使用OkHttp 下载文件无进度回调 踩坑
一、踩坑速记
1. 未添加header指定服务器采用何种压缩方式导致下载进度异常
描述:使用OkHttp3执行文件下载(服务端有nginx反向代理服务器进行压缩),获取回调中文件总大小为0或负值,导致显示下载进度异常。
1.1 前端解决方案
添加请求头addHeader("Accept-Encoding", "application/octet-stream")或者addHeader("Accept-Encoding", "*") 即可;
addHeader("Accept-Encoding", "application/octet-stream");
addHeader("Accept-Encoding", "*");1.2 后端解决方案
服务端需要下载的文件更改为.bin后缀(nginx未对bin文件进行压缩,此时返回的数据格式默认是二进制流),当然这样的前提是前端知道要下载的文件是个什么文件,下载完成要自行命名修改后缀为正常后缀,如.apk文件。
2. okhttp请求设置了log拦截器导致下载异常
描述:如果在初始化OkHttpClient 时设置了log拦截器,而且呢设置了HttpLoggingInterceptor.Level = Level.BODY时,会发现监听不到下载的进度了。(文件明明已经在开始下载,但没有进度回调,或者文件下载很长一段时间后才有进度回调)。
2.1 去掉HttpLoggingInterceptor拦截
注释掉HttpLoggingInterceptor的log拦截即可。
//.addInterceptor(mInterceptor);2.2 设置log级别比BODY级别更低
mInterceptor.setLevel(HttpLoggingInterceptor.Level.BASIC);
mInterceptor.setLevel(HttpLoggingInterceptor.Level.HEADERS);
mInterceptor.setLevel(HttpLoggingInterceptor.Level.NONE);3. 不继续踩坑的下载库
https://github.com/lingochamp/okdownload/
二、踩坑记录
1. 坑一 Header详细解析
1.1 OkHttp下载文件-Header坑的产生
很久很久以前,具体多久已经记不太清楚了,只记得那是第一次把项目中的请求换成OkHttp,发版之后突然接到客服反馈说用户升级app一直失败,然后抓紧调试以下,发现真的是执行app更新时,发现一直不显示文件大小和进度,已下载文件大小一直是负的,最终下载完成的文件执行安装还会是失败报错;一下子就慌了。
1.2 问题分析
由于过去的时间过于“久远”,分析问题的具体步骤就不可能详细描述了,只记得是用fiddler监控下载过程;尝试下载别的文件如百度/应用宝上的apk文件;分析返回的文件内容和格式。网络管理员、运维、经理、技术总监都参与到了问题的分析讨论和解决方案的制订。
这里说下最后敲定的问题原因:
- 由于前端升级后不久,nginx也针对网络优化做了一次升级,那么nginx会默认对文件进行压缩以节省网络宽带,并减少网络延迟;而且呢我们的okhttp下载请求没有设置Accept-Encoding指定返回的数据格式,所以此时nginx默认gzip格式压缩返回的Content-Type是text/plain;charset=utf-8即当成文本了;
- 那么现在okhttp下载器接到的是text文本,相当于把本是apk的文件流转成了text文本传输,这边把文本当文件流再写入到了一个文件里,最后这个文件还能安装吗?哈哈,不能!
1.3 解决方案
上面分析了是nginx把apk文件流当成text文件进行了压缩传输,那么前端请求时主动告诉后台我要的是个什么文件,这样可以吗?
答案是肯定的:通过设置addHeader("Accept-Encoding", "application/octet-stream"),可以指定返回的数据格式是二进制流文件,此时再去执行下载,已经可以正常执行了。后面又尝试了设置支持所有类型("Accept-Encoding", "*"),也是可以的。
本地的代码可以该,那么已经上线的版本怎么处理呢?最后是经理去分析了nginx反向代理的一些配置和流程,发现可以在某个目录下的bin文件不被压缩,于是尝试了将apk文件后缀修改成bin文件,升级到服务器上,将旧版本升级的路径指向了新配置的bin文件,完美的解决了旧版本的更新问题。
2. 坑二HttpLoggingInterceptor详细解析
2.1 OkHttp下载文件-log坑的产生
前几天,网约车的部门经理找我说他手机上司机端升级一直下不下来,因为很久没有提过下载的问题,也没有动下载的代码,没有怀疑是代码问题,所以怀疑是网的问题(ps:公司的公网的网速一直不怎么样)。然后我去拿我手机上模拟器跑一下,发现也好久没见进度往前走,啧啧~想到之前的坑,不会老坑重踩了把。。。赶紧拉代码看了一遍,还好,没有改动记录,header也都设置了,所以不是之前的问题。那么这次又是什么问题呢?
2.2 问题分析
前面简单说了肯定不是header的问题了,于是开始从别的方面找原因。
2.2.1 服务端配置导致文件获取不到文件大小,所以进度无法获取
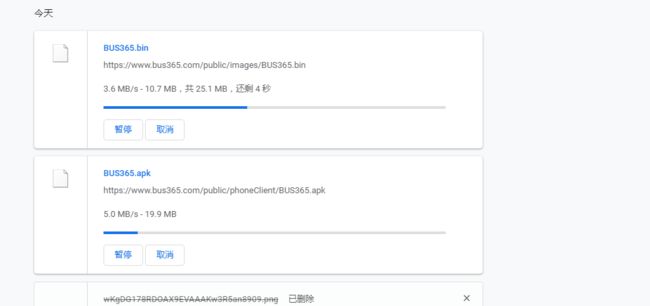
由于上次跟服务端的nginx反向代理有关,所以这次也优先想到了先排查后端的问题。先咨询了负责运维的同事,表示最近没有升级,但是呢我对比了两个文件在浏览器(360和chrome)的下载过程,如下图所示,BUS365.apk和BUS365.bin是同样大的都是25.1M,但是bin文件可以看到正常的进度和文件总大小,apk文件下载进度异常而且无法获取文件总大小。(从百度手机助手链接下载apk文件同下图中bin文件表现一致,可以显示文件总大小和下载进度)
https://www.bus365.com/public/images/BUS365.bin
https://www.bus365.com/public/phoneClient/BUS365.apk


2.2.2 不是nginx的原因,是主站服务器告诉nginx要返回的什么数据格式,nginx只是代理转发
网络运维的同事也非常辛苦地配合着自己研究了一上午的时间,最后给我的结果是:“nginx是中间做了转发代理,并不决定返回的数据格式,还得看主站服务,咱们一起去找主站看看把。”(下图中的ContentType是返回结果中的文件格式)。
https://www.bus365.com/public/phoneClient/BUS365.apk

https://www.bus365.com/public/images/BUS365.bin

2.2.3 主站只负责业务处理,具体的返回规则是play框架决定的
这次负责主站服务的同事倒是很快给出了结论:“主站只负责业务处理,具体的哪个目录下的文件压缩,支持哪个格式的文件(apk,bin等)不压缩,这些返回规则是play框架决定的,得找技术总监决定修改play框架!”好吧,我们越来越接近业务的“核心”了。。。。。。但是,我只是想,在下载安装包时,能够获取到文件大小和进度的显示啊,我感觉已经越走越远了,有木有?!!!
2.2.4 突发奇想,不上传主站,上传到专门的文件服务器
万分感谢辛苦的运维同事和主站后台服务同事的配合,回去边写邮件想着怎么去说动技术总监去改play框架来满足咱们的需求,边跟经理交流下这个问题,经理提出来可以先把安装包传文件服务器试一下,这简单啊,又不费啥事儿,马上传上去,得到文件服务器上的下载路径。https://mraw.bus365.cn/files/group1/M00/00/F8/wKgDEl-X5nGAQMxkAe7MXjwMMyU347.apk,嘿,在浏览器下载真的有进度和总大小了。

2.2.5 以为找到了钥匙,却打不开“紧闭的大门”
满心欢喜以为,安装包上传文件服务器就可以圆满解决问题了,跟运维沟通后得知:1,文件服务器没有做cdn缓存,所以下载速度并不快;2,文件服务器每次上传都是新地址,旧的不会自动删除,不建议放大文件,更何况需要大批量的下载的升级类文件;3,更重要的时,当我把文件服务器的下载链接放到司机端中执行下载时,依然很久没有进度回调。。。
2.2.6 柳暗花明又一村,找到真正的原因
搜okhttp下载进度关键词时,看到了这篇浏览量极小的文章:okHttp3 下载进度监听 踩坑https://blog.csdn.net/boxing012/article/details/105316216,文中提到了
如果在初始化OkHttpClient 时设置了log拦截器,不管拦截器的级别是什么,监听到的进度都不正常(文件已经在开始下载,但没有进度回调,文件下载一段时间后才有进度)
当然这段话还是有一定问题的,后面分析会说明,不过有一点时对的,就是okHttpClient设置了log拦截器后,会导致进度回调失败。回头看司机端的初始化代码中,确实发现有设置HttpLoggingInterceptor,当注释掉.addInterceptor(logging)后,下载更新的进度就正常了。
HttpLoggingInterceptor logging = new HttpLoggingInterceptor();
logging.setLevel(HttpLoggingInterceptor.Level.BODY);
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.connectTimeout(GlobalUrlConfig.HTTP_TIMEOUT, TimeUnit.MILLISECONDS)
.readTimeout(GlobalUrlConfig.HTTP_TIMEOUT, TimeUnit.MILLISECONDS)
.addInterceptor(logging)
.hostnameVerifier(new HostnameVerifier() {
@Override
public boolean verify(String hostname, SSLSession session) {
return true;
}
})
.build();
OkHttpUtils.initClient(okHttpClient);2.2.7 问题原因找到了,分析下HttpLoggingInterceptor为什么会导致下载进度失败呢?
既然问题出现在HttpLoggingInterceptor身上,肯定需要分析HttpLoggingInterceptor的源码,其它地方就先不用看了,直接看intercept();
@Override
public Response intercept(Chain chain) throws IOException {
Level level = this.level;
Request request = chain.request();
if (level == Level.NONE) {
return chain.proceed(request);
}
boolean logBody = level == Level.BODY;
boolean logHeaders = logBody || level == Level.HEADERS;
RequestBody requestBody = request.body();
boolean hasRequestBody = requestBody != null;
Connection connection = chain.connection();
String requestStartMessage = "--> "
+ request.method()
+ ' ' + request.url()
+ (connection != null ? " " + connection.protocol() : "");
if (!logHeaders && hasRequestBody) {
requestStartMessage += " (" + requestBody.contentLength() + "-byte body)";
}
logger.log(requestStartMessage);
if (logHeaders) {
if (hasRequestBody) {
// Request body headers are only present when installed as a network interceptor. Force
// them to be included (when available) so there values are known.
if (requestBody.contentType() != null) {
logger.log("Content-Type: " + requestBody.contentType());
}
if (requestBody.contentLength() != -1) {
logger.log("Content-Length: " + requestBody.contentLength());
}
}
Headers headers = request.headers();
for (int i = 0, count = headers.size(); i < count; i++) {
String name = headers.name(i);
// Skip headers from the request body as they are explicitly logged above.
if (!"Content-Type".equalsIgnoreCase(name) && !"Content-Length".equalsIgnoreCase(name)) {
logHeader(headers, i);
}
}
if (!logBody || !hasRequestBody) {
logger.log("--> END " + request.method());
} else if (bodyHasUnknownEncoding(request.headers())) {
logger.log("--> END " + request.method() + " (encoded body omitted)");
} else {
Buffer buffer = new Buffer();
requestBody.writeTo(buffer);
Charset charset = UTF8;
MediaType contentType = requestBody.contentType();
if (contentType != null) {
charset = contentType.charset(UTF8);
}
logger.log("");
if (isPlaintext(buffer)) {
logger.log(buffer.readString(charset));
logger.log("--> END " + request.method()
+ " (" + requestBody.contentLength() + "-byte body)");
} else {
logger.log("--> END " + request.method() + " (binary "
+ requestBody.contentLength() + "-byte body omitted)");
}
}
}
long startNs = System.nanoTime();
Response response;
try {
response = chain.proceed(request);
} catch (Exception e) {
logger.log("<-- HTTP FAILED: " + e);
throw e;
}
long tookMs = TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - startNs);
ResponseBody responseBody = response.body();
long contentLength = responseBody.contentLength();
String bodySize = contentLength != -1 ? contentLength + "-byte" : "unknown-length";
logger.log("<-- "
+ response.code()
+ (response.message().isEmpty() ? "" : ' ' + response.message())
+ ' ' + response.request().url()
+ " (" + tookMs + "ms" + (!logHeaders ? ", " + bodySize + " body" : "") + ')');
if (logHeaders) {
Headers headers = response.headers();
for (int i = 0, count = headers.size(); i < count; i++) {
logHeader(headers, i);
}
if (!logBody || !HttpHeaders.hasBody(response)) {
logger.log("<-- END HTTP");
} else if (bodyHasUnknownEncoding(response.headers())) {
logger.log("<-- END HTTP (encoded body omitted)");
} else {
BufferedSource source = responseBody.source();
source.request(Long.MAX_VALUE); // Buffer the entire body.
Buffer buffer = source.buffer();
Long gzippedLength = null;
if ("gzip".equalsIgnoreCase(headers.get("Content-Encoding"))) {
gzippedLength = buffer.size();
GzipSource gzippedResponseBody = null;
try {
gzippedResponseBody = new GzipSource(buffer.clone());
buffer = new Buffer();
buffer.writeAll(gzippedResponseBody);
} finally {
if (gzippedResponseBody != null) {
gzippedResponseBody.close();
}
}
}
Charset charset = UTF8;
MediaType contentType = responseBody.contentType();
if (contentType != null) {
charset = contentType.charset(UTF8);
}
if (!isPlaintext(buffer)) {
logger.log("");
logger.log("<-- END HTTP (binary " + buffer.size() + "-byte body omitted)");
return response;
}
if (contentLength != 0) {
logger.log("");
logger.log(buffer.clone().readString(charset));
}
if (gzippedLength != null) {
logger.log("<-- END HTTP (" + buffer.size() + "-byte, "
+ gzippedLength + "-gzipped-byte body)");
} else {
logger.log("<-- END HTTP (" + buffer.size() + "-byte body)");
}
}
}
return response;
}我们注意到
requestBody.writeTo(buffer);
source.request(Long.MAX_VALUE); // Buffer the entire body.这两行,一个是操作请求的body,一个是操作结果的body,后一行操作结果的地方还给了一个最大值。这会有什么问题呢,如果你在这里打断点会发现,下载文件的请求,走到这里竟然“不执行了”,其实是卡在这里了(至于为什么没有卡死UI,因为是开启了线程执行的)。这里需要将内容全部请求出来,然后方便后面的复制buffer,然而在你下载东西的时候,内容是很多的(几M,几十M,甚至几百M),那么这里的卡住的时长和文件大小成正比,如果文件太大,内存不够,那么系统会不停地GC去获取更多内存,甚至可能会发生OOM。这就是为什么一直没有进度回调的原因了,因为:这里日志还没打印完成,而日志打印完成的前提是文件下载完成,所以直到文件完成下载,你才有可能接收到进度的回调(同理:打印requestbody会影响上传进度回调)。


再往上看logBody是何许人也?logBody是判断打印的level是否是Level.BODY,所以,当你设置级别为header、basic、none时,代码执行到上面的条件ogger.log("<-- END HTTP");就不会执行body的复制和打印了,进而不会产生下载进度条不变的问题了。

2.3 解决方案
上面分析了是HttpLoggingInterceptor拦截了body去执行打印去了,影响了进度的回调,所以解决方案也很简单:1,取消log拦截器(addInterceptor);2,设置更低级别的拦截(HttpLoggingInterceptor.Level.BASIC)。两个方案都可以很好的解决这个问题。
HttpLoggingInterceptor logging = new HttpLoggingInterceptor();
logging.setLevel(HttpLoggingInterceptor.Level.BASIC);
OkHttpClient okHttpClient = new OkHttpClient.Builder()
.connectTimeout(GlobalUrlConfig.HTTP_TIMEOUT, TimeUnit.MILLISECONDS)
.readTimeout(GlobalUrlConfig.HTTP_TIMEOUT, TimeUnit.MILLISECONDS)
//.addInterceptor(logging)
.hostnameVerifier(new HostnameVerifier() {
@Override
public boolean verify(String hostname, SSLSession session) {
return true;
}
})
.build();
OkHttpUtils.initClient(okHttpClient);但是某个人就会问了:HttpLoggingInterceptor这么方便的拦截器,我用来打印后台返回的结果多方便啊,这body都不让拦截了,不行我就想要用!呵呵,没遭遇过社会的毒打。
那么能不能满足某个人的需求呢,当然可以:就是定义两个OkHttpClient实例对象,一个专门用来下载文件,这个不加拦截器,或者HttpLoggingInterceptor的level < Body就好了;另外一个专门处理网络请求的添加BODY级别的拦截器去处理服务器返回的数据,这样就没有问题了。
三、脱坑推荐
下载文件作为APP中最常用的功能之一,在github上已经有非常成熟的开源框架,不喜欢踩坑的可以尝试站在“巨人”的肩膀上去鸟瞰整个世界。这里推荐一个稳定、高效、灵活、简单易用的Android 文件下载引擎。单一个下载功能的安卓库,星星数都能破万,已经无需再去介绍它的魅力,直接移步github去试用即可。
1代地址:https://github.com/lingochamp/FileDownloader
2代地址:https://github.com/lingochamp/okdownload/
特点:
- 简单易用
- 单任务多线程/多连接/分块下载(并支持通过
ConnectionCountAdapter定制) - 高并发
- 灵活
- 可选择性支持: 独立/非独立进程
- 自动断点续传
参考
https://blog.csdn.net/sese12138/article/details/106019355
https://blog.csdn.net/boxing012/article/details/105316216