解读最佳实践:倚天 710 ARM 芯片的 Python+AI 算力优化 | 龙蜥技术
编者按:在刚刚结束的 PyCon China 2022 大会上,龙蜥社区开发者朱宏林分享了主题为《ARM 芯片的 Python+AI 算力优化》的技术演讲。本次演讲,作者将向大家介绍他们在倚天 710 ARM 芯片上开展的 Python+AI 优化工作,以及在 ARM 云平台上部署 Python+AI 任务的最佳实践。
以下为本次演讲内容:
(图/朱宏林现场演讲)

我们的场景是 ARM 平台的和 AI 相关的任务,主要的目标是进行性能优化,具体来说我们首先关注的是深度学习推理任务(inference task),主要原因也是来自于业务需求。
这里说的 ARM 平台不是我们理解的终端设备,比如手机之类的,而是指服务端平台。在大家印象中,AI 任务,特别是深度学习的程序一般是跑在 GPU 或者 x86 的 CPU 上,出于功耗、成本、性能等因素的考虑,云厂商逐步开始建设 ARM 架构的服务平台,这是一个趋势。当然 ARM 平台还不是很成熟,许多软件还无法成功跑起来,更不要说提升性能了。
我们想要吸引一部分用户将AI应用从原先的 x86 平台上迁移到 ARM 平台上。这就要求 ARM 平台能提供更好的性能,或者更好的性价比。所以说如何整合 Python+AI 的相关软件使其发挥最好的性能成为了我们关注的重点。
下文的分享整体分为两部分,一部分是介绍我们进行的优化工作,主要是跟矩阵乘法相关的优化,第二部分是关于 Python AI 应用在 ARM 云平台-倚天 710 上的最佳实践。
一、优化工作介绍

前面说我们的优化是和矩阵乘法相关的,那首先需要说明为什么我们会关注到这个。
这里有一个绕不开的场景就是深度学习,不管是前几年知名的 AlphaGo,还是当前火热的 ChatGPT,都用到了大量深度学习的技术,深度学习本身只是AI的一个分支,但却影响广泛,不容忽视。所以我们从深度学习开始切入,从当前最广泛使用的深度学习框架,TensorFlow 和 PyTorch 开始。此外,我们还需要结合硬件场景,即前面说到的 ARM 服务端平台,对于阿里云来说就是结合倚天 710 芯片。
深度学习的实现中包含大量的矩阵乘法,甚至有文章直接写出矩阵乘法是深度学习的核心。举个例子,我们熟知的卷积操作,实际上经过一系列的转换后,输入特征和卷积核会被转换为两个矩阵,然后进行矩阵乘法,输出的结果再解码成特征图,就完成了卷积。除此以外,全连接层也由矩阵乘法实现,当前流行的 Transformers 结构,被包括 ChatGPT 在内的各类 NLP 模型所使用,也包含大量矩阵乘法操作。
我们可以看一些例子:
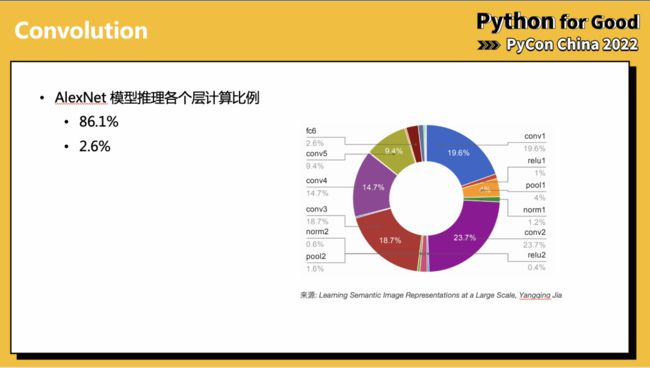

可以看到,像 AlexNet、ResNet-50 之类的模型,在进行推理时,大约 90% 计算耗时在执行矩阵乘法。即使对矩阵乘法做一些微小的优化,影响也是很广泛的。

我们前面说的矩阵乘法,更准确的叫法是 GEMM,通用矩阵乘法,其实还包含系数和累加操作。但是时间复杂度仍然是 MNK 级别,主要还在于 AB 两个矩阵相乘。直观来看,深度学习涉及的矩阵乘法计算量很大,比如常见的卷积操作可能就涉及 5000 万次计算,所以优化就显得很有必要,右下图是最朴素的三层循环迭代法,这种做法通常非常慢,计算机科学家做了许多努力,从优化内存布局和利用向量指令出发,能够将性能提升 10 倍以上。

内存布局主要分两步,第一步是对矩阵进行分块,即对于一个超大的矩阵,我们并不是一个一个按顺序计算,而是将矩阵切分为一个一个小块,分小块计算。第二步是对分出的小块,内部的元素序列进行重排,例如原来是按行排列的矩阵,那可能第一行四个计算好了,就需要取第二行的前四个,但是要取第二行就需要指针移动很长的距离,很容易造成 cache 不命中,于是需要重排,使得他们在内存上连续。优化内存布局主要目的是为了增加 cache 命中率,减少访存次数。
其次是利用向量化指令,类似 AVX 对于 x86 设备,NEON 对于 ARM 设备。向量化指令本质上是为了同时对多个数据进行计算,例如我们要对四组数据分别进行乘法,那么常规情况下需要执行四次,如果将它们对应放入向量寄存器中,只需要一条向量化指令,就可以同时得出四个结果,计算效率得到提升。当然这个是需要硬件支持。
因为AI推理大量使用了矩阵乘法,如今也有许多硬件对矩阵运算进行了加速:
-
NVIDIA Volta 架构引入了tensor core,可以高效地以混合精度处理矩阵乘
-
Intel AMX(Advanced Matrix Extensions) 通过脉动阵列在硬件层面支持矩阵乘
-
ARM SME(Scalable Matrix Extension) 支持向量外积运算,加速矩阵乘
目前市面上尚没有可以大规模使用的支持 AMX 或者 SME 的硬件,在这个阶段我们应该如何优化 CPU 上的 AI 推理算力呢?我们首先要了解 BF16 数据类型。
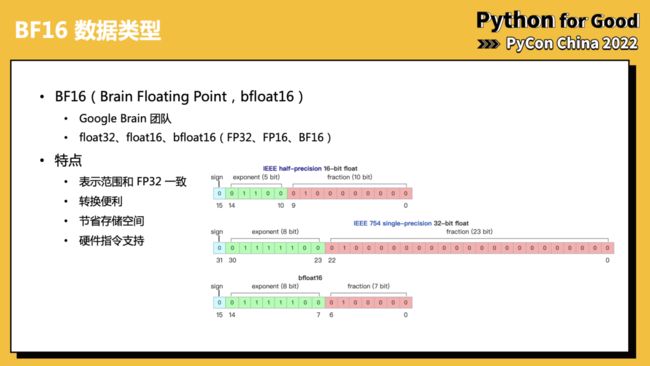
BF16(全称 Brain Floating Point),是由 Google Brain 开发设计的 16 位浮点数格式。
相比传统的 FP16 位浮点数,BF16 拥有和 FP32 一样的取值范围,但是精度较差。但对于深度学习来说,较低的精度并不显著影响结果,而较低的表示范围则会显著影响模型训练的好坏。
此外,BF16 还具有转换方便的特点,BF16 和 FP32 的互转只需要截断或填充尾数即可。
使用 BF16 还可以节约一半的内存,紧凑的内存表示通常意味着更高的计算吞吐。
最后,我们也有了硬件指令支持,可以直接对 BF16 数据进行操作。
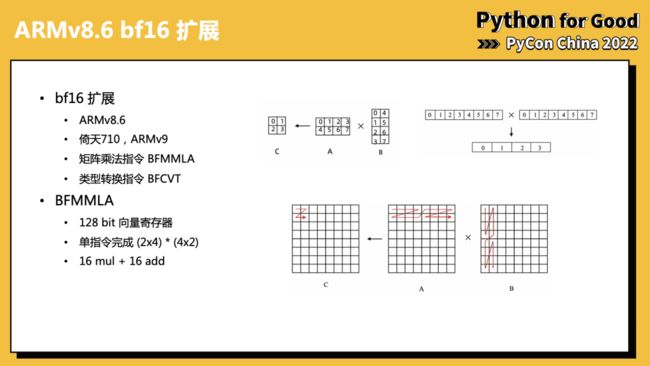
需要说明的是 BF16 的扩展包含在 ARMv8.6 设备上,当然倚天 710 是 ARMv9 的指令集,同样支持。
我们主要通过 BFMMLA 来进行矩阵乘法计算,例如对于包含 128bit 的向量寄存器的设备来说:
-
输入 A: 大小为 2*4 的 BF16 矩阵,按行存储
-
输入 B: 大小为 4*2 的 BF16 矩阵,按列存储
-
输出 C: 大小为 2*2 的 FP32 矩阵
BFMMLA 单指令完成 16 次乘法和 16 次加法,计算吞吐非常高。
当然这时候如果我们需要 C 是 BF16 类型的话,就需要应用转换指令,例如向量化指令 BFCVT,加速转换过程。
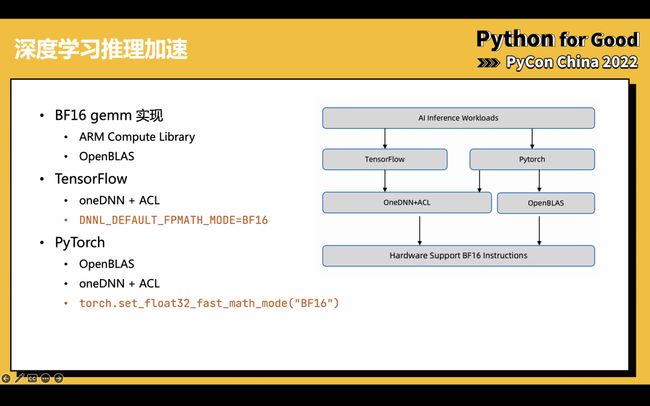
我们的目标还是给 tensorflow 和 pytorch 用户提供加速,这是整体的流程图,对于一个 AI 推理任务,实际上不论是 TensorFlow 还是 PyTorch 都不会自己直接去计算,而是叫个专门的计算后端,在 ARM 主要是两个,一个是 ARM Compute Library,另一个是 OpenBLAS,他们之间的关系如右图。
TensorFlow 在最近的版本中开始采用 oneDNN + ACL 作为计算后端,oneDNN 也是一层皮,实际的计算仍然是 ACL。用户实际上只需要设置一个环境变量,就可以在不该动代码的情况下获得 BF16 加速。这个改进是由 ARM 公司的研发人员首先完成了。具体操作例子如下:
# 假设 resnet.py 包含用户写的模型推理的代码
DNNL_DEFAULT_FPMATH_MODE=BF16 python3 resnet.pyPyTorch的情况比较复杂,PyTorch 支持 OneDNN + ACL,但无法很好的发挥性能,同时 PyTorch 支持 OpenBLAS 后端,因此可以通过 OpenBLAS 来享受 ARM bf16 扩展带来的性能收益。
OpenBLAS 的 BF16 的 GEMM 优化是由龙蜥社区理事单位阿里巴巴贡献的,于此同时,我们为了方便用户使用,也在 PyTorch 中加入了一个API,用户在模型执行前添加一行torch.set_float32_fast_math_mode("BF16"),就可以获得 BF16 加速,不必修改其他代码(需要说明,这个api还没有合入PyTorch,所以目前要使用我们提供的pytorch镜像才可以获得)。操作例子如下:
# ...
# 在模型执行前设置fast math mode
torch.set_float32_fast_math_mode("BF16")
# ...
# 执行模型
pred = model(x)
# ...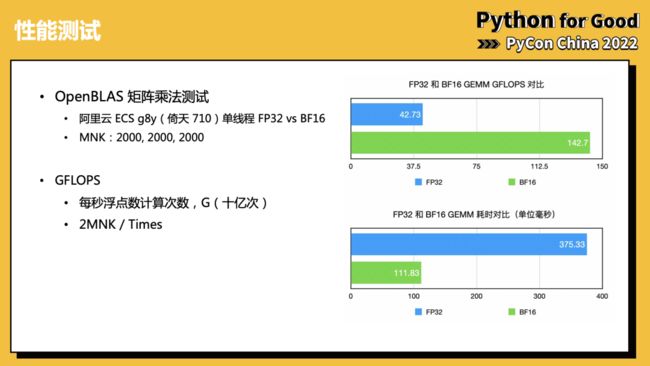

之后是一些性能测试的展示,我们测试了 OpenBLAS 纯矩阵计算的性能对比。分别记录了 GFLOPS 和执行时间两个指标。
然后测试 TensorFlow 和 PyTorch 的性能对比,在对比中,我们可以看到,得益于 BF16 扩展,最新的 ECS ARM 平台上的性能优于 x86 平台(g7)。

二、Python AI应用在ARM云平台-倚天710上的最佳实践
现在介绍一下在 ARM 平台,特别是倚天 710 的用户,使用 TensorFlow 或 PyTorch 的最佳实践。
要知道软件版本的选择十分重要,随意选择 tensorflow 或者 pytorch 包可能遭遇:
-
未适配 ARM 架构,安装失败
-
软件未适配 BF16 扩展或者环境参数有误,无法发挥硬件的全部算力,性能打折
-
需要精心选择计算后端,例如目前 pytorch下OpenBLAS 较快
在 TensorFlow 上,我们可以选择最新的两个官方版本, 2.10.1 或者 2.11.0(最新版本),才能够获得 ACL 的 BF16 加速。用户也可以选择阿里云的镜像,这个和 pip 安装的其实是一样的,没有区别。
对于 PyTorch 用户,官方版本只有在最新的 1.13.0 才能够获得 ACL 加速,但是正如前面所说的,实际性能并不突出。阿里云则提供了带最新 OpenBLAS 的 PyTorch,在 docker 拉取时标注 torch_openblas 就可以获得。此外,我们也提供了modelzoo 镜像,包含模型的测试代码和验证代码。
目前我们仍然在进行相关的工作,期待后续能为大家提供更加完善的镜像。欢迎大家入群一起探索相关技术。
AI SIG主页地址:
https://openanolis.cn/sig/AI_SIG
—— 完 ——