【隆重发布】Facebook 发布深度学习工具包PyTorch Hub,让论文复现变得更容易,一行代码调用经典模型
【隆重发布】Facebook 发布深度学习工具包PyTorch Hub,让论文复现变得更容易,一行代码调用经典模型
可以加群264191384 注明(pytorch)
-
6月11日,Facebook PyTorch 团队发布了一个深度学习工具包 PyTorchHub, 帮助机器学习工作者更快实现重要论文的复现工作。PyTorchHub 由一个预训练模型仓库组成,专门用于提高研究工作的复现性以及新的研究。同时它还内置了对Google Colab的支持,并与Papers With Code集成。目前 PyTorchHub 包括了一系列与图像分类、分割、生成以及转换相关的模型另外重要的一点是,它的整个工作流程大大简化。
简化到什么程度呢?Facebook 首席 AI 科学家Yann LeCun 兼图灵奖图灵奖得主Yann LeCun发表 Twitter强烈推荐,使用PyTorch Hub,无论是ResNet、BERT、GPT、VGG、PGAN 还是 MobileNet 等经典模型,只需输入一行代码,就能实现一键调用。
这个模型聚合中心到底如何呢?我们来一探究竟。
=============
使用PyTorch Hub进行可重复研究
再现性是许多研究领域的基本要求,包括基于机器学习技术的研究领域。然而,许多机器学习出版物要么不可再现,要么难以复制。随着研究出版物数量的不断增加,包括现在在arXiv上发表的数万篇论文以及提交给历史最高级别会议的论文,研究再现性比以往任何时候都更加重要。虽然这些出版物中的许多都伴随着代码以及训练有素的模型,这些模型虽然有用但仍留有许多步骤供用户自己解决。
我们很高兴地宣布推出PyTorch Hub,这是一个简单的API和工作流程,为改善机器学习研究的可重复性提供了基本的构建模块。PyTorch Hub包含一个经过预先培训的模型库,专门用于促进研究的可重复性和新的研究。它还内置了对Colab的支持,与Papers With Code集成,目前包含一系列广泛的模型,包括分类和分段,生成,变换器等。
[所有者]发布模型
PyTorch Hub支持通过添加简单hubconf.py文件将预先训练的模型(模型定义和预先训练的权重)发布到GitHub存储库。这提供了要支持哪些模型的枚举以及运行模型所需的依赖项列表。可以在torchvision,huggingface-bert和gan-model-zoo存储库中找到示例。
让我们看看最简单的案例:torchvision's hubconf.py:
# Optional list of dependencies required by the package
dependencies = ['torch']
from torchvision.models.alexnet import alexnet
from torchvision.models.densenet import densenet121, densenet169, densenet201, densenet161
from torchvision.models.inception import inception_v3
from torchvision.models.resnet import resnet18, resnet34, resnet50, resnet101, resnet152,\
resnext50_32x4d, resnext101_32x8d
from torchvision.models.squeezenet import squeezenet1_0, squeezenet1_1
from torchvision.models.vgg import vgg11, vgg13, vgg16, vgg19, vgg11_bn, vgg13_bn, vgg16_bn, vgg19_bn
from torchvision.models.segmentation import fcn_resnet101, deeplabv3_resnet101
from torchvision.models.googlenet import googlenet
from torchvision.models.shufflenetv2 import shufflenet_v2_x0_5, shufflenet_v2_x1_0
from torchvision.models.mobilenet import mobilenet_v2在torchvision,模型具有以下属性:
- 每个模型文件都可以独立运行和执行
- 他们不需要PyTorch以外的任何包(编码
hubconf.py为dependencies['torch']) - 他们不需要单独的入口点,因为模型在创建时可以无缝地开箱即用
最小化包依赖性可减少用户加载模型以进行即时实验的摩擦。
一个更为复杂的例子是HuggingFace的BERT模型。这是他们的hubconf.py
dependencies = ['torch', 'tqdm', 'boto3', 'requests', 'regex']
from hubconfs.bert_hubconf import (
bertTokenizer,
bertModel,
bertForNextSentencePrediction,
bertForPreTraining,
bertForMaskedLM,
bertForSequenceClassification,
bertForMultipleChoice,
bertForQuestionAnswering,
bertForTokenClassification
)然后,每个模型都需要创建一个入口点。这是一个代码片段,用于指定bertForMaskedLM模型的入口点,返回预先训练的模型权重。
def bertForMaskedLM(*args, **kwargs):
"""
BertForMaskedLM includes the BertModel Transformer followed by the
pre-trained masked language modeling head.
Example:
...
"""
model = BertForMaskedLM.from_pretrained(*args, **kwargs)
return model这些入口点可以作为复杂模型工厂的包装器。它们可以提供干净且一致的帮助文档字符串,具有支持下载预训练权重的逻辑(例如,通过pretrained=True)或具有其他特定于集线器的功能,例如可视化。
有了hubconf.py,您可以在此处根据模板发送拉取请求。我们的目标是为研究再现性策划高质量,易于重复,最有益的模型。因此,我们可能会与您合作完善您的拉取请求,并在某些情况下拒绝发布一些低质量的模型。一旦我们接受您的拉取请求,您的模型将很快出现在Pytorch中心网页上,供所有用户浏览。
[用户]工作流程
作为用户,PyTorch Hub允许您按照几个简单的步骤执行以下操作:1)探索可用的模型; 2)加载模型; 3)了解任何给定模型可用的方法。让我们来看看每个例子。
探索可用的入口点。
用户可以使用torch.hub.list()API 列出仓库中的所有可用入口点。
>>> torch.hub.list('pytorch/vision')
>>>
['alexnet',
'deeplabv3_resnet101',
'densenet121',
...
'vgg16',
'vgg16_bn',
'vgg19',
'vgg19_bn']请注意,PyTorch Hub还允许辅助入口点(除了预训练模型),例如bertTokenizer用于BERT模型中的预处理,以使用户工作流程更加平滑。
加载模型
现在我们知道Hub中可用的模型,用户可以使用torch.hub.load()API 加载模型入口点。这只需要一个命令而无需安装轮子。此外,torch.hub.help()API可以提供有关如何实例化模型的有用信息。
print(torch.hub.help('pytorch/vision', 'deeplabv3_resnet101'))
model = torch.hub.load('pytorch/vision', 'deeplabv3_resnet101', pretrained=True)回购所有者也希望不断添加错误修复或性能改进。PyTorch Hub通过调用以下内容使用户可以非常简单地获取最新更新:
model = torch.hub.load(..., force_reload=True)我们相信这将有助于减轻回购所有者重复发布包裹的负担,从而使他们能够更专注于他们的研究。它还确保您作为用户获得最新鲜的型号。
相反,稳定性对用户来说很重要。因此,一些模型所有者从特定的分支或标记而不是master分支为它们提供服务,以确保代码的稳定性。例如,pytorch_GAN_zoo从hub分支机构提供服务:
model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'DCGAN', pretrained=True, useGPU=False)请注意*args,**kwargs传递给hub.load()它用于实例化模型。在上面的例子中,pretrained=True并useGPU=False给出了模型的入口点。
探索加载的模型
从PyTorch Hub加载模型后,您可以使用以下工作流程找出支持的可用方法,并更好地了解运行它所需的参数。
dir(model)查看模型的所有可用方法。我们来看看bertForMaskedLM可用的方法。
>>> dir(model)
>>>
['forward'
...
'to'
'state_dict',
]help(model.forward) 提供了使加载的模型运行所需的参数的视图
>>> help(model.forward)
>>>
Help on method forward in module pytorch_pretrained_bert.modeling:
forward(input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None)
...仔细查看BERT和DeepLabV3页面,您可以在其中看到这些模型在加载后如何使用。
其他探索方式
PyTorch Hub中提供的模型也支持Colab,并且直接链接在Papers With Code上,您只需单击即可开始使用。这是一个很好的入门示例(如下所示)。
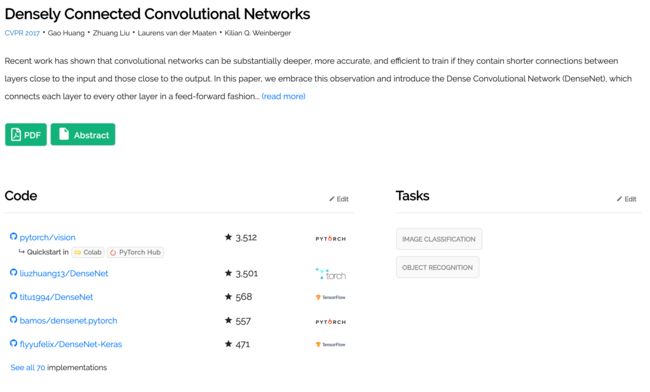
其他资源:
- 可以在此处找到PyTorch Hub API文档。
- 在此提交模型以便在PyTorch Hub中发布。
- 请访问https://pytorch.org/hub以了解有关可用模型的更多信息。
- 寻找更多型号来paperwithcode.com。
非常感谢HuggingFace,PapersWithCode团队,fast.ai和Nvidia以及Morgane Riviere(巴黎公平竞赛)以及许多其他人帮助引导这项工作!
干杯!
PyTorch团队
常问问题:
问:如果我们想贡献一个已经在Hub中的模型,但也许我的模型具有更高的准确性,我还应该贡献吗?
A:是的!! Hub的下一步是实施upvote / downvote系统以展示最佳模型。
问:谁拥有PyTorch Hub的模型权重?
答:作为贡献者,您负责承载模型权重。您可以在您喜欢的云存储中托管您的模型,或者如果它符合限制,则可以在GitHub上托管您的模型。如果您无法承载权重,请通过在集线器存储库上打开问题与我们联系。
问:如果我的模型受过私人数据培训怎么办?我还应该贡献这个型号吗?
答:不!PyTorch Hub以开放式研究为中心,并扩展到使用开放数据集来训练这些模型。如果提交了专有模型的拉取请求,我们将恳请您重新提交受过开放和可用的模型培训。
问:我下载的模型保存在哪里?
答:我们遵循XDG基本目录规范,并遵循缓存文件和目录的通用标准。
这些位置按以下顺序使用:
- 调用
hub.set_dir() $TORCH_HOME/hub,如果TORCH_HOME设置了环境变量。$XDG_CACHE_HOME/torch/hub,如果XDG_CACHE_HOME设置了环境变量。~/.cache/torch/hub
===================
原文链接:
https://pytorch.org/blog/towards-reproducible-research-with-pytorch-hub/
还有问题的,可以加群264191384 注明(pytorch)
-