<<视觉问答>>2021:How Transferable are Reasoning Patterns in VQA?

目录
摘要:
一、介绍
二、相关工作
三、Analysis of Reasoning Patterns
3.1. Visual noise vs. models with perfect-sight
3.3、Attention modes and task functions
摘要:
视觉问答(VQA)任务因为具有语言偏差和捷径偏差的问题,往往会阻碍模型学习真正的依靠图像进行推理。经典的模型通过从训练集中去除偏差数据,或者在模型里添加问题分支来消除偏差。本文作者认为视觉的不确定性是阻碍视觉语言任务中成功学习推理的主要因素。作者训练一个visual oracle(指将问题和一组直接取自GQA数据集的ground truth对象作为输入,它允许评估一个模型的性能,而没有视觉提取器的缺陷,因为视觉特征提取不一定能提取到与问题直接相关的区域特征)在大量研究中提供了实验证据,与标准模型相比,这个模型更不容易利用虚假的语言偏见。作者建议研究visual oracle中工作的注意机制,并将其与基于SOTA transformer的模型进行比较。通过一个公开的在线可视化工具提供了对推理模式的深入分析和可视化。作者通过将推理模式从oracle转移到基于SOTA transformer的VQA模型,通过微调获取标准的噪声视觉输入,从而利用这些见解。在实验中,作者报告了更高的总体准确性,以及对每个问题类型的不常见答案的准确性,这为改进泛化和减少对数据集偏见的依赖提供了证据。
一、介绍
大规模数据训练的大模型获得的高预测性能可能导致了关于这些改进的性质的问题。视觉问答已经成为评估模型推理和泛化能力的任务,因为它将多种异构性质的输入与多种类别的开放问题相结合。
在这项工作中,作者研究了VQA模型“推理”的能力,将推理解释为利用训练数据中的虚假偏见的对立面。在第3节将提供证据,当视觉输入嘈杂和不确定时,相对于一个完美的视觉信息输入,学习推理能力非常困难。当对象经常丢失的时候,多次检测或识别模糊的视觉嵌入错误地与不同类别重叠时,依赖于统计快捷偏差方式可能是优化模型的一个简单快捷的方式,一个visual oracle模型能够学习预测答案,同时大大减少了对训练数据的依赖偏差。作者认为,一旦视觉输入中去除任何噪声,用Ground Truth (GT)对象注释代替对象检测输出,深度神经网络可以更容易地学习预测和泛化所需的推理模式。

在人工智能可解释性和数据可视化方面的最新工作中,作者提出了在基于transformer的模型中对注意机制的深入分析,并提供了不同优势的模型所采用的推理模式的指示。将注意力的不同操作模式形象化,并将它们与解决VQA所需的不同子任务(“功能”)联系起来,使用这个分析来比较oracle模型和处理噪声和不确定的视觉输入的标准模型,在前者中突出存在推理模式,而在后者中较少。从这个分析中得出结论,作者建议微调完美visual oracle模型在真实的噪声视觉输入(见图1)。使用相同的分析和可视化技术,作者证明了从嘈杂模型中缺失的注意力模式可以成功地从oracle模型转移到可发展模型中,并报告了整体准确性和泛化方面的改进。
贡献-(i)深入分析了基于transformer的模型中的推理模式,比较了oracle和可扩展模型,包括注意模式的可视化;分析注意模式与推理的关系,以及注意裁剪对推理的影响;(ii)我们建议将oracle学到的推理能力转移到带有噪声输入的SOTA VQA方法中,并提高GQA数据集的整体性能和泛化能力;(iii)我们证明了这种转移与自监督的大规模预训练(LXMERT/BERT-like)是互补的。
二、相关工作
介绍了VQA任务,VQA v1,VQA v2,CLEVR,GQA,GQA-OOD,VQA-CP v2数据集。许多VQA模型仍然强烈依赖于数据集偏差。
Transformers and Vision-Language reasoning 作者关注Transformers,因为它们广泛采用强大的注意机制。MCAN和DFAF引入了使用对象级自我注意和共同注意机制来建模VQA中的内部和通道间交互。Transformers与BERT式的预训练相结合,对VQA也是有益的。
Attention and reasoning patterns in Transformers 近年来,对自注意机制的分析受到了广泛的关注。在[40](参考原论文)中,介绍了一种分析BERT注意层的可视化工具。[11]研究训练策略和微调如何在类似bert的模型中影响注意力。Voita等人[41]根据BERT的功能对其注意力头进行了分类,报告称通过剪枝可以显著简化模型的复杂性。
继NLP的这项工作之后,在视觉语言领域也出现了类似的研究。[21]探索了在添加弱监督目标时,单词-物体对齐在注意图中的出现。[8,27]研究BERT-like预训练VQA转异构体的注意图在多大程度上编码各种视觉语言信息。虽然这些方法更好地理解了VQA模型所捕获的信息量,但它们并没有阐明如何使用这些信息。在我们的工作中,我们分析了各种VQA任务是如何在不同的注意力头中编码的。为此,我们采用了energy-based analysis。此外,我们研究了visual oracle Transformers的注意力,以确定哪些模式导致更好的推理。
三、Analysis of Reasoning Patterns
在本节中,作者将分析基于Transformer的VQA模型中的推理行为,并说明训练对视觉GT数据的影响。
这一节介绍了通用视觉语言任务的transformer架构,包括视觉输入和文本输入各自的模态内注意力,视觉指导文本和文本指导视觉的模态间注意力。
Experimental setup 本节中的所有分析都是在隐藏层维度为128和每层注意力头数量为4的情况下进行的。这对应于LXMERT中使用的架构的一个小版本,其中为d = 768和h = 12。因此,“tiny-LXMERT”对应于VL-Transformer架构加上类似bert (LXMERT)的预训练。视觉特征采用BUTD的对象级特征,可视化是在GQA(验证集)上完成的,因为它特别适合于评估各种各样的推理技能,然而,由于GQA包含了从预定义模板构造的合成问题,因此该数据集只提供了一个受约束的VQA环境,可能需要额外的实验来扩展我们的结论到更自然的设置。
3.1. Visual noise vs. models with perfect-sight
作者推测,视觉pipeline是阻碍VQA模型学习推理的主要困难,这导致模型在训练数据中利用虚假的偏见。这些方法中的大多数在训练和验证步骤中使用预训练的现成的对象检测器BUTD。但在相当数量的情况下,推理所需的视觉对象被错误分类,甚至根本没有被检测到,例如,在visual Genome数据集上的SOTA探测器的检测率就表明了这一点。在这种情况下,即使是一个完美的VQA模型,如果不依靠统计偏差,也无法预测正确的答案。为了进一步探讨这个假设,作者训练了一个visual oracle模型,模型接收完美的视觉输入gt,并与tiny lxmert进行比较。基于相同的VL-Transformer,它从GQA注释接收GT对象,编码为GT bounding box和1-in-K编码的对象类,取代了经典模型的视觉嵌入,所有GT对象都被提供给模型,而不仅仅是推理所需的对象。我们研究了两种模型,oracle模型和经典模型对“推理”的能力。在[22](就是上一篇论文提出的GQA-OOD评估基准)之后,我们测量了一个VQA模型的推理能力,作为正确回答问题的能力,其中GT的答案是罕见的问题组(答案出现次数少)。
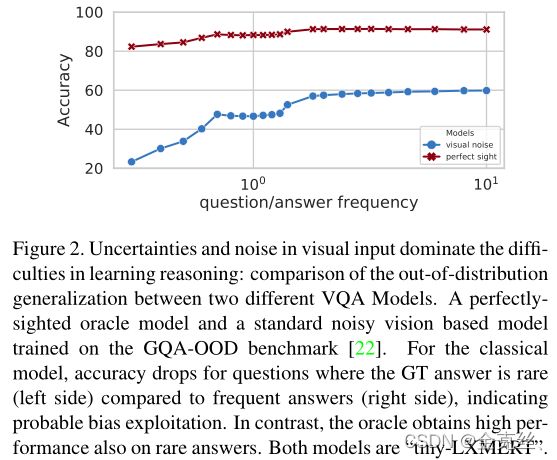
图2展示了模型在不同情况下的结果,在极端情况下(图的左侧),模型只对最稀少的样本进行评估,而在右侧考虑所有样本。对于具有罕见GT答案的(图像,问题)对,采用带噪声视觉(tiny LXMERT)的经典模型的性能急剧下降,这表明对数据集偏见的强烈依赖。我们想要坚持的是,在这个基准中,GT答案的稀缺性是由问题类型决定的,它允许衡量偏见考虑到语言。另一方面,visual oracle模型得到的表现对答案稀缺性的依赖要小得多,这为它克服统计偏差的能力提供了证据。因此,我们推测,visual oracle更接近于一个真实的“推理过程”,通过对文字和物体的操纵来预测答案,而不是通过捕捉统计偏差。
3.2. Attention modes in VL-Transformers
注意力机制是VL-Transformer的核心,它们被定义为不同items之间的关联强度,这使得它们成为深度模型内部工作可视化的主要候选对象。我们分析注意,特别是我们观察不同的注意模式在训练的VQA模型。
我们可视化多头注意力每个头的注意力贡献强度的分布,对于每个注意力图,与给定样本的给定头相关联,计算出达到90%分布强度所需的k个token的数量。A low k number is caused by peaky attention, called small meta-stable statein, while a high k number indicates uniform attention, close to an average operation (very large meta-stable state). For each head, and over a subset of validation samples, we plot the distribution of k numbers, and for some experiments we summarize it with a median value taken over samples and over tokens(很难翻译成中文)。
Diversity in attention modes 这一节表明了oracle VL-Transformer中的推理过程在很大程度上是由语言特征的转换来推理的,即视觉特征引导语言特征的语言特征的转换,而不是语言特征引导视觉特征的视觉特征的转换,说明模型还是在很大程度上依赖语言特征进行推理。


作者也观察到双模态k的分布,如图3-a所示,它是狄拉克(图3-b)和均匀(cf图3-c)注意模式的组合。称这些模式为“双形态”注意,因为它们揭示了存在两种不同形状的注意分布:对于一些样本,产生了狄拉克激活,而其他样本导致一致注意。在图4中,我们比较了噪声视觉模型和oraclet 视觉指导语言的t个注意力头之间的注意模式多样性,其中我们观察到oracle的多样性更高。
3.3、Attention modes and task functions
待做,太难理解。