机器学习预测股票收益(三)之比较随机森林、支持向量机回归模型以及神经网络多层感知器模型
文章目录
- 前言
- 一、随机森林模型
- 二、SVR模型
- 三、MLPRegressor模型
- 总结
前言
本文将使用Python整理1927-2020年所有美国上市公司股票数据。根据历史收益以及交易量,使用随机森林,支持向量机以及神经网络等机器学习方法预测股票收益,并比较模型结果。数据处理以及函数见“机器学习预测股票收益(一)”
一、随机森林模型
result_rfr = pd.DataFrame()
rfr = RandomForestRegressor(random_state = 44,max_depth = 70,max_features = 'sqrt',min_samples_leaf = 4,min_samples_split=2,n_estimators=200)
model1 = rfr.fit(X_train, y_train)
y_pre_rfr = rfr.predict(X_test)
y_pre_rfr = pd.Series(y_pre_rfr,name = "pre",index = y_test.index)
pre_data_rfr = pd.concat([permno_test,y_test, y_pre_rfr], axis=1)
result_rfr = result_rfr.append(pre_data_rfr)
mse_rfr = metrics.mean_squared_error(y_test, y_pre_rfr)
print("MSE_rfr: %.4f" % mse_rfr)
mae_rfr = metrics.mean_absolute_error(y_test, y_pre_rfr)
print("MAE_rfr: %.4f" % mae_rfr)
R2_rfr = metrics.r2_score(y_test,y_pre_rfr)
print("R2_rfr: %.4f" % R2_rfr)

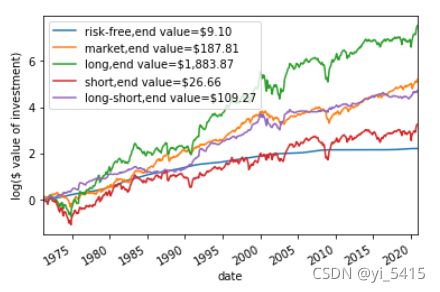
lgvalue_rfr.plot()
plt.ylabel("log($ value of investment)")
plt.legend(["risk-free,end value=$9.10", "market,end value=$187.81",
"long,end value=$1,883.87", "short,end value=$26.66", "long-short,end value=$109.27"])
pf_xret_rfr = pf_rfr - pfactors.loc[:,"RF"]
pf_xret_rfr = pf_xret_rfr.rename("pf excess return_rfr")
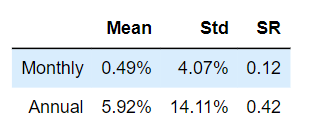
analyze_performance(pf_xret_rfr)
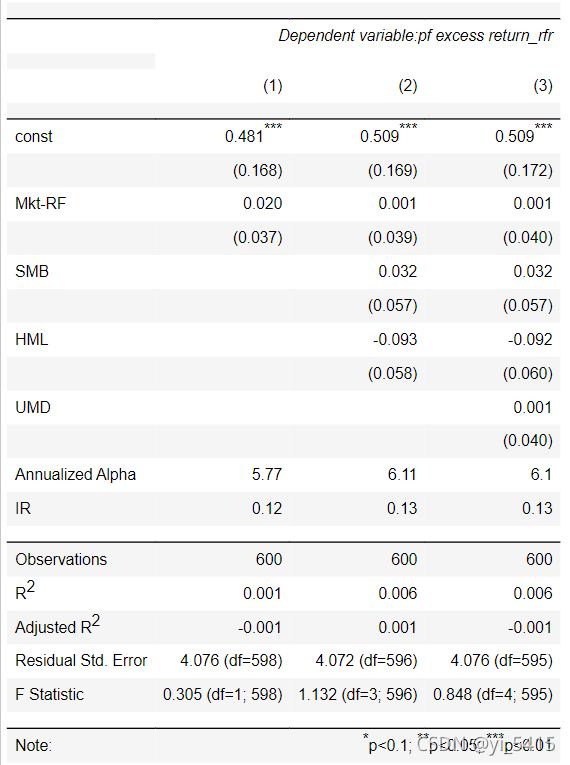
regression_results(pf_xret_rfr,pfactors)
二、SVR模型
result_svr= pd.DataFrame()
f_importance_svr = pd.DataFrame()
perform_svr = pd.DataFrame()
svr = SVR( kernel='linear',C=1.0)
model2 = svr.fit(X_train, y_train)
y_pre_svr = svr.predict(X_test)
y_pre_svr = pd.Series(y_pre_svr,name = "pre",index = y_test.index)
pre_data_svr = pd.concat([permno_test,y_test, y_pre_svr], axis=1)
result_svr = result_svr.append(pre_data_svr)
mse_svr = metrics.mean_squared_error(y_test, y_pre_svr)
print("MSE_svr: %.4f" % mse_svr)
mae_svr = metrics.mean_absolute_error(y_test, y_pre_svr)
print("MAE_svr: %.4f" % mae_svr)
R2_svr = metrics.r2_score(y_test,y_pre_svr)
print("R2_svr: %.4f" % R2_svr)

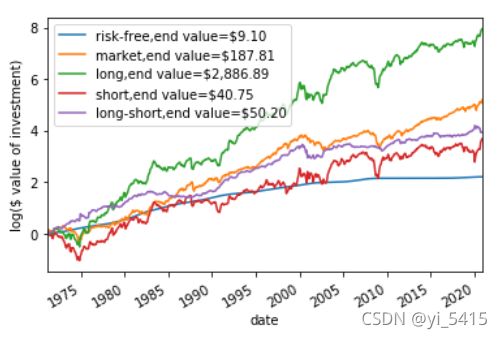
lgvalue_svr.plot()
plt.ylabel("log($ value of investment)")
plt.legend(["risk-free,end value=$9.10", "market,end value=$187.81",
"long,end value=$2,886.89", "short,end value=$40.75", "long-short,end value=$50.20"])
pf_xret_svr = pf_svr - pfactors.loc[:,"RF"]
pf_xret_svr = pf_xret_svr.rename("pf excess return_svr")
analyze_performance(pf_xret_svr)

regression_results(pf_xret_svr,pfactors)
三、MLPRegressor模型
result_mlp= pd.DataFrame()
perform_mlp = pd.DataFrame()
mlp = MLPRegressor(hidden_layer_sizes = (256,128),activation = "relu",solver='adam')
model3 = mlp.fit(X_train, y_train)
y_pre_mlp = mlp.predict(X_test)
y_pre_mlp = pd.Series(y_pre_mlp,name = "pre",index = y_test.index)
pre_data_mlp = pd.concat([permno_test,y_test, y_pre_mlp], axis=1)
result_mlp = result_mlp.append(pre_data_mlp)
mse_mlp = metrics.mean_squared_error(y_test, y_pre_mlp)
print("MSE_mlp: %.4f" % mse_mlp)
mae_mlp = metrics.mean_absolute_error(y_test, y_pre_mlp)
print("MAE_mlp: %.4f" % mae_mlp)
R2_mlp = metrics.r2_score(y_test,y_pre_mlp)
print("R2_mlp: %.4f" % R2_mlp)

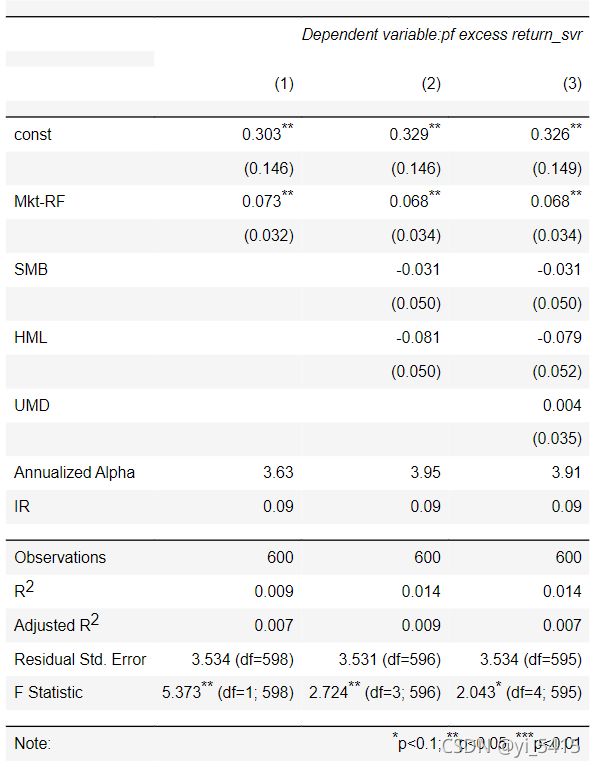
lgvalue_mlp.plot()
plt.ylabel("log($ value of investment)")
plt.legend(["risk-free,end value=$9.10", "market,end value=$187.81",
"long,end value=$1,687.88", "short,end value=$23.34", "long-short,end value=$89.75"])
pf_xret_mlp = pf_mlp - pfactors.loc[:,"RF"]
pf_xret_mlp = pf_xret_mlp.rename("pf excess return_mlp")
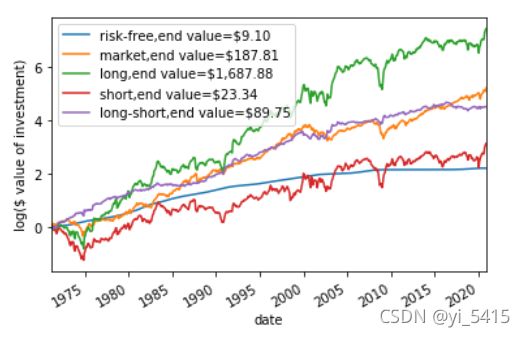
analyze_performance(pf_xret_mlp)
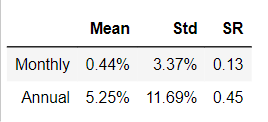
regression_results(pf_xret_mlp,pfactors)

总结


比较 3 个模型的结果,发现基于随机森林回归的策略的平均回报最高,而 SVR 的平均回报最低。 随机森林回归的结果是 3 个模型中最不稳定的。 MLP 回归器在 3 个模型中的sharp ratio 最高。 但是,本文只对随机森林回归模型的调节了最佳参数,MLP回归和SVR模型的参数参考了其他文献,如果找到了它们的最佳参数,这两个模型可能会表现得更好。