python网页爬虫selenium与csv文件写入储存应用
一、工具准备
在库中加入selenium
为了用它控制网站
要安装一个chromedriver
这里加的是他的一个低版本
因为新版本有些地方仍然不兼容
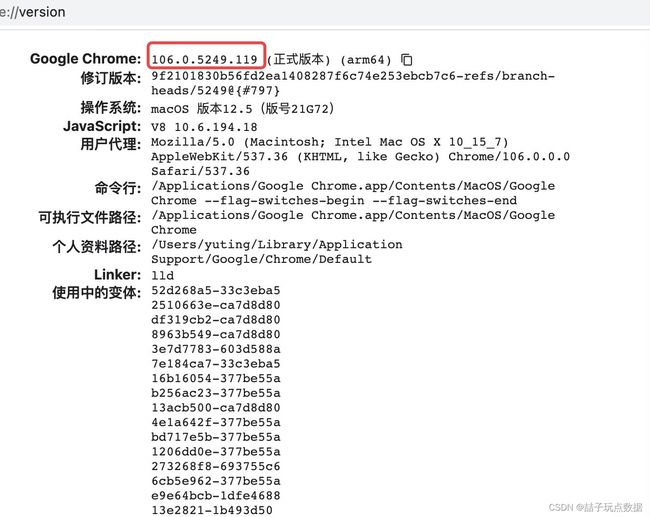
1.获取当前谷歌浏览器版本信息:chrome://version/
用谷歌浏览器登录上面网站获得自己的谷歌浏览器版本
在下面网址下载chromedriver
chromedriver下载地址:http://chromedriver.storage.googleapis.com/index.html
选取一个最近的版本,即与你的版本最近的
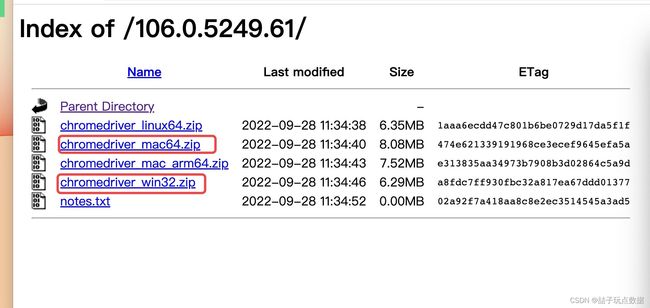
下载文件,解压
放入python安装目录
就可以使用了
用下面代码测试,能不能打开谷歌浏览器
from selenium.webdriver import Chrome
b = Chrome()
b.get('https://www.baidu.com')
如果运行完了,跳出谷歌浏览器就是成功安装工具
二、csv文件操作
1. 什么是csv文件 - 逗号分隔值文件
一种后缀是.csv的文本文件,文件中每一行通过逗号分割成不同的列。
csv可以用excel软件像打开excel文件一样去打开。
导入库
import csv
2. csv文件读操作
1)创建reader
csv.reader(文件对象) - 创建reader获取文件内容,文件内容每一行一个列表的形式返回
csv.DictReader(文件对象) - 创建reader获取文件内容,文件内容每一行一个字典,并且将第一行的数据作为键的形式返回
f = open('files/电影.csv', 'r', encoding='utf-8', newline='')
# reader = csv.reader(f)
reader = csv.DictReader(f)
# reader获取文件内容,将每一行内容作为一个**迭代器**中的元素返回
```python
print(next(reader))
print(next(reader))
print(list(reader))
f.close()
3. csv文件写操作
1)创建一个writer
csv.writer(文件对象) - 写入数据的时候每一行数据对应一个列表
writer1 = csv.writer(open('files/students1.csv', 'w', encoding='utf-8', newline=''))
2)写入数据
一次写一行
writer1.writerow(['姓名', '年龄', '性别', '电话'])
writer1.writerow(['小明', 18, '男', '110'])
一次写入多行数据
writer1.writerows([
['小花', 20, '女', '120'],
['张三', 30, '男', '119']
])
csv.DictWriter(文件对象, 键列表)
writer2 = csv.DictWriter(open('files/students2.csv', 'w', encoding='utf-8', newline=''), ['姓名', '年龄', '性别', '电话'])
将字典的键作为第一行内容写入到文件中
writer2.writeheader()
一次写入一行数据
writer2.writerow({'姓名': '小明', '年龄': 18, '性别': '男', '电话': '110'})
writer2.writerow({'姓名': '小花', '年龄': 20, '性别': '女', '电话': '120'})
一次写入多行数据
writer2.writerows([
{'姓名': '小红', '年龄': 22, '性别': '女', '电话': '119'},
{'姓名': '张三', '年龄': 30, '性别': '男', '电话': '120'}
])
三、selenium基本语法
from selenium.webdriver import Chrome
from bs4 import BeautifulSoup
1. 创建浏览器打开网页
b = Chrome()
b.get('https://cd.zu.ke.com/zufang')
2. 获取网页源代码
html = b.page_source
3. 关闭浏览器
b.close()
4.解析数据
soup = BeautifulSoup(html, 'lxml')
result = soup.select('.twoline')
for x in result:
print(x.text.strip())
5关闭图片加载
options.add_experimental_option(“prefs”, {“profile.managed_default_content_settings.images”: 2})
6取消测试环境
options.add_experimental_option(‘excludeSwitches’, [‘enable-automation’])
四、selenium输入与点击控制
from selenium.webdriver import Chrome
1. 创建浏览器打开页面
b = Chrome()
b.get('https://www.jd.com/')
2.通过浏览器获取想要控制的标签
b.find_element_by_id(id属性值) - 获取当前页面中id属性值为指定值的标签
b.find_element_by_class_name(class属性值) - 获取当前页面中class属性值为指定值的第一个标签
b.find_element_by_css_selector(css选择器) - 在当前页面中获取css选择器选中的第一个标签
b.find_elements_by_class_name(class属性值) - 获取当前页面中所有class属性值为指定值的标签, 返回一个列表
b.find_elements_by_css_selector(css选择器) - 在当前页面中获取css选择器选中的所有标签,返回一个列表
input_tag = b.find_element_by_id('key')
seckill = b.find_elements_by_class_name('navitems-lk')[2]
3. 操作标签
标签对象.click() - 点击指定标签
seckill.click()
标签对象.send_keys(想要输入的内容) - 控制输入框输入指定内容
input_tag.send_keys(‘电脑\n’)
seckill.click()
五、selenium滚动操作
from selenium.webdriver import Chrome
from time import sleep
from bs4 import BeautifulSoup
b = Chrome()
b.get('https://search.jd.com/Search?keyword=%E7%94%B5%E8%84%91&enc=utf-8&wq=%E7%94%B5%E8%84%91&pvid=fa66f90b245d40e5aa3f868a7471d539')
1. 让页面滚动: 浏览器对象.execute_script(‘window.scrollBy(x方向偏移量, y方向偏移量)’)
for _ in range(10):
b.execute_script('window.scrollBy(0, 800)')
sleep(1)
soup = BeautifulSoup(b.page_source, 'lxml')
all_li = soup.select('#J_goodsList>ul>li')
print(len(all_li))
b.close()
六、selenium选项卡操作
from selenium.webdriver import Chrome
from time import sleep
b = Chrome()
b.get('https://www.cnki.net/')
获取输入框
search = b.find_element_by_id('txt_SearchText')
search.send_keys('数据分析\n')
sleep(1)
获取所有搜索结果对应的标签
all_a = b.find_elements_by_css_selector('.result-table-list tr>td.name>a')
点击第一个a标签
all_a[0].click()
sleep(1)
切换窗口到第二个窗口中
b.window_handles - 获取当前浏览器中所有的选卡
b.switch_to.window(b.window_handles[-1])
b.close()
回到第一个窗口
b.switch_to.window(b.window_handles[0])
点击第二个a标签
sleep(1)
all_a[1].click()
``