CANN 算子开发笔记AI CPU 篇 2022_07_08
day1
1. 入门学习
文章目录
- day1
- 1. 入门学习
-
- 1.1 何为算子
-
- 1.1.1 算子名称(name)
- 1.1.2 算子类型(type)
- 1.1.3 张量(Tensor)
- 1.1.4 数据排布格式(Format)
- 1.1.5 形状(Shape)
- 1.1.6 轴(axis)
- 1.1.7 权重(weight)
- 1.1.8偏差(bias)
- 2. AI CPU 简介
-
- 2.1 概述
- 2.2 算子编译运行流程
-
- 2.2.1算子编译运行逻辑架构
- 2.2.2 算子编译流程
- 2.2.3 算子运行流程
- 3.算子开发流程
- 4. 算子开发准备
-
- 4.1 环境准备
- 4.2 算子分析
- 4.3 工程创建
-
- 4.3.1 基于算子样例
- 4.3.2 基于 msopgen 工具
-
- **1.功能描述**
- **2.工具准备**
- **3.使用方法**
-
- 1. 步骤1 准备输入文件
-
- 1.1 适配昇腾AI处理器json文件的准备工作
- 1.2TensorFlow的原型定义(.txt)的准备工作
- 1.3适配昇腾AI处理器的Excel文件准备工作
- 2. 步骤2 创建算子工程
- 3 步骤3 在算子工程中追加算子(可选)
1.1 何为算子
深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称 Op)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过程,是一个算子。
一句话,对数据进行处理的工具。对于函数 y = f ( x ) y=f(x) y=f(x), f f f 就是算子。
1.1.1 算子名称(name)
算子的名称,用于标志网络中的某个算子,同一网络中算子的名称需要保持唯一。如下图所示Conv1,Pool1,Conv2都是此网络中的算子名称,其中Conv1与Conv2算子的类型为Convolution,表示分别做一次卷积运算。

1.1.2 算子类型(type)
网络中每一个算子根据算子类型进行算子实现的匹配,相同类型的算子的实现逻辑相同。在一个网络中同一类型的算子可能存在多个,例如上图中的Conv1算子与Conv2算子的类型都为Convolution。
1.1.3 张量(Tensor)
Tensor是算子中的数据,包括输入数据与输出数据,TensorDesc(Tensor描述符)是对输入数据与输出数据的描述,TensorDesc数据结构包含如下属性如表1-1所示。

1.1.4 数据排布格式(Format)
在深度学习框架中,多维数据通过多维数组存储,比如卷积神经网络的特征图用四维 数组保存,四个维度分别为批量大小(Batch, N)、特征图高度(Height, H)、特征 图宽度(Width, W)以及特征图通道(Channels, C)。
由于数据只能线性存储,因为这四个维度有对应的顺序。不同深度学习框架会按照不 同的顺序存储特征图数据,比如Caffe,排列顺序为[Batch, Channels, Height, Width],即NCHW。Tensorflow中,排列顺序为[Batch, Height, Width, Channels], 即NHWC。
如图1-2所示,以一张格式为RGB的图片为例,NCHW中,C排列在外层,实际存储的 是“RRRGGGBBB”,即同一通道的所有像素值顺序存储在一起;而NHWC中C排列在 最内层,实际存储的则是“RGBRGBRGB”,即多个通道的同一位置的像素值顺序存储 在一起。

1.1.5 形状(Shape)
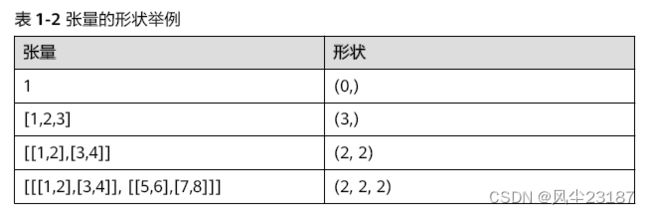
张量的形状,以(D0, D1, … ,Dn-1)的形式表示,D0到Dn是任意的正整数。
如形状(3,4)表示第一维有3个元素,第二维有4个元素,(3,4)表示一个3行4列的矩阵数组。
在形状的小括号中有多少个数字,就代表这个张量是多少维的张量。形状的第一个元
素要看张量最外层的中括号中有几个元素,形状的第二个元素要看张量中从左边开始
数第二个中括号中有几个元素,依此类推。例如:
1.1.6 轴(axis)
轴是相对Shape来说的,轴代表张量的shape的下标,比如张量a是一个5行6列的二维数组,即shape是(5,6),则axis=0表示是张量中的第一维,即行。axis=1表示是张量中的第二维,即列。
例如张量数据[[[1,2],[3,4]], [[5,6],[7,8]]],Shape为(2,2,2),则轴0代表第一个维度的数据即[[1,2],[3,4]]与[[5,6],[7,8]]这两个矩阵,轴1代表第二个维度的数据即[1,2]、[3,4]、[5,6]、[7,8]这四个数组,轴2代表第三个维度的数据即1,2,3,4,5,6,7,8这八个数。轴axis可以为负数,此时表示是倒数第axis个维度。
N维Tensor的轴有:0 , 1, 2,……,N-1。

1.1.7 权重(weight)
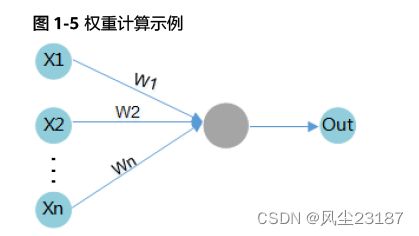
当输入数据进入计算单元时,会乘以一个权重。例如,如果一个算子有两个输入,则每个输入会分配一个关联权重,一般将认为较重要数据赋予较高的权重,不重要的数据赋予较小的权重,为零的权重则表示特定的特征是无需关注的。
如图1-5所示,假设输入数据为X1,与其相关联的权重为W1,那么在通过计算单元后,数据变为了X1*W1。
1.1.8偏差(bias)

与神经网络类似。
2. AI CPU 简介
2.1 概述
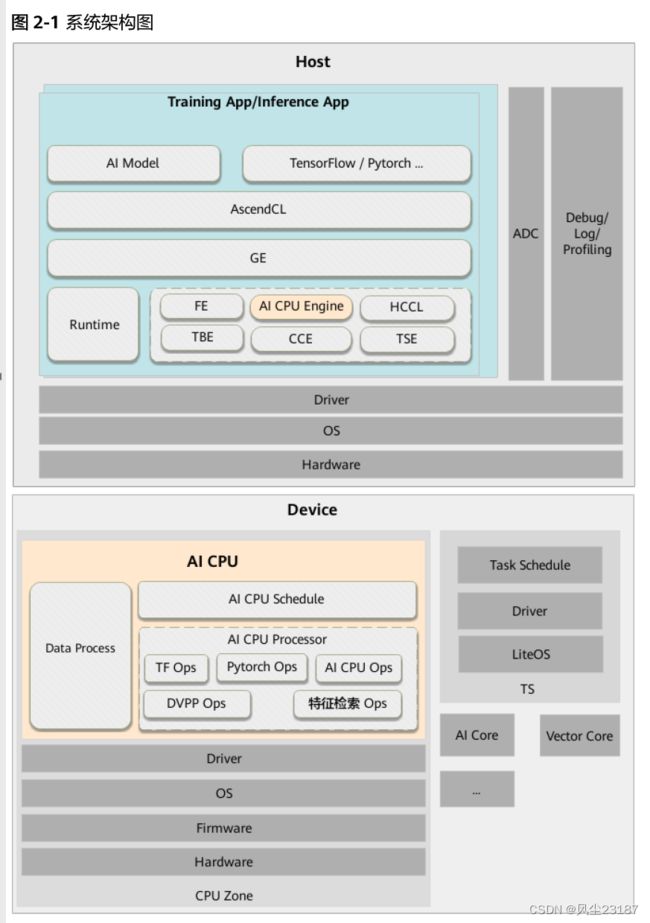
AI CPU负责执行昇腾AI处理器的CPU类算子(包括控制算子、标量和向量等通用计算),其在Ascend解决方案系统架构中的位置如下所示:
AI CPU算子编译执行所涉及组件如下:
- GE(Graph Engine):Graph Engine是基于昇腾AI软件栈对不同的机器学习框架提供统一的IR接口,对接上层网络模型框架,例如Tensorflow、PyTorch等,GE的主要功能包括图准备、图拆分、图优化、图编译、图加载、图执行和图管理等(此处图指网络模型拓扑图)。(比作建一座房子)
- AI CPU Engine:AI CPU子图编译引擎,负责对接GE,提供AI CPU算子信息库,进行算子注册、算子内存需求计算、子图优化和task生成的能力。(房间的局部制作)
- AI CPU Schedule:AI CPU的模型调度器,与Task Schedule配合完成NN模型的调度和执行(包工头)。
- AI CPU Processor:AI CPU的Task执行器,完成算子运算。AI CPU Processor包含算子实现库,算子实现库完成AI CPU算子的执行实现。(工人)
- Data Processor:训练场景下,用于进行训练样本的数据预处理。(原材料处理器)
2.2 算子编译运行流程
2.2.1算子编译运行逻辑架构
一个完整的AI CPU算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。
算子开发完成后在昇腾AI处理器硬件平台上的编译运行逻辑架构如图2-2和图2-3所示。


其中,TFAdapter只有在基于Tensorflow框架进行训练时使用。
| 开发交付件 | 说明 |
|---|---|
| 算子实现 | 包含算子类的定义及算子的计算实现 |
| 算子适配插件 | 基于第三方框架(Tensorflow/Caffe)进行自定义算子开发的场景,开发 人员完成自定义算子的实现代码后,需要进行适配插件的开发,将基于第 三方框架的算子映射成适昇腾AI处理器的算子,将算子信息注册到GE中。 基于第三方框架的网络运行时,首先会加载并调用算子适配插件信息,将 第三方框架网络中的算子进行解析并映射成昇腾AI处理器中的算子。 |
| 算子原型库 | 算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子 的数学含义,包含定义算子输入、输出、属性和取值范围,基本参数的校 验和shape的推导。网络运行时,GE会调用算子原型库的校验接口进行基 本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的 输出shape与dtype,进行输出tensor的内存的分配。 |
| 算子信息库 | 算子信息库主要体现算子在昇腾AI处理器上物理实现的限制,包括算子的 输入输出name以及dtype等信息。网络运行时,AI CPU Engine会根据算 子信息库中的算子信息做基本校验,并进行算子匹配。 |
note:若存在相同OpType的TBE算子与AI CPU算子,GE会优先匹配TBE算子进行执行。
2.2.2 算子编译流程
AI CPU算子的编译详细流程如图2-4所示。
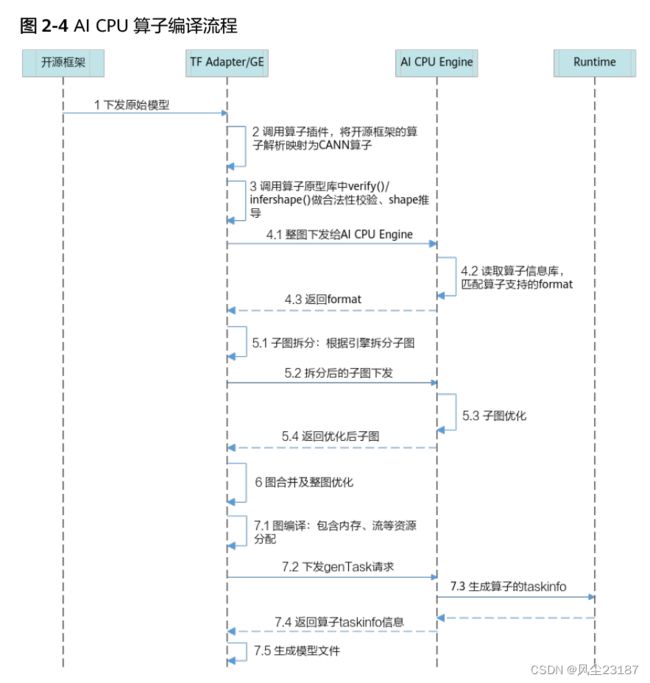
- 将开源框架网络模型下发给GE。
若基于Tensorflow框架进行在线训练,首先会调用TF Adapter适配接口生成TF原始网络模型,并下发给GE;若使用AscendCL应用进行模型推理,则直接将原始网络模型下发给GE。
注:网络模型的拓扑图后续简称为图。 - GE调用算子插件,将原始网络模型中的算子映射为适配昇腾AI处理器的算子,从而将原始开源框架图解析为适配昇腾AI处理器的图。
- 调用算子原型库校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的内存的分配。
- GE向整图下发给AI CPU Engine,AI CPU Engine读取算子信息库,匹配算子支持的format,并将format返回给GE。
- GE根据图中数据将图拆分为子图并下发给AI CPU Engine,AI CPU Engine进行子图优化,并将优化后子图返回给GE。
- GE将子图进行合并,并对合并后的整图进一步优化。
- GE进行图编译,包含内存分配、流资源分配等,并向AI CPU Engine发送genTask请求,AI CPU Engine返回算子的taskinfo信息给GE,图编译完成之后生成适配昇腾AI处理器的模型。
2.2.3 算子运行流程
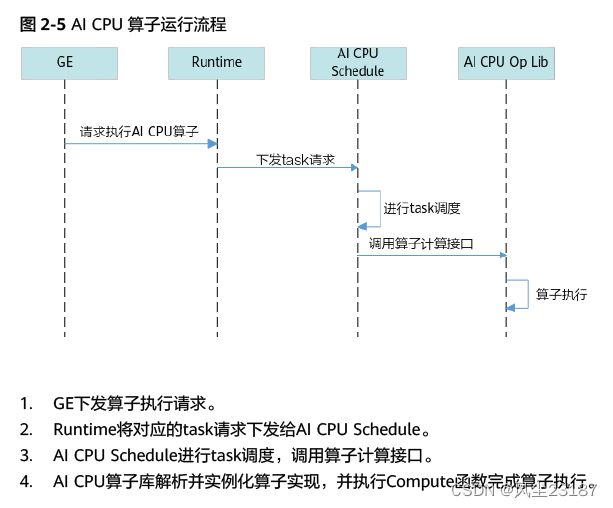
3.算子开发流程
进行AI CPU自定义算子开发的流程如图所示

开发步骤详解如表3-1所示。
| 步骤 | 描述 | 参考 |
|---|---|---|
| 环境准备 | 准备算子开发及运行验证所依赖的开发环境与运行环境 | 4 算子开发准备 |
| 算子分析 | 进行算子开发前,需要进行算子分析,明确算子的功能、输入、输出,规划算子类型名称以及算子编译生成的库文件名称等 | 4.2 算子分析 |
| 工程创建 | 创建自定义算子工程 | 4.3.1 基于算子样例 |
| 算子原型定义 | 算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出、属性和取值范围,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。离线模型转换时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。 | 5.1 算子原型定义 |
| 算子代码实现 | 实现算子的计算逻辑 | 5.3 算子代码实现 |
| 算子信息库定义 | 算子信息配置文件用于将算子的相关信息注册到 算子信息库中,包括算子的OpType、输入输出 dtype、name等信息。网络运行时,AI CPU Engine会根据算子信息库中的算子信息做基本校 验,并进行算子匹配。 | 5.3 算子信息库定义 |
| 算子适配 | 基于第三方框架(TensorFlow/Caffe)进行自定 义算子开发的场景,开发人员完成自定义算子的 实现代码后,需要进行插件的开发将基于 TensorFlow/Caffe的算子映射成昇腾AI处理器的算子。 | 5.4 算子适配 |
| 算子工程编译部署 | ● 算子编译:将算子适配插件实现文件、原型定 义文件、信息定义文件编译成算子插件库文 件、算子原型库、算子信息库。 ~~~~~~~~~~~~~~~~~ ● 算子部署:将算子实现文件、插件库文件、原 型库、信息库部署到算子库中(opp的对应目 录下)。 ~~~~~~~~~~~~~~~~~ 命令行场景下,可直接使用样例工程的编译文件 进行算子工程的一键式编译,生成自定义算子安 装包。指定opp路径,执行安装包,实现自定义 算子部署。 | 5.5 算子工程编 译部署 |
| 算子ST测试 | 系统测试(System Test),在真实的硬件环境 中,验证算子的正确性。 | 6 算子ST测试 |
| 算子网络验证 | 将自定义算子加载到网络模型中进行运行验证。 | 7 算子网络测试 (推理) 8 算子网络测试 (训练) |
4. 算子开发准备
4.1 环境准备
进行自定义算子开发前,需要完成驱动及CANN软件的安装,详情可参见《CANN软件安装指南》。
环境变量配置:
– CANN组合包提供进程级环境变量设置脚本,供用户在进程中引用,以自动
完成环境变量设置。执行命令参考如下,以下示例均为root或非root用户默认
安装路径,请以实际安装路径为准。
以root用户安装toolkit包
./usr/local/Ascend/ascend-toolkit/set_env.sh
以非root用户安装toolkit包
.${HOME}/Ascend/ascend-toolkit/set_env.sh
– 算子编译依赖Python,以Python3.7.5为例,请以运行用户执行如下命令设置Python3.7.5的相关环境变量。
#用于设置python3.7.5库文件路径
export LD_LIBRARY_PATH=/usr/local/python3.7.5/lib:$LD_LIBRARY_PATH
#如果用户环境存在多个python3版本,则指定使用python3.7.5版本
export PATH=/usr/local/python3.7.5/bin:\$PATHPython3.7.5
安装路径请根据实际情况进行替换,您也可以将以上命令写入~/.bashrc文件中,然后执行source ~/.bashrc命令使其立即生效。
4.2 算子分析
使用AI CPU方式开发算子前,我们需要确定算子功能、输入、输出、算子类型以及算
子实现函数名称等。给函数限定约束。
- 步骤1 :明确算子的功能以及数学表达式。
以Add算子为例
Add算子的数学表达式为:z=x+y
计算过程是:将两个输入参数相加,得到最终结果z并将其返回。 - 步骤2 :明确输入和输出
● 例如Add算子有两个输入:x与y,输出为z。
● 本样例中算子的输入支持的数据类型为float16、float32、 int32,算子输出的数据类型与输入数据类型相同。
● 算子输入支持所有shape,输出shape与输入shape相同。
● 算子输入支持的 format 为:NCHW,NHWC,ND。 - 步骤3 :明确算子实现文件名称以及算子的类型(OpType)。
● 算子类型需要采用大驼峰的命名方式,即采用大写字符区分不同的语义。
● 算子文件名称,可选用以下任意一种命名规则:
建议将OpType按照如下方式进行转换,得到算子文件名称。
转换规则如下:
~~~~~~~ – 首字符的大写字符转换为小写字符。
~~~~~~~~~~~ 例如:Abc -> abc
~~~~~~~ – 小写字符后的大写字符转换为下划线+小写字符。
~~~~~~~~~~~ 例如:AbcDef -> abc_def
~~~~~~~ – 紧跟数字以及大写字符后的大写字符,作为同一语义字符串,查找此字符串后的第一个小写字符,并将此小写字符的前一个大写字符转换为下划线+小写字符,其余大写字符转换为小写字符。若此字符串后不存在小写字符,则直接将此字符串中的大写字符转换为小写字符。
~~~~~~~~~~ 例如:ABCDef -> abc_def;Abc2DEf -> abc2d_ef;Abc2DEF -> abc2def;ABC2dEF -> abc2d_ef。
因此本例中,算子类型定义为Add,算子的实现文件名称为add,因此各个交付件的名称建议命名如下:
● 算子的代码实现(即kernel实现)文件命名为add_kernel.h与add_kernel.cc。
● 插件实现文件命名为add_kernel_plugin.cc。
● 原型定义文件命名为:add.h与add.cc。
● 信息定义文件命名为add.ini。
通过以上分析,得到Add算子的设计规格如表4-1所示:
表4-1
| 算子类型(OpType) | Add | ||
| 算子输入 | name : x | shape:all | data type:float16、float32、 int32 |
| name : y | shape:all | data type:float16、float32、 int32 | |
| 算子输出 | name : z | shape:all | data type:float16、float32、 int32 |
| 算子实现文件名名 | add | ||
4.3 工程创建
4.3.1 基于算子样例
命令行场景下,开发者可以直接基于Ascend开源社区中提供的自定义算子样例工程进行修改,追加自定义算子。
样例获取
单击Gitee或Github,进入Ascend samples开源仓,参见README中的“版本说明”下载配套版本的 sample 包,从“cplusplus/level1_single_api/4_op_dev/1_custom_op”目录中获取样例。
目录结构介绍
算子工程目录结构如下所示,请基于如下规则在对应目录下进行算子交付件的开发:

● 若开发者需要自定义多个AI CPU算子,需要在同一算子工程中进行实现,对应实现文件按照如上规则进行存放,并将所有自定义算子在同一工程中同时进行编译,将所有AI CPU自定义算子的实现文件编译成一个动态库文件。
编译方法请参见5.5.2 算子工程编译。
● 若开发者需要同时开发AI CPU算子与TBE算子,也需要在同一算子工程中进行实现
和编译,关于TBE算子的开发,请参见《TBE自定义算子开发指南》。
4.3.2 基于 msopgen 工具
1.功能描述
CANN开发套件包中提供了自定义算子工程生成工具msopgen,可基于算子原型定义
输出算子开发相关交付件,包括算子代码实现文件、算子适配插件、算子原型定义、
算子信息库定义以及工程编译配置文件。
● 该工具暂不支持PyTorch框架和MindSpore框架的AICPU算子工程创建。
● 若开发者需要自定义多个AI CPU算子,需要在同一算子工程中进行实现,并将所有自定义算子在同一工程中同时进行编译,将所有AI CPU自定义算子的实现文件编译成一个动态库文件。
2.工具准备
工具所在目录:Toolkit组件安装路径下的“toolkit/python/site-packages/bin”。
使用前提
● 安装依赖(可选):
pip3 install xlrd==1.2.0
3.使用方法
1. 步骤1 准备输入文件
自定义算子工程生成工具支持输入三种类型的原型定义文件创建算子工程,分别为:
● 适配昇腾AI处理器算子IR定义文件(.json)
● TensorFlow的原型定义文件(.txt)
TensorFlow的原型定义文件可用于生成TensorFlow、Caffe框架的算子工程
● 适配昇腾AI处理器算子IR定义文件(.xlsx)
msopgen工具未来不再支持.xlsx格式的输入文件。
请用户选择一种文件完成输入文件的准备工作。
1.1 适配昇腾AI处理器json文件的准备工作
– 用户可从Toolkit安装路径“toolkit/python/site-packages/op_gen/
json_template”中获取模板文件IR_json.json,并进行修改,其文件参数配置
说明请参见表4-2:
表4-2 json 文件配置参数说明
| 配置字段 | 类型 | 含义 | 是否必选 | |
| op | - | 字符串 | 算子的OperatorType | 是 |
| input_desc | - | 列表 | 输入参数描述。 | 否 |
| name | 字符串 | 算子输入参数的名 称。 | ||
| param_type | 字符串 | 参数类型: ▪ required ▪ optional ▪ dynamic 未配置默认为 required。 | ||
| format | 列表 | 针对类型为tensor 的参数,配置为 tensor支持的数据 排布格式。 包含如下取值: ND,NHWC,NCHW, HWCN,NC1HWC0, FRACTAL_Z等。 | ||
| type | 列表 | 算子参数的类型。 包含如下取值: float、int32、 bool、int64、 half、uint32等。 | ||
| output_desc | - | 列表 | 输出参数描述。 | 是 |
| name | 字符串 | 算子输出参数的名 称。 | ||
| param_type | 字符串 | 参数类型: ▪ required ▪ optional ▪ dynamic 未配置默认为 required。 | ||
| format | 列表 | 针对类型为tensor 的参数,配置为 tensor支持的数据 排布格式。 包含如下取值: ND,NHWC,NCHW, HWCN,NC1HWC0, FRACTAL_Z等。 | ||
| type | 列表 | 算子参数的类型。 包含如下取值: float、int32、 bool、int64、 half、uint32等。 | ||
| attr(属性) | - | 列表 | 属性描述。 | 否 |
| name | 字符串 | 算子属性参数的名 称。 | ||
| param_type | 字符串 | 参数类型: ▪ required ▪ optional 未配置默认为 required。 | ||
| default_valu e | - | 默认值 | ||
| type | 字符串 | 算子参数的类型。 包含如下取值: int、bool、float、 string、list_int、 list_float等。。 | ||
json文件可以配置多个算子。json文件为列表,列表中每一个元素为一个算子。
▪ 若存在op同名算子,会以列表中后一算子创建算子工程。
▪ 若input_desc或output_desc中的name参数相同,则后一个会覆盖前一参数。
▪ input_desc,output_desc中的type与format需一一对应匹配。如果没有配置format,自动以“ND”按type的个数一一对应补齐。如果仅配置一个format并对应多个type时,将基于此format,按照type的个数一一对应补齐。
1.2TensorFlow的原型定义(.txt)的准备工作
TensorFlow的原型定义文件(.txt)中内容可从TensorFlow开源社区获取,例如,Add算子的原型定义在TensorFlow开源社区中/tensorflow/core/ops/math_ops.cc文件中,在文件中搜索“Add”找到Add对应的原型定义,内容如下所示:
REGISTER_OP("Add")
.Input("x: T")
.Input("y: T")
.Output("z: T")
.Attr(
"T: {bfloat16, half, float, double, uint8, int8, int16, int32, int64, "
"complex64, complex128, string}")
.SetShapeFn(shape_inference::BroadcastBinaryOpShapeFn);
note:
每个 xx.txt 文件仅能包含一个算子的原型定义。
自定义算子工程生成工具只解析算子类型、Input、Output、Attr中内容,其他内容可以不保存在 xx.txt 中。
1.3适配昇腾AI处理器的Excel文件准备工作
用户可从Toolkit安装路径下的“toolkit/tools/msopgen/template”目录下获取模板文件Ascend_IR_Template.xlsx进行修改。请基于“Op”页签进行修改,
“Op”页签可以定义多个算子,每个算子都包含如下列:
略
2. 步骤2 创建算子工程
进入msopgen工具所在目录执行如下命令,参数说明请参见表4-5。
./msopgen gen -i {operator define file} -f {framework type} -c {Compute Resource} -out {Output Path}
表4-5 参数说明
| 参数名称 | 参数描述 | 是否必选 |
|---|---|---|
| gen | 用于生成算子开发交付件 | 是 |
| -i,–input | 算子定义文件路径,可配置为绝对路径或者相对路径。工具执行用户需要有此路径的可读权限。算子定义文件支持如下三种类型:● 适配昇腾AI处理器算子IR定义文件(.json)● TensorFlow的原型定义文件(.txt)● 适配昇腾AI处理器算子IR定义文件(.xlsx) | 是 |
| -f,–framework | 框架类型。 ● TensorFlow框架,参数值:tf或者tensorflow ● Caffe框架,参数值:caffe ● ONNX框架,参数值:onnx 说明 1. 所有参数值大小写不敏感。 2. 该工具暂不支持MindSpore框架的AICPU算子工程创建。 | 是 |
| -c,–compute_unit | 算子使用的计算资源。 ● 针对TBE算子,配置格式为:ai_core-{Soc Version},ai_core与{Soc Version}之间用中划线 “-”连接,如下所示: ai_core-Ascend310 ai_core-Ascend710 ai_core-Ascend910 请根据实际昇腾AI处理器版本进行选择。 说明 {Soc Version}可从CANN软件安装后文件存储路径的 “compiler/data/platform_config”路径下查看支持的昇 腾AI处理器的类型,对应“*.ini”文件的名字即为$ {soc_version}。 ● 针对AI CPU算子,请配置为:aicpu。 | 是 |
| -out, --output | 生成文件所在路径,可配置为绝对路径或者相对路径, 并且工具执行用户具有可读写权限。 若不配置,则默认生成在执行命令的当前路径。 | 否 |
| -m, --mode | 生成交付件模式。 ● 0:创建新的算子工程,若指定的路径下已存在算子 工程,则会报错退出。 ● 1:在已有的算子工程中追加算子 默认值:0。 | 否 |
| -op, --operator | 此参数针对-i为算子IR定义文件的场景。 配置算子的类型,如:Conv2DTik 若不配置此参数,当IR定义文件中存在多个算子时,工 具会提示用户选择算子。 | 否 |
使用IR_json.json模板作为输入创建TensorFlow框架AI CPU的算子工程。
- 进入msopgen工具所在目录执行如下命令:
./msopgen gen -i json_path/IR_json.json -f tf -c aicpu -out ./output_data
-i 参数请修改为IR_json.json文件的实际路径。
例如:“${INSTALL_DIR}/toolkit/python/site-packages/op_gen/json_template/
IR_json.json”
- 选择算子(可选):
- 若输入IR_json.json文件只有一个算子原型定义或使用-op参数指定算子类型请跳过此步骤。
- 若输入**.json文件中包含多个原型定义,且没有使用-op参数指定算子类型工具会提示输入选择的算子序号,选择算子。工具会提示输入选择的算子序号,输入:1。
There is more than one operator in the .json file:
1 Op_1
2 Op_2
Input the number of the op: 1
当命令行提示:Generation completed,则完成Op_1算子工程的创建。
Op_1为文件中"op"的值。
- 查看算子工程目录:
算子工程目录生成在 -out 所指定的目录下:./output_data,目录结构如下所示:

3 步骤3 在算子工程中追加算子(可选)
若需要在已存在的算子工程目录下追加其他自定义算子,命令行需配置“-m 1”参
数。
进入msopgen工具所在目录执行如下命令,示例:
./msopgen gen -i json_path/**.json -f tf -c aicpu -out ./output_data -m 1
在算子工程目录下追加**.json中的算子。