RabbitMq的Ubuntu安装以及Python实现
RabbitMq
- 一、RabbitMq简介
- 二、Ubuntu安装
-
- 2.1 安装支持库以及RabbitMq本体
- 2.2 RabbitMq的基础指令
- 三、Python实现
-
- 3.1 模式一:fanout(群体发送)
- 3.2 模式二:direct(routing_key 定向发送)
- 3.3 模式三:topicd(routing_key 正则匹配)
- 四、基于RabbitMq改写的YOLO_detect信息传输功能
- 五、报错及解决方案
-
- 4.1 TypeError: Object of type 'type' is not JSON serializable
一、RabbitMq简介
RabbitMq 是实现了高级消息队列协议(AMQP)的开源消息代理中间件。消息队列是一种应用程序对应用程序的通行方式,应用程序通过写消息,将消息传递于队列,由另一应用程序读取 完成通信。而作为中间件的 RabbitMq 无疑是目前最流行的消息队列之一。
RabbitMq 应用场景广泛:
- 系统的高可用:日常生活当中各种商城秒杀,高流量,高并发的场景。当服务器接收到如此大量请求处理业务时,有宕机的风险。某些业务可能极其复杂,但这部分不是高时效性,不需要立即反馈给用户,我们可以将这部分处理请求抛给队列,让程序后置去处理,减轻服务器在高并发场景下的压力。
- 分布式系统,集成系统,子系统之间的对接,以及架构设计中常常需要考虑消息队列的应用。
消息队列介绍及主流的解决方案:https://blog.csdn.net/fst438060684/article/details/86555114#t25
二、Ubuntu安装
2.1 安装支持库以及RabbitMq本体
查看ubuntu当前版本命令(笔者这里是 Ubuntu 20.04 LTS):
cat /etc/issue
rabbitMq需要erlang语言的支持,在安装rabbitMq之前需要安装erlang,执行命令:
sudo apt-get install erlang-nox
安装rabbitMq命令:
# 更新apt
sudo apt-get update
# 安装server
sudo apt-get install rabbitmq-server
# 启动management(也就是监视网页)
sudo rabbitmq-plugins enable rabbitmq_management
2.2 RabbitMq的基础指令
# 安装完成后在rabbitMQ中添加用户
sudo rabbitmqctl add_user username password
# 将用户设置为管理员(只有管理员才能远程登录)
sudo rabbitmqctl set_user_tags username administrator
# 同时为用户设置读写等权限
sudo rabbitmqctl set_permissions -p / username ".*" ".*" ".*"
启动、关闭、重启:
# 启动:
sudo rabbitmq-server start
# 关闭:
sudo rabbitmq-server stop
# 重启:
sudo rabbitmq-server restart
在关闭的过程中也许会出现错误:
node with name "rabbit" already running on "mybox"
解决方案:
sudo rabbitmqctl status
sudo rabbitmqctl stop
# 再次查看status确认已经关闭服务
sudo rabbitmqctl status
要再次启动,建议的方法是:
sudo invoke-rc.d rabbitmq-server start
三、Python实现
rabbitmq 的发布与订阅要借助交换机(Exchange)的原理实现:
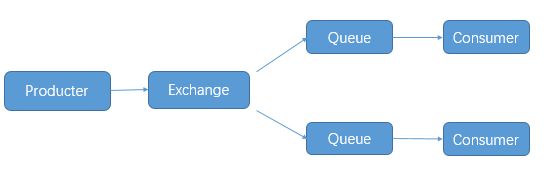
Exchange一共有三种工作模式:fanout, direct, topicd
3.1 模式一:fanout(群体发送)
这种模式下,传递到 exchange 的消息将会转发到所有与其绑定的queue上。
- 不需要指定 routing_key ,即使指定了也是无效。
- 需要提前将 exchange 和 queue绑定,一个exchange可以绑定多个queue,一个queue可以绑定多个exchange。
- 需要先启动订阅者,此模式下的队列是 consumer 随机生成的,发布者仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。
Publish:
import pika
import json
credentials = pika.PlainCredentials('shampoo', '123456') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel=connection.channel()
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout')for i in range(10):
message=json.dumps({'OrderId':"1000%s"%i})
# 向队列插入数值 routing_key是队列名。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化。routing_key 不需要配置
channel.basic_publish(exchange = 'python-test',routing_key = '',body = message,
properties=pika.BasicProperties(delivery_mode = 2))
print(message)
connection.close()
Consume:
import pika
credentials = pika.PlainCredentials('shampoo', '123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel = connection.channel()
# 创建临时队列,队列名传空字符,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout')
# 绑定exchange和队列 exchange 使我们能够确切地指定消息应该到哪个队列去
channel.queue_bind(exchange = 'python-test',queue = result.method.queue)
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag = method.delivery_tag)
print(body.decode())
channel.basic_consume(result.method.queue,callback,# 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉
auto_ack = False)
channel.start_consuming()
3.2 模式二:direct(routing_key 定向发送)
这种工作模式的原理是 消息发送至 exchange,exchange 根据路由键(routing_key)转发到相对应的 queue 上。
- 可以使用默认 exchange =’ ’ ,也可以自定义 exchange
- 这种模式下不需要将 exchange 和 任何进行绑定,当然绑定也是可以的。可以将 exchange 和 queue ,routing_key 和 queue 进行绑定
- 传递或接受消息时 需要 指定 routing_key需要先启动 订阅者,此模式下的队列是 consumer 随机生成的,发布者 仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。
Publish:
import pika
import json
credentials = pika.PlainCredentials('shampoo', '123456') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel=connection.channel()
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='direct')
for i in range(10):
message=json.dumps({'OrderId':"1000%s"%i})
# 指定 routing_key。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化
channel.basic_publish(exchange = 'python-test',routing_key = 'OrderId',body = message,
properties=pika.BasicProperties(delivery_mode = 2))
print(message)
connection.close()
Consume:
import pika
credentials = pika.PlainCredentials('shampoo', '123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel = connection.channel()
# 创建临时队列,队列名传空字符,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='direct')
# 绑定exchange和队列 exchange 使我们能够确切地指定消息应该到哪个队列去
channel.queue_bind(exchange = 'python-test',queue = result.method.queue,routing_key='OrderId')
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag = method.delivery_tag)
print(body.decode())
#channel.basic_qos(prefetch_count=1)
# 告诉rabbitmq,用callback来接受消息
channel.basic_consume(result.method.queue,callback,
# 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉
auto_ack = False)
channel.start_consuming()
3.3 模式三:topicd(routing_key 正则匹配)
这种模式和第二种模式差不多,exchange 也是通过 路由键 routing_key 来转发消息到指定的 queue 。 不同点是 routing_key 使用正则表达式支持模糊匹配,但匹配规则又与常规的正则表达式不同,比如“#”是匹配全部,“*”是匹配一个词。
举例: routing_key =“#orderid#”,意思是将消息转发至所有 routing_key 包含 “orderid” 字符的队列中。代码和 模式二 direct 类似,就不贴出来了。
四、基于RabbitMq改写的YOLO_detect信息传输功能
yolo_detect_publish端
import argparse
import time
from pathlib import Path
import cv2
import torch
import torch.backends.cudnn as cudnn
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, non_max_suppression, apply_classifier, \
scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path, save_one_box
from utils.plots import colors, plot_one_box
from utils.torch_utils import select_device, load_classifier, time_synchronized
from MyEncoder import MyEncoder
import pika
import json
@torch.no_grad()
def detect(weights='yolov5s.pt', # model.pt path(s)
source='data/images', # file/dir/URL/glob, 0 for webcam
imgsz=640, # inference size (pixels)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
update=False, # update all models
project='runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
):
save_img = not nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
# Load model
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
imgsz = check_img_size(imgsz, s=stride) # check image size
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
# Second-stage classifier
classify = False
if classify:
modelc = load_classifier(name='resnet50', n=2) # initialize
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval()
# Set Dataloader
vid_path, vid_writer = None, None
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
# Run inference
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# Inference
t1 = time_synchronized()
pred = model(img, augment=augment)[0]
# Apply NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
t2 = time_synchronized()
# Apply Classifier
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process detections
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
im0 = plot_one_box(xyxy, im0, label=label, color=colors(c, True), line_thickness=line_thickness)
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
credentials = pika.PlainCredentials('AI_Detect', 'qwert')
connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'localhost',port = 5672,virtual_host = '/',credentials = credentials))
channel=connection.channel()
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout')
message=json.dumps(f'{s}Done. ({t2 - t1:.3f}s)',cls=MyEncoder,indent=4)
channel.basic_publish(exchange = 'python-test',routing_key = '',body = message,
properties=pika.BasicProperties(delivery_mode = 2))
print(message)
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path != save_path: # new video
vid_path = save_path
if isinstance(vid_writer, cv2.VideoWriter):
vid_writer.release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer.write(im0)
connection.close()
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
print(f'Done. ({time.time() - t0:.3f}s)')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
opt = parser.parse_args()
print(opt)
check_requirements(exclude=('tensorboard', 'thop'))
detect(**vars(opt))
yolo_detect_consume端
import pika
credentials = pika.PlainCredentials('AI_Detect', 'qwert') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host = 'localhost',port = 5672,virtual_host = '/',credentials = credentials))
channel=connection.channel()
# 创建临时队列,队列名传空字符,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout')
# 绑定exchange和队列 exchange 使我们能够确切地指定消息应该到哪个队列去
channel.queue_bind(exchange = 'python-test',queue = result.method.queue)
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag = method.delivery_tag)
print(body.decode())
channel.basic_consume(result.method.queue,callback,# 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉
auto_ack = False)
channel.start_consuming()
五、报错及解决方案
4.1 TypeError: Object of type ‘type’ is not JSON serializable
解决:编写一个解码类 遇到byte就转为str
编写一个MyEncoder.py文件,放在目标根目录下
import json
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, bytes):
return str(obj, encoding='utf-8')
return json.JSONEncoder.default(self, obj)
使用方法:
from MyEncoder import MyEncoder
json.dumps(data,cls=MyEncoder,indent=4) # 原方法json.dumps(data)改写