深度学习编程小tips
ViT网络paddle代码
加入位置信息
在ViT中引入一个额外的token用来学习全局信息从而进行分类
Mutil Head Attention
#基于paddle
#2021/12/13
#注:该代码是paddlepaddle官方开的ViT课程中老师编写的,我只是把它搬运过来以防丢失,方便随#时查找
import paddle
import paddle.nn as nn
import numpy as np
from PIL import Image
from attention import Attention
paddle.set_device('cpu')
class Identity(nn.Layer):#定义一个啥也不干
def __init__(self):
super().__init__()
def forward(self, x):
return x
class PatchEmbedding(nn.Layer):
def __init__(self, image_size, patch_size, in_channels, embed_dim, dropout=0.):
super().__init__()
self.embed_dim = embed_dim
n_patches = (image_size // patch_size) * (image_size // patch_size)
self.patch_embed = nn.Conv2D(in_channels=in_channels,
out_channels=embed_dim,
kernel_size=patch_size,
stride=patch_size,#这里是关键,是一个无重叠的卷积,本质上可以看成是一个MLP,用来将一个batch做embed
bias_attr=False)
self.dropout = nn.Dropout(dropout)
#add class token
self.class_token = paddle.create_parameter(
shape = [1, 1,embed_dim],
dtype='float32',
default_initializer = nn.initializer.Constant(0.))
#add position embedding
self.position_embedding = paddle.create_parameter(
shape = [1, n_patches+1, embed_dim],
dtype='float32',
default_initializer=nn.initializer.TruncatedNormal(std=.02)
)
def forward(self,x):
#[n, c, h, w]
cls_tokens = self.class_token.expand([x.shape[0], -1, -1])
x = self.patch_embed(x) #[n,embed_dim,h',w']
x = x.flatten(2)#[n,embed_dim,num_patches]
x = x.transpose([0, 2, 1])#[n,num_patches,embed_dim]
x = paddle.concat([cls_tokens, x], axis=1)
x = x + self.position_embedding
return x
class Mlp(nn.Layer):
def __init__(self, embed_dim, mlp_ratio=4.0, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(embed_dim, int(embed_dim * mlp_ratio))
self.fc2 = nn.Linear(int(embed_dim * mlp_ratio), embed_dim)
self.act = nn.GELU()
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class EncoderLayer(nn.Layer):
def __init__(self, embed_dim=768, num_heads=4, qkv_bias=True, mlp_ratio=4.0,dropout=0.,attention_dropout=0.):
super().__init__()
self.attn = Attention(embed_dim, num_heads)#TODO
self.attn_norm = nn.LayerNorm(embed_dim)
self.mlp = Mlp(embed_dim, mlp_ratio)
self.mlp_norm = nn.LayerNorm(embed_dim)
def forward(self, x):
h = x#注意这里用的是pre——norm也就是先做norm再做计算
x = self.attn_norm(x)
x = self.attn(x)
x = h + x
h = x
x = self.mlp_norm(x)
x = self.mlp(x)
x = h + x
return x
class Encoder(nn.Layer):
def __init__(self, embed_dim, depth):
super().__init__()
layer_list = []
for i in range(depth):
encoder_layer = EncoderLayer()
layer_list.append(encoder_layer)
self.layers = nn.LayerList(layer_list)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
for layer in self.layers:
x = layer(x)
x = self.norm(x)
return x
class Visualtransformer(nn.Layer):
def __init__(self,
image_size=224,
patch_size=16,
in_channels=3,
num_classes=1000,
embed_dim=768,
depth=3,
num_heads=8,
mlp_ratio=4,
qkv_bias=True,
dropout=0.,
attention_dropout=0.,
droppath=0.):
super().__init__()
self.patch_embedding = PatchEmbedding(image_size, patch_size, in_channels, embed_dim)
self.encoder = Encoder(embed_dim, depth)
self.classifier = nn.Linear(embed_dim, num_classes)
def forward(self, x):
#x:[N,C,H,W]
x = self.patch_embedding(x)#x:[N,embed_dim,h',w']
#x = x.flatten(2)#[N, embed_dim, h'*w']
#x = x.transpose([0,2,1])
x = self.encoder(x)
x = self.classifier(x[:, 0])
return x
def main():
t = paddle.randn([4, 3, 224, 224])
model = Visualtransformer()
paddle.summary(model,(4,3,224,224))
out = model(t)
print(out.shape)
#3.MLP
if __name__ == '__main__':
main()2.
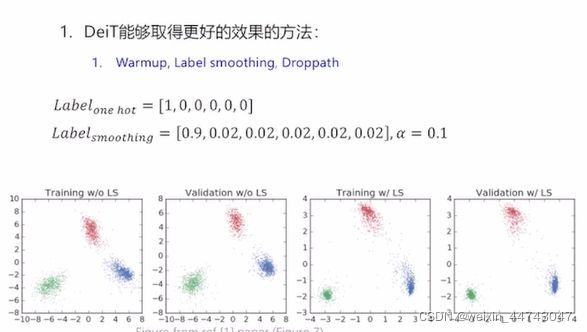
Warmup:

label smoothing
在分类问题中,我们的最后一层一般是全连接层,然后对应标签的one-hot编码,即把对应类别的值编码为1,其他为0。这种编码方式和通过降低交叉熵损失来调整参数的方式结合起来,会有一些问题。这种方式会鼓励模型对不同类别的输出分数差异非常大,或者说,模型过分相信它的判断。但是,对于一个由多人标注的数据集,不同人标注的准则可能不同,每个人的标注也可能会有一些错误。模型对标签的过分相信会导致过拟合。标签平滑(Label-smoothing regularization,LSR)是应对该问题的有效方法之一,它的具体思想是降低我们对于标签的信任,例如我们可以将损失的目标值从1稍微降到0.9,或者将从0稍微升到0.1。标签平滑最早在inception-v2中被提出,它将真实的概率改造为:其中,ε是一个小的常数,K是类别的数目,y是图片的真正的标签,i代表第i个类别,q_i是图片为第i类的概率。总的来说,LSR是一种通过在标签y中加入噪声,实现对模型约束,降低模型过拟合程度的一种正则化方法。模型对标签没有那么相信了,过拟合的更新自然也小了一些。但会不会影响学习的效果呢?所以这个ε也不能太大。
————————————————
版权声明:本文为CSDN博主「Swocky」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Swocky/article/details/105809498
droppath
DropPath/drop_path 是一种正则化手段,其效果是将深度学习模型中的多分支结构随机”删除“,python中实现如下所示:https://blog.csdn.net/qq_43426908/article/details/121662843?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163988601816780269835263%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=163988601816780269835263&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~rank_v31_ecpm-4-121662843.pc_search_result_control_group&utm_term=droppath&spm=1018.2226.3001.4187