基于opencv的车牌号码识别 必备基础知识
车牌号码识别 必备基础知识
- 1、cv2.split 拆分通道
- 2、cv2.merge 通道合并
- 3、cv2.imshow() 和 plt.show()
- 4、卷积及相关操作
- 5、cv2.GaussianBlur() 高斯模糊
- 6、cv2.medianBlur() 中值模糊
- 7、去噪
- 8、cv2.cvtColor (颜色空间转换函数)
- 9、灰度处理
- 10、cv2.Sobel()
- 11、cv2.convertScaleAbs()函数
- 12、cv2.imshow() 显示图像
- 13、cv2.threshold() 简单阈值函数
- 14、cv2.getStructuringElement()
- 15、cv2.morphologyEx() 形态学变化函数
- 16、开运算、闭运算
- 17、cv2.dilate()、cv2.erode() 膨胀和腐蚀
- 18、cv2.findContours()查找轮廓,cv2.drawContours() 绘制轮廓
- 19、cv2.boundingRect()cv2.rectangle()
- 20、for in 循环
- 21、range()
- 21、image.shape
- 22、list.append()
- 23、plt.barh() plt.bar()绘制柱状图
- 24、sorted() 排序函数
- 25、enumerate() 函数
- 26、os.listdir()
- subplot() 切割
- python 创建数组,创建列表
-
- (1)创建数组
- (2)创建列表
- python 切片操作
1、cv2.split 拆分通道
#拆分通道
import cv2
img = cv2.imread('D:/z/car.png') #opencv读取图像文件
b, g ,r =cv2.split(img) #顺序是b,g,r,不是r,g,b
merged = cv2.merge([b,g,r])
cv2.imshow('image',img)
cv2.imshow("Blue 1", b)
cv2.imshow("Green 1", g)
cv2.imshow("Red 1", r)
cv2.imshow("merged 1", merged)
cv2.waitKey(0)
运行结果如下图:
2、cv2.merge 通道合并
import cv2
import numpy as np
img = cv2.imread('D:/z/car.png')
b, g ,r =cv2.split(img)
zeros = np.zeros(img.shape[:2], dtype = "uint8")
merged_r = cv2.merge([zeros,zeros,r]) #通道分量为零可以理解为零矩阵
cv2.imshow('image',img)
cv2.imshow("Red 1", r)
cv2.imshow("merged_r",merged_r)
cv2.waitKey(0)
运行结果如下:
注:
zeros = np.zeros(img.shape[:2], dtype = "uint8")
①
在用numpy 去创建一个矩阵并想用它生成图片时一定要记住,矩阵中每个元素的类型必须是 dtype=np.uint8 也可以这样写 dtype = “uint8”
②
[0:2]是切片的意思,.shape 应当是OpenCV模块中处理图片的,是图片的一个属性,这个属性是个列表 ,然后对这个列表切片操作。
img.shape[ : 2] 表示取彩色图片的长、宽。
img.shape[ : 3] 则表示取彩色图片的长、宽、通道。
关于img.shape[0]、[1]、[2]
img.shape[0]:图像的垂直尺寸(高度)
img.shape[1]:图像的水平尺寸(宽度)
img.shape[2]:图像的通道数
在矩阵中,[0]就表示行数,[1]则表示列数。
3、cv2.imshow() 和 plt.show()
在用plt.imshow和cv2.imshow显示同一幅图时可能会出现颜色差别很大的现象。
这是因为:opencv的接口使用BGR,而matplotlib.pyplot 则是RGB模式
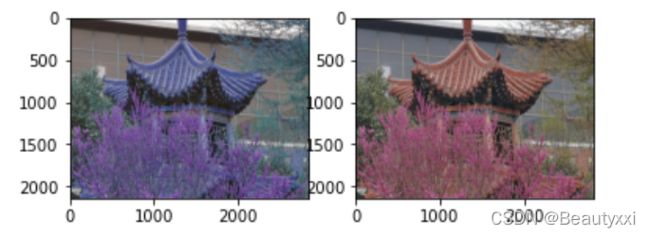
例一:
import cv2
import numpy as np
import matplotlib.pyplot as plt
img = cv2.imread('D:/z/love.jpg') #opencv接口 BGR !!!!!!
b,g,r = cv2.split(img)
img2 = cv2.merge([r,g,b]) #plt接口 RGB !!!!!
plt.subplot(121);plt.imshow(img)
plt.subplot(122);plt.imshow(img2)
plt.show()
运行结果如下图所示:
例二:
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('D:/z/car.png')
b,g,r = cv2.split(img)
image= cv2.merge([r,g,b])
image_merged = cv2.merge([r,g,b])
plt.figure(figsize=(10,6))
plt.subplot(2,3,1), plt.title('image') #原图
plt.imshow(image), plt.axis('on')
plt.subplot(2,3,2), plt.title('image_gray') #灰度图片
plt.imshow(img,cmap='gray'), plt.axis('off')
plt.subplot(2,3,3), plt.title('image_merged')
plt.imshow(image_merged), plt.axis('off')
plt.subplot(2,3,4), plt.title('r')
plt.imshow(r,cmap='gray'), plt.axis('off') # r通道
plt.subplot(2,3,5), plt.title('g')
plt.imshow(g,cmap='gray'), plt.axis('off') # g通道
plt.subplot(2,3,6), plt.title('b')
plt.imshow(b,cmap='gray'), plt.axis('off') # b通道
plt.show()
运行结果如下:

①
plt.imshow(img,cmap='gray')
转换为灰度图
②
plt.subplot(2,3,1)
一个窗口显示多幅图像,要用到subplot
使用 plt.subplot 来创建小图。
eg:plt.subplot (2,3,1) 表示将整个图像窗口分为2行3列,当前位置为1
③
plt.axis('off')
关闭坐标轴
4、卷积及相关操作
①
在数字图像处理领域,早就被广泛应用于邻域处理,只是当年的叫法是“滤波器”。
卷积是一种广泛使用的数学运算,它在处理图像时对每个像素都计算该像素值和它相邻的像素值的一个加权和。其实很好理解,就是内积操作。
②
用模板(掩膜/卷积核/滤波器)来进行卷积是非常通用的图像处理方法,现在的卷积神经网络就是最成功的一个应用。
传统的方法是人工挑选卷积核,对于不同的卷积核,可以获得不同的结果,如图像模糊、图像锐化或边缘检测。
③
利用水平边缘卷积核,可以提取出水平的一些直线出来,当然还有垂直边缘检测卷积核,可以提取垂直的一些线条出来,这在字符识别、车牌识别很有用。
卷积和相关操作
除了这篇,还有个专题,有很多介绍。
5、cv2.GaussianBlur() 高斯模糊
①
高斯模糊GaussianBlur()中 参数详解
原型:
cv2.GaussianBlur( SRC,ksize,sigmaX [,DST [,sigmaY [,borderType ] ] ] ) →DST
参数:
src 输入图像;图像可以具有任何数量的信道,其独立地处理的,但深度应CV_8U,CV_16U,CV_16S,CV_32F或CV_64F。
dst 输出与图像大小和类型相同的图像src。
ksize 高斯核大小。 ksize.width 并且 ksize.height 可以有所不同,但它们都必须是正数和奇数。或者,它们可以为零,然后从计算 sigma*。
sigma 如果sigma为非正数(负数或0)的话,就会根据ksize来自动计算sigma,计算公式为sigma = 0.3*((ksize-1)*0.5-1)+0.8
sigmaX – X方向上的高斯核标准偏差。
sigmaY – Y方向上的高斯核标准差;如果 sigmaY 为零,则将其设置为等于 sigmaX;如果两个西格玛均为零,则分别根据ksize.width 和 进行计算 ksize.height(getGaussianKernel()有关详细信息,请参见 link);完全控制的结果,无论这一切的语义未来可能的修改,建议指定所有的ksize,sigmaX和sigmaY。
borderType –像素外推方法。
②
在不知道用什么滤波器好的时候,优先高斯滤波 cv2.GaussianBlur(),然后均值滤波 cv2.blur()
③
高斯滤波是一种线性平滑滤波
高斯滤波是对整幅图像进行加权平均的过程,每一个像素点的值都由其本身和邻域内的其他像素值经过加权平均后得到。高斯滤波的具体操作是:用一个模板(或称卷积、掩模)扫描图像中的每一个像素,用模板确定的邻域内像素的加权平均灰度值去替代模板中心像素点的值。
基于二维高斯函数,构建权重矩阵,进而构建高斯核,最终对每个像素点进行滤波处理(平滑、去噪)
6、cv2.medianBlur() 中值模糊
概念:
中值滤波法是一种非线性平滑技术,它将每一像素点的灰度值设置为该点某邻域窗口内的所有像素点灰度值的中值。
函数原型:
cv2.medianBlur(src, ksize[, dst]) -> dst
参数说明:
src:待处理的输入图像;
ksize:参数表示滤波窗口尺寸,必须是奇数并且大于 1。比如这里是 5,中值滤波器就会使用 5×5 的范围来计算,即对像素的中心值及其 5×5 邻域组成了一个数值集,对其进行处理计算,当前像素被其中值替换掉;
dst:参数表示输出与 src 相同大小和类型的图像。
中值模糊一般用在存在一些躁声点图像,例如白噪声,可以去除。
一般用来处理图像的椒盐噪声。
7、去噪
去噪有分为时域去噪和频域去噪
①
时域去噪通常手法为:
中值滤波: Media_Image 中值滤波的原理是拿特征区域在图像滑动,每一点(与特征区域的中点重合)的值为特征区域所覆盖的范围的中值
均值滤波: mean_image 均值滤波的原理是拿特征区域在图像滑动,每一点(与特征区域的中点重合)的值为特征区域所覆盖的范围的均值
高斯滤波: guss_image 高斯滤波的原理类似,只不过特征区域内的每个点做了加权处理,可以根据需要让哪个单元的权重大,哪个单元的权重小
②
频域内的去噪
高通滤波 :让图像中高频部分通过,通常会留下边缘,起到锐化的作用
低通滤波 :让图像的低频部分通过,通常弱化边缘,会得到比较平缓的图像
中通滤波:让图像中中频部分通过
高斯滤波
③
关于滤波和模糊:
它们都属于卷积,不同滤波方法之间只是卷积核不同(对线性滤波而言)
低通滤波器是模糊,高通滤波器是锐化
低通滤波器就是允许低频信号通过,在图像中边缘和噪点都相当于高频部分,所以低通滤波器用于去除噪点、平滑和模糊图像。
低通滤波器则是在像素与周围像素的亮度差值小于一个特定值时,平滑该像素的亮度。主要用于去噪和模糊化,如高斯模糊是最常用的模糊滤波器,是一个削弱高频信号强度的低通滤波器。
高通滤波器则反之,用来增强图像边缘,进行锐化处理。
高通滤波器(HPF)是检测图像的某个区域,然后根据像素与周围像素的亮度差值来提升该像素的亮度的滤波器。也就是说,如果一个像素比它周围的像素更突出,就会提升它的亮度。
【注意常见的噪声有椒盐噪声和高斯噪声,椒盐噪声可以理解为斑点,随机出现在图像中的黑点或白点;高斯噪声可以理解为拍摄图片时由于光照等原因造成的噪声。】
④
模糊
均值模糊:一般用来处理图像的随机噪声;
中值模糊:一般用来处理图像的椒盐噪声;
自定义模糊:对图像进行增强,锐化等操作。
8、cv2.cvtColor (颜色空间转换函数)
cv2.cvtColor(p1, p2) 是颜色空间转换函数,p1是需要转换的图片,p2是转换成何种格式。
cv2.COLOR_BGR2RGB 将BGR格式转换成RGB格式
cv2.COLOR_BGR2GRAY 将BGR格式转换成灰度图片 (效果不同3、①,我也暂时不知道为啥…)
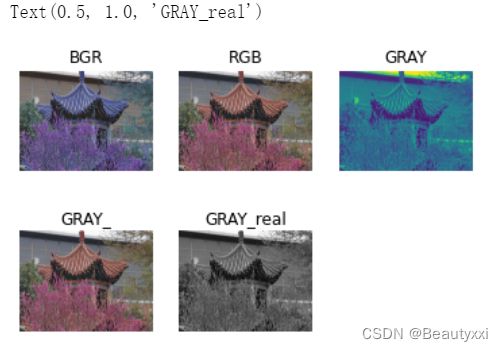
import matplotlib.pyplot as plt
import cv2
# cv2.imread()接口读图像,读进来直接是BGR 格式数据格式在 0~255,通道格式为(W,H,C)
img_BGR = cv2.imread('D:/z/love.jpg') # BGR
plt.subplot(2,3,1)
plt.imshow(img_BGR)
plt.axis('off')
plt.title('BGR')
img_RGB = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2RGB) # BGR 转化为 RGB
plt.subplot(2,3,2)
plt.imshow(img_RGB)
plt.axis('off')
plt.title('RGB')
img_GRAY = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2GRAY) # BGR 转化为 GRAY
plt.subplot(2,3,3)
plt.imshow(img_GRAY)
plt.axis('off')
plt.title('GRAY')
plt.subplot(2,3,4)
img_GRAY1 = plt.imshow(img_RGB, cmap='gray')
plt.show
plt.axis('off')
plt.title('GRAY_')
plt.subplot(2,3,5)
img_GRAY1 = plt.imshow(img_GRAY, cmap='gray')
plt.show
plt.axis('off')
plt.title('GRAY_real')
运行结果如下:
9、灰度处理
在图像处理过程中,三个通道的数据比较复杂,那就可以先将图像进行灰度化处理。
灰度化的过程就是将每个像素点的RGB值统一成同一个值。灰度化后的图像将由三通道变为单通道,单通道的数据处理起来就会简单许多。
具体见上例后两张图。
处理1、
img_GRAY = cv2.cvtColor(img_BGR, cv2.COLOR_BGR2GRAY)
img_GRAY1 = plt.imshow(img_GRAY, cmap='gray')
两步一起会得到灰色的图
处理2、
img = cv2.imread('D:/z/car.png',cv2.IMREAD_GRAYSCALE)
运行代码发现这样竟然可以直接变成灰度图,amazing,不知道能不能直接用。
①
plt 画出的图像和原图有色差
opencv的颜色通道顺序为[B,G,R],而matplotlib的颜色通道顺序为[R,G,B]。
需要把R和B的位置调换一下。
②
进行灰度处理之后,plt显示的图片是绿色的
因为还是直接使用plt显示图像,它默认使用三通道显示图像。
在plt.imshow()添加参数:plt.imshow(img_gray,cmap="gray")就可以显示灰色了
③
不过,为什么单独使用plt.imshow(img_gray,cmap="gray")一点用都没有呀!!(见 5、中最后一张图)
生气,如果有机会问问。
④
灰度图像
指的是R=G=B,灰度图像只有256种取值可能。
⑤
灰度化处理
减少在图像处理过程中的计算量。将彩色图像灰度化处理以后可从起初的0-256256256缩小到0-255这256种情况,能够大大降低运算量,这是我们在进行图像处理希望看到的。
(emm…还是不理解为啥就降低运算量了,那图片不就颜色少了)
10、cv2.Sobel()
概述: 利用Sobel算子进行图像梯度计算
使用函数 cv2.Sobel()获取图像水平、垂直 及 水平和垂直叠加方向的完整边缘信息。
格式:
cv2.Sobel(src, ddepth, dx, dy[, ksize[, scale[, delta[, borderType]]]])
参数:
src: 输入图像
ddepth: 输出图像的深度(可以理解为数据类型),-1表示与原图像相同的深度
图像深度是指存储每个像素值所用的位数,例如cv2.CV_8U,指的是8位无符号数,取值范围为0~255,超出范围则会被截断(截断指的是,当数值大于255保留为255,当数值小于0保留为0,其余不变)。
具体还有:CV_16S(16位无符号数),CV_16U(16位有符号数),CV_32F(32位浮点数),CV_64F(64位浮点数)
dx,dy: 当组合为dx=1,dy=0时求x方向的一阶导数;当组合为dx=0,dy=1时求y方向的一阶导数(如果同时为1,通常得不到想要的结果)
ksize: (可选参数)Sobel算子的大小,必须是1,3,5或者7,默认为3。
求X方向和Y方向一阶导数时,卷积核分别为:
scale:(可选参数)将梯度计算得到的数值放大的比例系数,效果通常使梯度图更亮,默认为1
delta:(可选参数)在将目标图像存储进多维数组前,可以将每个像素值增加delta,默认为0
borderType:(可选参数)决定图像在进行滤波操作(卷积)时边沿像素的处理方式,默认为BORDER_DEFAULT
返回值: 梯度图
测试① 理解一下获取水平垂直方向边缘信息(?白色的就略掉了)
例1(水平方向):
import cv2
img = cv2.imread('D:/z/gezi.png',cv2.IMREAD_GRAYSCALE)
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0)
sobelx = cv2.convertScaleAbs(sobelx) # 转回uint8
cv2.imshow("original",img)
cv2.imshow("x",sobelx)
cv2.waitKey()
cv2.destroyAllWindows()
结果如下图所示:
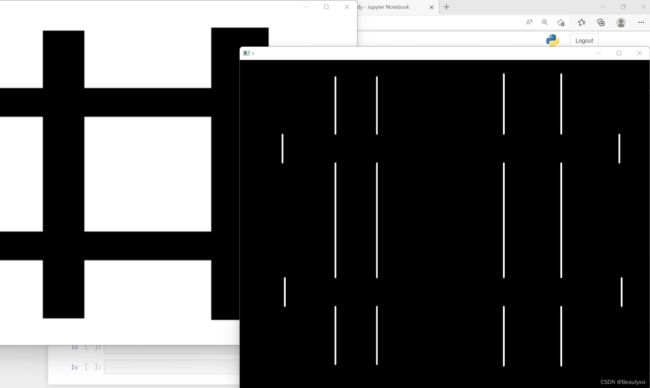
例2(垂直方向):
import cv2
img = cv2.imread('D:/z/gezi.png',cv2.IMREAD_GRAYSCALE)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1)
sobely = cv2.convertScaleAbs(sobely)
cv2.imshow("original",img)
cv2.imshow("y",sobely)
cv2.waitKey()
cv2.destroyAllWindows()
结果如下:

测试② 深度值不同时:
import cv2
#载入原图
img_original=cv2.imread('D:/z/hb.png',0)
#求X方向梯度,并且输出图像一个为CV_8U,一个为CV_64F
img_gradient_X_8U=cv2.Sobel(img_original,-1,1,0)
img_gradient_X_64F=cv2.Sobel(img_original,cv2.CV_64F,1,0)
#将图像深度改为CV_8U
img_gradient_X_64Fto8U=cv2.convertScaleAbs(img_gradient_X_64F)
#图像显示
cv2.imshow('X_gradient_8U',img_gradient_X_8U)
cv2.imshow('X_gradient_64F',img_gradient_X_64F)
cv2.imshow('X_gradient_64Fto8U',img_gradient_X_64Fto8U)
cv2.waitKey()
cv2.destroyAllWindows()
运行结果如下图所示:
例1:
例2:
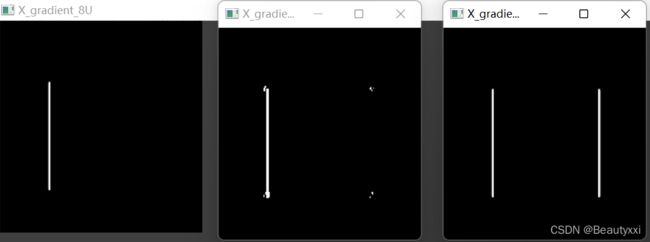
(具体为啥会有这种区别,emm…时间问题暂时不展开了,如果小赵老师会而且愿意给我讲的话,我再回来给解答哈)
11、cv2.convertScaleAbs()函数
函数格式:cv2.convertScaleAbs(src[,alpha[,beta]])
概述:
通过线性变换将数据转换成8位[uint8]
先计算数组绝对值,后转化为8位无符号数
参数:
src:输入图像(多维数组)
alpha:比例因子
beta:保存新图像(数组)前可以增加的值
使用了函数cv2.convertScaleAbs()将图像深度为其他梯度图像重新转化为CV_8U,这是由于函数cv2.imshow()的默认显示为8位无符号数,即[0,255]
12、cv2.imshow() 显示图像
cv2.imread(图片,**cv2.IMREAD_GRAYSCALE**)
cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道
cv2.IMREAD_GRAYSCALE:读入灰度图片(竟然可以直接变成灰色的)
cv2.IMREAD_UNCHANGED:顾名思义,读入完整图片,包括alpha通道
13、cv2.threshold() 简单阈值函数
阈值的作用是根据设定的值处理图像的灰度值,比如灰度大于某个数值像素点保留。通过阈值以及有关算法可以实现从图像中抓取特定的图形,比如去除背景等。
函数
Python: cv2.threshold(src, thresh, maxval, type[, dst]) → retval, dst
参数:
src:表示的是图片源
thresh:表示的是阈值(起始值)
maxval:表示的是最大值(待填充色值?)
type:表示的是这里划分的时候使用的是什么类型的算法,常用值为0(cv2.THRESH_BINARY)
cv2.THRESH_BINARY_INV

另外的取值为:
cv2.THRESH_OTSU
cv2.THRESH_TRIANGLE
cv2.THRESH_MASK
cv2.THRESH_BINARY 大于阈值的部分被置为255,小于部分被置为0
cv2.THRESH_BINARY_INV 大于阈值部分被置为0,小于部分被置为255
cv2.THRESH_TRUNC 大于阈值部分被置为threshold,小于部分保持原样
cv2.THRESH_TOZERO 小于阈值部分被置为0,大于部分保持不变
cv2.THRESH_TOZERO_INV 大于阈值部分被置为0,小于部分保持不变
cv2.THRESH_OTSU,并且把阈值thresh设为0,算法会找到最优阈值,并作为第一个返回值ret返回。
当使用cv2.THRESH_OTSU或cv2.THRESH_TRIANGLE时,阈值是动态的,会根据计算结果返回相应的数值。
寻找方法是遍历所有可能的阈值,通过一个公式,计算方差,方差最小的阈值就是选中的阈值。
自适应阈值分割。
cv2.THRESH_OTSU使用最小二乘法处理像素点
cv2.THRESH_TRIANGLE使用三角算法处理像素点。
一般情况下,cv2.THRESH_OTSU适合双峰图。cv2.THRESH_TRIANGLE适合单峰图。单峰图或者双峰图指的是灰度直方图。
14、cv2.getStructuringElement()
Opencv中函数getStructuringElement()可以生成形态学操作中用到的核,函数原型:
getStructuringElement(shape, ksize,Point anchor=Point(-1,-1));
参数:
shape:核的形状
ksize:核的大小
Point anchor:核中心位置,默认位于形状中心处
矩形:MORPH_RECT;
交叉形:MORPH_CROSS;
椭圆形:MORPH_ELLIPSE;
第二和第三个参数分别是内核的尺寸以及锚点的位置。一般在调用erode以及dilate函数之前,先定义一个Mat类型的变量来获得
返回值:
对于锚点的位置,有默认值Point(-1,-1),表示锚点位于中心点。element形状唯一依赖锚点位置,其他情况下,锚点只是影响了形态学运算结果的偏移。
膨胀或者腐蚀操作就是将图像(或图像的一部分区域,我们称之为A)与核(我们称之为B)进行卷积。
kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (17, 5))
print(kernelX)
运行结果如下:

15、cv2.morphologyEx() 形态学变化函数
函数形式:dst = cv.morphologyEx(src, op, kernel)
参数:
src: 输入图片
op:
MORPH_OPEN – 开运算(Opening operation)先腐蚀再膨胀。开运算可以用来消除小黑点,在纤细点处分离物体、平滑较大物体边界的同时并不明显改变其面积。
MORPH_CLOSE – 闭运算(Closing operation)先膨胀再腐蚀。闭运算可以用来排除小黑洞。
MORPH_GRADIENT - 形态学梯度(Morphological gradient)边缘。可以突出团块(blob)的边缘,保留物体的边缘轮廓。
MORPH_TOPHAT - 顶帽(Top hat)突出亮区。突出比原轮廓亮的部分。
MORPH_BLACKHAT - 黑帽(Black hat)突出暗区。将突出比原轮廓暗的部分。
MORPH_ERODE - 腐蚀 (erode)
MORPH_DILATE - 膨胀 (dilate)
kernel: 利用cv2.getStructuringElement()函数构造
16、开运算、闭运算
开运算和闭运算就是将腐蚀和膨胀按照一定的次序进行处理。但这两者并不是可逆的,即先开后闭并不能得到原先的图像。
闭运算用来连接被误分为许多小块的对象,而开运算用于移除由图像噪音形成的斑点。
开运算可以用来消除小黑点,在纤细点处分离物体、平滑较大物体的边界的 同时并不明显改变其面积。
闭运算可以用来排除小黑洞。
因此,某些情况下可以连续运用这两种运算。如对一副二值图连续使用闭运算和开运算,将获得图像中的主要对象。同样,如果想消除图像中的噪声(即图像中的“小点”),也可以对图像先用开运算后用闭运算,不过这样也会消除一些破碎的对象。
17、cv2.dilate()、cv2.erode() 膨胀和腐蚀
这里有比较详细介绍:形态学图像处理:膨胀和腐蚀
膨胀与腐蚀能实现多种多样的功能,主要如下:
消除噪声;分割(isolate)出独立的图像元素,在图像中连接(join)相邻的元素;寻找图像中的明显的极大值区域或极小值区域;求出图像的梯度。
腐蚀和膨胀是对 白色部分(高亮部分) 而言的,不是黑色部分。膨胀就是图像中的高亮部分进行膨胀,“领域扩张”,效果图拥有比原图更大的高亮区域。腐蚀就是原图中的高亮部分被腐蚀,“领域被蚕食”,效果图拥有比原图更小的高亮区域。
膨胀就是求局部最大值的操作,腐蚀就是求局部最小值的操作。
使用erode函数,一般我们只需要填前面的三个参数,后面的四个参数都有默认值。而且往往结合getStructuringElement一起使用。
import cv2
import numpy as np
img = cv2.imread('D:/binary.bmp',0)
#OpenCV定义的结构元素
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3, 3))
#腐蚀图像
eroded = cv2.erode(img,kernel)
#显示腐蚀后的图像
cv2.imshow("Eroded Image",eroded);
#膨胀图像
dilated = cv2.dilate(img,kernel)
#显示膨胀后的图像
cv2.imshow("Dilated Image",dilated);
#原图像
cv2.imshow("Origin", img)
#NumPy定义的结构元素
NpKernel = np.uint8(np.ones((3,3)))
Nperoded = cv2.erode(img,NpKernel)
#显示腐蚀后的图像
cv2.imshow("Eroded by NumPy kernel",Nperoded);
cv2.waitKey(0)
cv2.destroyAllWindows()
运行结果如下:

18、cv2.findContours()查找轮廓,cv2.drawContours() 绘制轮廓
cv2.findContours()函数接受的参数为二值图,即黑白的(不是灰度图),所以读取的图像要先转成灰度的,再转成二值图
函数形式:(查找轮廓)
cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
参数:
image: 输入图像
mode: 表示轮廓的检索模式,有四种:
cv2.RETR_EXTERNAL表示只检测外轮廓
cv2.RETR_LIST检测的轮廓不建立等级关系
cv2.RETR_CCOMP建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE建立一个等级树结构的轮廓。
method: 轮廓的近似办法
cv2.CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y2-y1))==1
cv2.CHAIN_APPROX_SIMPLE压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
返回值:
contours: 一个列表,每一项都是一个轮廓, 不会存储轮廓所有的点,只存储能描述轮廓的点
hierarchy: 一个ndarray, 元素数量和轮廓数量一样, 每个轮廓contours [ i ] 对应4个hierarchy元素hierarchy [i] [0] ~ hierarchy[i][3],分别表示后一个轮廓、前一个轮廓、父轮廓、内嵌轮廓的索引编号,如果没有对应项,则该值为负数。
函数形式:(绘制轮廓)
cv2.drawContours(image, contours, contourIdx, color, thickness=None, lineType=None, hierarchy=None, maxLevel=None, offset=None)
参数:
image: 指明在哪幅图像上绘制轮廓。image为三通道才能显示轮廓
contours: 轮廓本身,在Python中是一个list
contoursldx: 指定绘制轮廓list中的哪条轮廓,如果是 -1,则绘制其中的所有轮廓。
thickness: 表明轮廓线的宽度,如果是-1(cv2.FILLED),则为填充模式。
lineType: 线型
hierarchy: 轮廓结构信息
19、cv2.boundingRect()cv2.rectangle()
用一个最小的矩形,把找到的形状包起来。
函数形式:
cv2.boundingRect(img) -->(x, y, w, h)
参数:
img是一个二值图
返回:
四个值,分别是x,y,w,h;
x,y是矩阵左上点的坐标,w,h是矩阵的宽和高
然后利用cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2) 画出矩形
参数解释
第一个参数:img是输入图像
第二个参数:(x,y)是矩阵的左上点坐标
第三个参数:(x+w,y+h)是矩阵的右下点坐标
第四个参数:(0,255,0)是画线对应的rgb颜色
第五个参数:2是所画的线的宽度
import cv2
import matplotlib.pyplot as plt
img = cv2.imread('D:/z/hb.png')
x,y,w,h = cv2.boundingRect(img)
cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)
plt.imshow(img)
运行结果…

哭了…为啥运行不出来…
我也整不明白为啥,就这吧,气死我啦!!!
小赵老师理理我吧,孩子敲不下去了T_T
20、for in 循环
循环结构的一种,经常用于遍历字符串、列表、元组、字典等。
格式:
for x in y:
循环体
执行流程:
x 依次表示 y 中的一个元素,遍历完所有元素循环结束
21、range()
函数形式:
range(start, stop[, step])
Python3 range() 返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表
参数说明:
start: 计数从 start 开始。默认是从 0 开始。例如range(5) 等价于range(0,5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0,5)是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0,5)等价于 range(0, 5, 1)
21、image.shape
输出三个参数
(高,宽,通道数)
image.shape[0], 图片高
image.shape[1], 图片宽
image.shape[2], 图片通道数
貌似得到的是数组。
22、list.append()
描述:
用于在列表末尾添加新的对象。
语法:
list.append(obj)
参数:
obj:添加到列表末尾的对象。
返回值:
该方法无返回值,但是会修改原来的列表。
eg:
List = [123, 'zxx', 'love', 'z']
List.append( 2022 )
print("New List:", List)
运行结果如下:

23、plt.barh() plt.bar()绘制柱状图
plt.bar():正常柱状图,常见的统计图;
plt.barh():横向的柱状图,可以理解为正常柱状图旋转了90°。
参数解释:
plt.bar()
函数形式:bar(x, height, width=0.8, bottom=None, ***, align='center', data=None, **kwargs)
x:表示x坐标,数据类型为int或float类型,刻度自适应调整;也可传dataframe的object,x轴上等间距排列;
height:表示柱状图的高度,也就是y坐标值,数据类型为int或float类型;
width:表示柱状图的宽度,取值在0~1之间,默认为0.8;
bottom:柱状图的起始位置,也就是y轴的起始坐标;
align:柱状图的中心位置,默认"center"居中,可设置为"lege"边缘;
color:柱状图颜色;“r",“b”,“g”,“#123465”,默认“b"
edgecolor:边框颜色;同上
linewidth:边框宽度; 像素,默认无,int
tick_label:下标标签;
log:柱状图y周使用科学计算方法,bool类型;
orientation:柱状图是竖直还是水平,竖直:“vertical”,水平条:“horizontal”;
plt.barh()
y:表示y坐标,数据类型为int或float类型,刻度自适应调整;也可传dataframe的object,y轴上等间距排列;
height:表示柱状图的长度,也就是x坐标值,数据类型为int或float类型;
width:表示柱状图的高度,取值在0~1之间,默认为0.8;
其他参数与plt.bar()类似。
plt.xlabel() 设置x轴标签
plt.xticks() 设置刻度
24、sorted() 排序函数
函数形式:
sorted(iterable, cmp=None, key=None, reverse=False)
参数说明:
iterable :可迭代对象。
cmp :比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
key :主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse :排序规则,reverse = True 降序 , reverse = False 升序(默认)。
返回值:
返回重新排序的列表。
eg:
L = [('b',3),('a',4),('c',2),('d',1)]
newL = sorted(L, key=lambda x:x[1]) #key=lambda x:x[1] 表示按第二个元素升序排列
print(newL)
运行结果如下:

25、enumerate() 函数
描述:
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
Python 2.3. 以上版本可用,2.6 添加 start 参数。
函数形式:
enumerate(sequence, [start=0])
参数:
sequence:一个序列、迭代器或其他支持迭代对象。
start:下标起始位置的值。
返回值:
返回 enumerate(枚举) 对象。
eg:
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
list(enumerate(seasons))
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
list(enumerate(seasons, start=1))
seq = ['one', 'two', 'three']
for i, element in enumerate(seq):
print(i, element)
#输出的时候i值自动加一,element后移输出,结果同如下for循环
i = 0
seq = ['one', 'two', 'three']
for element in seq:
print(i, seq[i])
i += 1
运行结果如下:
26、os.listdir()
描述:
用于返回指定的文件夹包含的文件或文件夹的名字的列表
函数形式:
os.listdir(path)
参数:
path:需要列出的目录路径
返回值:
返回指定路径下的文件和文件夹列表
subplot() 切割
描述:
把figure分成nrows*ncols的子图表示
函数形式:
subplot(nrows, ncols, plot_number)
或者写成subplot(nrows ncols plot_number)(中间不用逗号,前提是只能是三位数)
参数:
nrows:子图的行数
ncols:子图的列数
plot_number :索引值,表示把图画在第plot_number个位置(从左下角到右上角)。即图形的标号
python 创建数组,创建列表
(1)创建数组
Python中没有数组只有元组和列表
Python中的NumPy模块最主要的特点就是引入了数组的概念。数组是一些相公类型的数据集合,这些数据按照一定的顺序排列,并且每个数据占用大小相同的存储空间。要使用数组组织数据,首先就要创建数组。NumPy模块提供了多种创建数组的方法,如下列举一下:
(1)使用array()函数创建数组
函数可基于序列型的对象(如列表、元组、集合等,还可以是一个已经创建好的数组)
(2)创建等差数组
用arange()函数创建数组
eg:
import numpy as np
d=np.arange(1,20,3)#起始值是1,结束值是20(结果不含该值),步长为1
print(d)
(3)创建随机数组
引用numpy模块的子模块random中的函数,主要有rand()函数、randn()函数、randint()函数。
rand()函数创建的数组中每个元素都是[0,1)区间内的随机数
randn()函数创建的数组中的元素是符合标准正态分布(均值为0,标准差为1)的随机数
randint()函数创建的数组中元素是制定范围内的随机整数
(2)创建列表
创建列表的4种方式:
(1)基本语法创建
零个,一个或一系列数据用逗号隔开,放在方括号[ ]内就是一个列表对象。列表内的数据可以是多个数目,不同类型。
eg:
a = [1,23,’开心’,’nice’]
a = [ ] # 创建一个空的列表对象
(2)list创建
①使用list()可以将任意可迭代的数据转化成列表。用 list([iterable])函数返回一个列表。可选参数iterable是可迭代的对象,例如字符串,元组。list()函数将可迭代对象的元素重新返回为列表。
②将字典类型数据作为参数时,返回的列表元素是字典的键。
③将range()函数作为参数,返回一个整数元素的列表。
④如果没有参数list()函数将返回一个空列表。eg:a = list() #创建一个空的列表对象
(3)range()创建整数列表
range() 可以方便的创建整数列表,这在开发中很有用, 语法格式为:
range( [start,] end [,step] )
Start 参数: 可选, 表示起始数字,默认是0;
End 参数: 必选, 表示结尾数字;
Step 参数: 可选, 表示步长, 默认为1
Python3中 range() 返回的是一个range对象, 而不是列表; 我们需要通过 list() 方法将其转换成列表对象;
注意: 步长为负数, 从右往回数,此时,start应该大于end
(4)推导式生成列表
使用列表推导式可以非常方便的创建列表, 在开发中经常使用;在for循环和if语句重点练习
(5)利用split分割字符串生成列表
字符串调用split方法返回一个由分开的子串组成的列表。
求列表长度:len(list)
python 切片操作
Python切片操作的一般方式:
一个完整的切片表达式包含两个“ :”,用于分隔三个参数(start_index、end_index、step),当只有一个“ :”时,默认第三个参数step=1。
切片操作基本表达式:
object [ start_index : end_index : step ]
step:正负数均可,其绝对值大小决定了切取数据时的“步长”,而正负号决定了“切取方向”,正表示“从左往右”取值,负表示“从右往左”取值。当step省略时,默认为1,即从左往右以增量1取值。
start_index:表示起始索引(包含该索引本身);该参数省略时,表示从对象“端点”开始取值,至于是从“起点”还是从“终点”开始,则由step参数的正负决定,step为正从“起点”开始,为负从“终点”开始。
end_index:表示终止索引(不包含该索引本身);该参数省略时,表示一直取到数据”端点“,至于是到”起点“还是到”终点“,同样由step参数的正负决定,step为正时到“终点”,为负时到“起点”。
具体例子:Python切片操作