labeldistance: label绘制位置,相对于半径的比例,如<1则绘制在饼图内侧
autopct: 控制饼图内百分比设置,可以使用format字符串或者format function
'%1.1f': 指小数点前后位数(没有用空格补齐)
pctdistance: 类似于labeldistance,指定autopct的位置刻度
radius: 控制饼图半径
返回值:
如果没有设置autopct,返回(patches,texts)
如果设置autopct,返回(patches,texts,autotexts)
plt.legend() #图例


直方图(Histogram)又称质量分布图。是一种统计报告图。由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。
直方图是数值数据分布的精确图形表示。这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。这些值通常被指定为连续的,不重叠的变量间隔。间隔必须相邻,并且通常是(但不是必须的)相等的大小。
直方图也可以被归一化以显示“相对频率”。然后,它显示了属于几个类别中每个案例的比例,其高度等于1。
hist的参数非常多,但常用的就这六个,只有第一个是必须的,后面可选
arr: 需要计算直方图的一维数组
bins: 直方图的柱数,可选项,默认为10
normed: 是否将得到的直方图向量归一化。默认为0
facecolor: 直方图颜色
edgecolor: 直方图边框颜色
alpha: 透明度
histtype: 直方图类型,"bar", "barstacked", "step", "stepfilled"
返回值:
n: 直方图向量,是否归一化由参数normed设定
bins: 返回各个bin的区间范围
patches: 返回每一个bin里面包含的数据,是一个lis

双轴图的画法
from scipy.stats import norm 获取正态分布密度函数
ax2 = ax1.twinx() 双轴


散点图
用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。散点图将序列显示为一组点。值由点在图表中的位置表示。类别由图表中的不同标记表示。散点图通常用于比较跨类别的聚合数据。
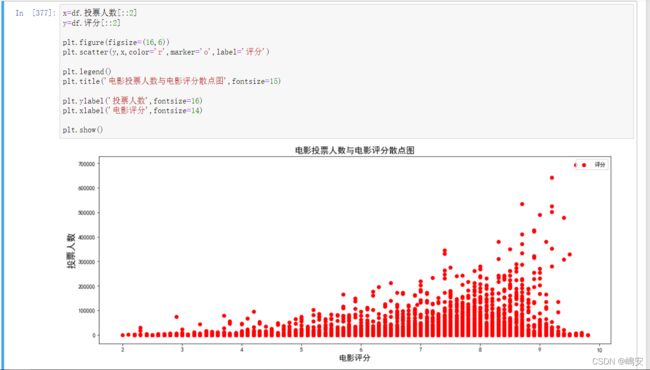
箱型图
箱型图(Box-plot)又称为盒须图,盒式图或箱型图,是一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。在各种领域中也经常被使用,常见于品质管理。它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较。箱线图的绘制方法是:先找出一组数据的中位数,两个四分位数,上下边缘线;然后,连接两个四分位数画出箱子;再将上下边缘线与箱子相连接,中位数在箱子中间。

一般计算过程
( 1 )计算上四分位数( Q3 ),中位数,下四分位数( Q1 )
( 2 )计算上四分位数和下四分位数之间的差值,即四分位数差(IQR, interquartile range)Q3-Q1
( 3 )绘制箱线图的上下范围,上限为上四分位数,下限为下四分位数。在箱子内部中位数的位置绘制横线
( 4 )大于上四分位数1.5倍四分位数差的值,或者小于下四分位数1.5倍四分位数差的值,划为异常值(outliers)
( 5 )异常值之外,最靠近上边缘和下边缘的两个值处,画横线,作为箱线图的触须
( 6 )极端异常值,即超出四分位数差3倍距离的异常值,用实心点表示;较为温和的异常值,即处于1.5倍-3倍四分位数差之间的异常值,用空心点表示
( 7 )为箱线图添加名称,数轴等
参数详解
plt.boxplot(x,notch=None,sym=None,vert=None,
whis=None,positions=None,widths=None,
patch_artist=None,meanline=None,showmeans=None,
showcaps=None,showbox=None,showfliers=None,
boxprops=None,labels=None,flierprops=None,
medianprops=None,meanprops=None,
capprops=None,whiskerprops=None,)x: 指定要绘制箱线图的数据;
notch: 是否是凹口的形式展现箱线图,默认非凹口;
sym: 指定异常点的形状,默认为+号显示;
vert: 是否需要将箱线图垂直摆放,默认垂直摆放;
whis: 指定上下须与上下四分位的距离,默认为为1.5倍的四分位差;
positions: 指定箱线图的位置,默认为[0,1,2...];
widths: 指定箱线图的宽度,默认为0.5;
patch_artist: 是否填充箱体的颜色;
meanline:是否用线的形式表示均值,默认用点来表示;
showmeans: 是否显示均值,默认不显示;
showcaps: 是否显示箱线图顶端和末端的两条线,默认显示;
showbox: 是否显示箱线图的箱体,默认显示;
showfliers: 是否显示异常值,默认显示;
boxprops: 设置箱体的属性,如边框色,填充色等;
labels: 为箱线图添加标签,类似于图例的作用;
filerprops: 设置异常值的属性,如异常点的形状、大小、填充色等;
medainprops: 设置中位数的属性,如线的类型、粗细等
meanprops: 设置均值的属性,如点的大小,颜色等;
capprops: 设置箱线图顶端和末端线条的属性,如颜色、粗细等;
whiskerprops: 设置须的属性,如颜色、粗细、线的类型等
plt.gca() 获取当时的坐标系
ax.patch.set_facecolor("gray") 设置坐标系背景颜色
ax.patch.set_alpha(0.x) 设置背景透明度

 相关系数矩阵图--热力图
相关系数矩阵图--热力图

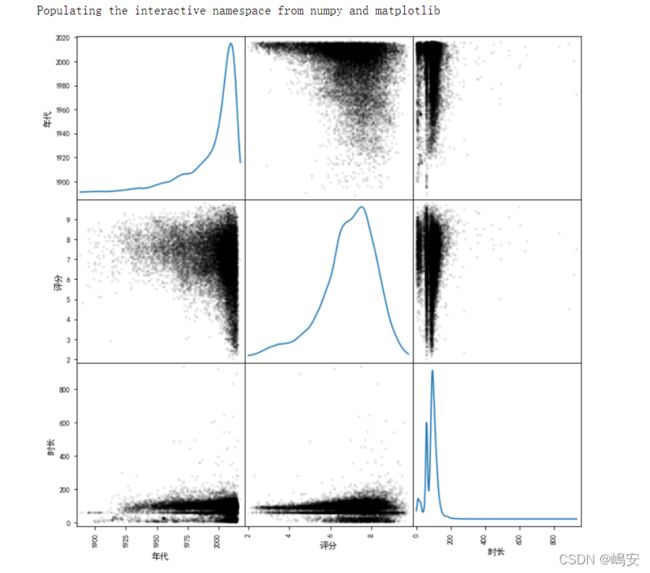


参数详解
sns.heatmap(data,vmin=None,vmax=None,cmap=None,center=None,robust=False,annot=None,fmt='.2g',annot_kws=None,linewidths=0,linecolor='white',cbar=True,cbar_kws=None,cbar_ax=None,square=False,xticklabels='auto',yticklabels='auto',mask=None,ax=None,**kwargs,)( 1 )热力图输入数据参数:
data:矩阵数据集,可以是numpy的数组(array),也可以是pandas的DataFrame。如果是DataFrame,则df的index/column信息会分别对应到heatmap的columns和rows,即pt.index是热力图的行标,pt.columns是热力图的列标。
( 2 )热力图矩阵块颜色参数:
vmax,vmin:分别是热力图的颜色取值最大和最小范围,默认是根据data数据表里的取值确定。cmap:从数字到色彩空间的映射,取值是matplotlib包里的colormap名称或颜色对象,或者表示颜色的列表;改参数默认值:根据center参数设定。center:数据表取值有差异时,设置热力图的色彩中心对齐值;通过设置center值,可以调整生成的图像颜色的整体深浅;设置center数据时,如果有数据溢出,则手动设置的vmax、vmin会自动改变。robust:默认取值False,如果是False,且没设定vmin和vmax的值。
( 3 )热力图矩阵块注释参数:
annot(annotate的缩写):默认取值False;如果是True,在热力图每个方格写入数据;如果是矩阵,在热力图每个方格写入该矩阵对应位置数据。fmt:字符串格式代码,矩阵上标识数字的数据格式,比如保留小数点后几位数字。annot_kws:默认取值False;如果是True,设置热力图矩阵上数字的大小颜色字体,matplotlib包text类下的字体设置;
( 4 )热力图矩阵块之间间隔及间隔线参数:
linewidth:定义热力图里“表示两两特征关系的矩阵小块”之间的间隔大小。linecolor:切分热力图上每个矩阵小块的线的颜色,默认值是"white"。
( 5 )热力图颜色刻度条参数:
cbar:是否在热力图侧边绘制颜色进度条,默认值是True。cbar_kws:热力图侧边绘制颜色刻度条时,相关字体设置,默认值是None。cbar_ax:热力图侧边绘制颜色刻度条时,刻度条位置设置,默认值是None
( 6 )
square:设置热力图矩阵小块形状,默认值是False。xticklabels,yticklabels:xticklabels控制每列标签名的输出;yticklabels控制每行标签名的输出。默认值是auto。如果是True,则以DataFrame的列名作为标签名。如果是False,则不添加行标签名。如果是列表,则标签名改为列表中给的内容。如果是整数K,则在图上每隔K个标签进行一次标注。