PyTorch深度学习实战 第十一讲
第十一讲 卷积神经网络高级篇 GoogLeNet 和ResNet
GoogLeNet
1、据说GoogLeNet中的L之所以大写,是为了纪念最早的LeNet。Googlenet中存在很多重复的模块,称之为Inception module。其中用到了11, 33,55的卷积块。11的卷积可以改变通道数量,同时大大减少计算量。
2、通过类编写inception module时,注意分清哪些定义在init内,哪些在forward内。
3、代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
# Step1: prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# Step2: design model
class Inception(torch.nn.Module):
def __init__(self, in_channels):
super(Inception, self).__init__()
self.branch_avg_pool_1x1 = torch.nn.Conv2d(in_channels, 24, kernel_size=1)
self.branch_1x1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch_5x5_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch_5x5_2 = torch.nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch_3x3_1 = torch.nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch_3x3_2 = torch.nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch_3x3_3 = torch.nn.Conv2d(24, 24, kernel_size=3, padding=1)
def forward(self, x):
branch_avg_pool_1x1 = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_avg_pool_1x1 = self.branch_avg_pool_1x1(branch_avg_pool_1x1)
branch_1x1 = self.branch_1x1(x)
branch_5x5 = self.branch_5x5_1(x)
branch_5x5 = self.branch_5x5_2(branch_5x5)
branch_3x3 = self.branch_3x3_1(x)
branch_3x3 = self.branch_3x3_2(branch_3x3)
branch_3x3 = self.branch_3x3_3(branch_3x3)
outputs = [branch_avg_pool_1x1, branch_1x1, branch_3x3, branch_5x5]
return torch.cat(outputs, dim=1)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = Inception(in_channels=10)
self.incep2 = Inception(in_channels=20)
self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Step3: construct Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# Step4: Train and Test
def train(epoch):
running_loss = 0
for batch_idx, (inputs, target) in enumerate(train_loader, 0):
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward
outputs = model(inputs)
loss = criterion(outputs, target)
# backward
loss.backward()
# update
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad(): # 以下内容不需要计算梯度
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim=1代表每行的最大值
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Accuracy on test set: %d %%" % (100*correct/total))
return correct/total
if __name__ == "__main__":
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.xlabel("Epoch")
plt.ylabel("Acc")
plt.show()
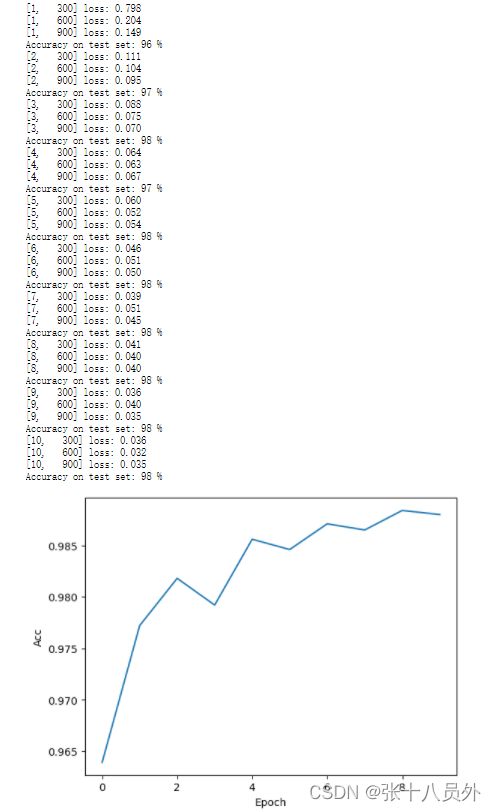
4、结果如图:
ResNet
残差神经网络是由何恺明大神提出来的,由于发现不断堆叠网络层,网络的性能并不是一直上升的,往往在20层以内,性能随着层数的加深而提高,超过20层后性能反而会下降。本着至少不会比原来网络性能低的原则,残差神经网络被设计出来,残差网络可以通过 堆叠层数,实现至少不比别的网络性能差。
resnet中有相应的ResNet模块,对上述的inception模块修改即可,代码如下:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
# Step1: prepare dataset
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../dataset/mnist', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='../dataset/mnist', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
# Step2: design model
class ResBlock(torch.nn.Module):
def __init__(self, channels):
super(ResBlock, self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(channels, channels, kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(x)
y = F.relu(x + y)
return y
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5)
self.resblock1 = ResBlock(channels=16)
self.resblock2 = ResBlock(channels=32)
self.mp = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.resblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.resblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# Step3: construct Loss and Optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# Step4: Train and Test
def train(epoch):
running_loss = 0
for batch_idx, (inputs, target) in enumerate(train_loader, 0):
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward
outputs = model(inputs)
loss = criterion(outputs, target)
# backward
loss.backward()
# update
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss/300))
running_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad(): # 以下内容不需要计算梯度
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # dim=1代表每行的最大值
total += labels.size(0)
correct += (predicted == labels).sum().item()
print("Accuracy on test set: %d %%" % (100*correct/total))
return correct/total
if __name__ == "__main__":
epoch_list = []
acc_list = []
for epoch in range(10):
train(epoch)
acc = test()
epoch_list.append(epoch)
acc_list.append(acc)
plt.plot(epoch_list, acc_list)
plt.xlabel("Epoch")
plt.ylabel("Acc")
plt.show()
运行结果如图:
