深度学习笔记-遥感影像转为tensor前的检查及线性拉伸
@TOC
前言-为什么要做线性拉伸
近期在开展语义分割任务,用到的数据是经过SNAP预处理的Sentinel-1的SAR数据。工作需要将相关的Image和label送入模型,进行目标地物的分割。
这里用到的深度学习框架是pytorch,需要将影像数据转换为tensor后送入model。转换为tensor之前,需要对image和label的存储格式进行检查。为什么呢?这里就需要知道transforms.ToTensor对数据做了什么?
一、transforms.ToTensor
transforms.ToTensor会把一个取值范围是[0,255]的PIL.Image或者shape为(H,W,C)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的tensor。
需要注意,由于transforms.ToTensor最早适用于RGB三波段图像的处理,采用的存储是8位存储,所以这里简单使用了img/255的操作使图像取值范围保持在[0,1]。
而由于遥感影像有的是16位甚至32位存储,所以我们需要在image和label转换为tensor之前,保证image是8位存储,数值范围在[0,255]之间。这里采用的方法是线性拉伸
二、线性拉伸
对数据进行信息查看
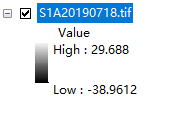
可以看到Image的取值范围是[-39.9612,29.688],我们查看一下数值的分布。

可以看到,Image数值似乎是个双峰的正态分布,先不管他。由于影像中数值是最大最小值的像素数量非常少,我们就不能简单的用最大最小值作为0和255的对应值,否则可能会造成数据偏移。这就需要找到一个相对合理的最大最小值作为0和255的对应值。
这里用到一个numpy函数来判断怎么找合适的比例对影像数值进行“掐头去尾”,从而找到0和255合理的对应值。函数为np.percentile(),它将像素从小到大排列,通过np.percentile(data,percentage)查看当前的数值是多少。比如np.percentile(Image,0.05)就是查询这幅影像排列在0.05%位置处的像素数值,这幅影像0.05和99.95处大概是-34和-6。
附上代码如下,代码来源于师弟WZQ。
import numpy as np
import gdal
# 读取tif数据集
def readTif(fileName, xoff=0, yoff=0, data_width=0, data_height=0):
dataset = gdal.Open(fileName)
if dataset == None:
print(fileName + "文件无法打开")
# 栅格矩阵的列数
width = dataset.RasterXSize
# 栅格矩阵的行数
height = dataset.RasterYSize
# 波段数
bands = dataset.RasterCount
# 获取数据
if (data_width == 0 and data_height == 0):
data_width = width
data_height = height
data = dataset.ReadAsArray(xoff, yoff, data_width, data_height)
# 获取仿射矩阵信息
geotrans = dataset.GetGeoTransform()
# 获取投影信息
proj = dataset.GetProjection()
return width, height, bands, data, geotrans, proj
# 保存tif文件函数
def writeTiff(im_data, im_geotrans, im_proj, path):
if 'int8' in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif 'int16' in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
elif len(im_data.shape) == 2:
im_data = np.array([im_data])
im_bands, im_height, im_width = im_data.shape
# 创建文件
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(path, int(im_width), int(im_height), int(im_bands), datatype)
if (dataset != None):
dataset.SetGeoTransform(im_geotrans) # 写入仿射变换参数
dataset.SetProjection(im_proj) # 写入投影
for i in range(im_bands):
dataset.GetRasterBand(i + 1).WriteArray(im_data[i])
del dataset
def truncated_linear_stretch(image, truncated_value, max_out=255, min_out=0):
def gray_process(gray):
truncated_down = np.percentile(gray, truncated_value)
truncated_up = np.percentile(gray, 100 - truncated_value)
gray = (gray - truncated_down) / (truncated_up - truncated_down) * (max_out - min_out) + min_out
gray[gray < min_out] = min_out
gray[gray > max_out] = max_out
if (max_out <= 255):
gray = np.uint8(gray)
elif (max_out <= 65535):
gray = np.uint16(gray)
return gray
# 如果是多波段
if (len(image.shape) == 3):
image_stretch = []
for i in range(image.shape[0]):
gray = gray_process(image[i])
image_stretch.append(gray)
image_stretch = np.array(image_stretch)
# 如果是单波段
else:
image_stretch = gray_process(image)
return image_stretch
fileName = r"D:\Craft_S1_Dataset\Data\RawData\S1A20190718.tif"
SaveName = r"D:\Craft_S1_Dataset\Data\Test_data\RawData\S1A20190718_0.05%.tif"
width, height, bands, data, geotrans, proj = readTif(fileName)
data_stretch = truncated_linear_stretch(data, 0.05)
writeTiff(data_stretch, geotrans, proj, SaveName)
print("程序完成")
拉伸后的图像数值和比例分布为

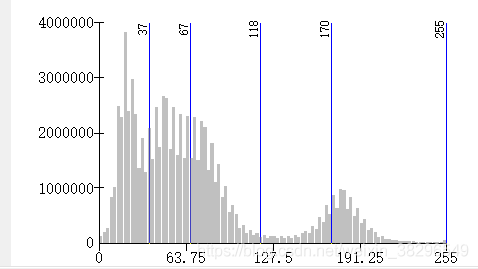
可以看到,数值变化到了[0,255],像素分布形状变化不大,可以用来制作训练用的影像了。
总结
- 拿到数据进行样本制作时要检查数据格式是否符合8位存储,数值是否在[0,255]之间。
- 观察数据的像素分布是否合理,是否需要“掐头去尾”进行按比例线性拉伸。