【实战篇】基于Pytorch的3D立体图像分类--基础篇
在一般的图像数据的采集场景中,得到的多是二维图像,所以大多数深度学习网络的雏形都是基于二维图像展开的工作。
但是,在某些场景下,比如医学影像CT数据,监控场景连续拍摄的视频和自动驾驶使用到的激光点云等等,多是连续的、多层的数据。
此时,层内的信息,和层与层之间的层间深度信息,也是一个重要的特征信息。所以,实现三维的目标分类任务,也是必不可少的。想想很复杂,但是动手实操了,才能理解其中的内容。
本文就对三维图像分类任务展开介绍,主要是自己的实战记录过程。包括:
- 3维网络构建部分
- 3维数据构建部分
- 训练和测试
- 对基础部分进行修改,提高性能
下面一点点的进行详述。
一、构建3维网络
三维网络我们不熟悉,就先从构建二维网络开始,然后推到三维网络里面去。这样能帮助我们更快的理解。下面就以LeNet为例,展开实验
1.1、先构建2维LeNet
在学习神经网络的时候,LeNet是一个比较早期的网络,并且结构也是比较的简单,很方便我们理解的。这里我就以LeNet为例,构建一个卷积是3*3、stride=2的改版LeNet2D模型,如下所示:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
from torchsummary import summary
class LeNet2D(nn.Module):
def __init__(self, num_classes=2, input_channel=3, init_weights=False):
super(LeNet2D, self).__init__()
self.conv1 = nn.Conv2d(input_channel, 16, kernel_size=3, stride=2, padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
if init_weights:
self._initialize_weights()
def forward(self, x): # 1, 64, 64
x = F.relu(self.conv1(x)) # output 16, 32, 32
x = self.pool1(x) # output 16, 16, 16
x = F.relu(self.conv2(x)) # output 32, 8, 8
x = self.pool2(x) # output 32, 4, 4
x = x.view(x.size(0), -1) # outpu 32*4*4, 1
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
def main_2d():
model = LeNet2D(num_classes=2, input_channel=1, init_weights=True)
model = nn.DataParallel(model, device_ids=None)
print(model)
summary(model, input_size=(1, 64, 64), batch_size=-1, device='cpu')
input_var = Variable(torch.randn(16, 1, 64, 64)) # b,c,h,w
output = model(input_var)
print(output.shape)
上述构建模型部分是比较简单的,相信你已经看明白了。对模型进行测试,看看是否满足我们的预期。其中:
- 类别是2
- 灰度图像
1*64*64(b,c,h,w) - batch=16
summary打印的模型如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 32, 32] 160
MaxPool2d-2 [-1, 16, 16, 16] 0
Conv2d-3 [-1, 32, 8, 8] 4,640
MaxPool2d-4 [-1, 32, 4, 4] 0
Linear-5 [-1, 120] 61,560
Linear-6 [-1, 84] 10,164
Linear-7 [-1, 2] 170
LeNet2D-8 [-1, 2] 0
================================================================
Total params: 76,694
Trainable params: 76,694
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.02
Forward/backward pass size (MB): 0.18
Params size (MB): 0.29
Estimated Total Size (MB): 0.49
----------------------------------------------------------------
测试输入数组为(16, 1, 64, 64)时,输出的大小是torch.Size([16, 2]),16是批次大小,2是预设的输出类别,符合我们的预测。
1.2、构建3维LeNet
在已经构造好的LeNet2D模型的基础上,改造成我们需要的LeNet3D模型,直接替换两处:
- nn.Conv2d --> nn.Conv3d
- nn.MaxPool2d --> nn.MaxPool3d
也就是将卷积核和池化核的尺寸都变动以下,增加一个深度信息。构建的模型如下:
class LeNet3D(nn.Module):
def __init__(self, num_classes=2):
super(LeNet3D, self).__init__()
self.conv1 = nn.Conv3d(1, 16, kernel_size=3, stride=2, padding=1)
self.pool1 = nn.MaxPool3d(2, 2)
self.conv2 = nn.Conv3d(16, 32, kernel_size=3, stride=2, padding=1)
self.pool2 = nn.MaxPool3d(2, 2)
self.fc1 = nn.Linear(32*2*4*4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
def forward(self, x): # c,z, h, w c, z, h, w
x = F.relu(self.conv1(x)) # input(1,32,64,64) -- kernel_size=3, stride=2 -- (16,16,32,32)
x = self.pool1(x) # output (16,8,16,16)
x = F.relu(self.conv2(x)) # output (32, 4, 8, 8)
x = self.pool2(x) # output (32, 2, 4, 4)
x = x.view(x.size(0), -1) # output (32*2*4*4, 1)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
def main_3d():
model = LeNet3D(num_classes = 2)
model = nn.DataParallel(model, device_ids=None)
print(model)
summary(model, input_size=(1, 32, 64, 64), batch_size=-1, device='cpu')
#
input_var = Variable(torch.randn(16, 1, 32, 64, 64)) # b,c,z,h,w
output = model(input_var)
print(output.shape)
依旧对模型进行测试,看看是否满足我们的预期(养成一步一测试的习惯)。其中:
- 类别是2
- 灰度图像
1*32*64*64(b,c,z,h,w) - batch=16
3维输入数据,与2维输入数据,多了一个Z周的维度信息。所以,再后面构建数据时候,也要跟此处测试的数据格式一致。
打印的模型如下:
DataParallel(
(module): LeNet3D(
(conv1): Conv3d(1, 16, kernel_size=(3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1))
(pool1): MaxPool3d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv3d(16, 32, kernel_size=(3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1))
(pool2): MaxPool3d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc1): Linear(in_features=1024, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=2, bias=True)
)
)
PS;这里加了并行化,可以把并行化的代码去除掉,进行打印,更加简洁。
summary打印的模型如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv3d-1 [-1, 16, 16, 32, 32] 448
MaxPool3d-2 [-1, 16, 8, 16, 16] 0
Conv3d-3 [-1, 32, 4, 8, 8] 13,856
MaxPool3d-4 [-1, 32, 2, 4, 4] 0
Linear-5 [-1, 120] 123,000
Linear-6 [-1, 84] 10,164
Linear-7 [-1, 2] 170
LeNet3D-8 [-1, 2] 0
================================================================
Total params: 147,638
Trainable params: 147,638
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.50
Forward/backward pass size (MB): 2.32
Params size (MB): 0.56
Estimated Total Size (MB): 3.39
----------------------------------------------------------------
测试输入数组为(16, 1, 32, 64, 64)时,输出的大小是torch.Size([16, 2]),符合我们的预测。
注意一点:网络模型对于的图像大小的输入是有要求的,上述代码中构建的模型,智适用于输入大小为(1, 32, 64, 64)的,这是因为在全连接时候,需要将前一层卷积后的输出进行拉直操作。
此时,这个拉直后的大小,是和输入图像的大小,有直接关系的。上面我对全连接部分对尺寸怎么计算得到的,进行了备注,你也可以修改为自己希望输入的尺寸,只要对应修改全连接输入的部分,即可。
如果,你需要对模型进行参数初始化,可以添加模型初始化部分,如下所示:
class LeNet3D(nn.Module):
def __init__(self, num_classes=2, init_weights=False):
super(LeNet3D, self).__init__()
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv3d):
n = m.kernel_size[0] * m.kernel_size[1] * m.kernel_size[2] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm3d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
模型初始化方式挺多的,全0初始化、随机初始化、高斯分布初始化、预训练模型初始化等等。如果没有主动定义初始化
更多summary的信息,可以参考这里:torch.summary打印出神经网络的形状和参数大小
1.3、小结
LeNet模型从2维到3维的构建过程,是比较简单的,通过尝试输入数据进行测试网络数据流,也是满足预期的。
其中,改变输入图像的宽高大小,对于卷积和池化的输入大小,是不需要做适应的。而全连接的输入,需要预先固定。所以,代码部分给出了数据流大小的计算过程,方便改写。
当然,这里只是简单学习了LeNet模型从2维变3维,且进行测试的过程。网络上前辈已经将目前常用的网络模型,基本都改好了3维版本的,所以,如果需要了,可以直接使用。
这里提供一个GitHub,包括了'c3d', 'squeezenet', 'mobilenet', 'resnext', 'resnet', 'shufflenet', 'mobilenetv2', 'shufflenetv2'的3维模型。链接:Efficient-3DCNNs
二、数据部分
由前面设计网络部分的模拟输入数据的结构,我们可以知道,接下来创建数据时候,也需要是1, 32, 64, 64的数据形式,表示32个1*64*64的图像,堆叠到了一起的一个数组。
2.1、GetLoader基础版本
这本篇的数据预处理中,我遵循如下的步骤:
- 首先,将需要的分类的目标,保存成
[32, 1, 64, 64]的.nii数组文件 - 其次,
itk.imread读取进来的,就是一个三维的结构数组 - 再进行归一化
- 分类标签采用从文件名传进来的形式,转化为
one-hot形式
你也可以将保存nii数组文件这块内容,放到GetLoader出进行处理,也是可以的,就是代码不那么的简洁。
至此,一个简单的三维模型数据块准备完毕,代码如下:
import torch
from torch.utils.data import Dataset
from torch.utils import data as torch_data
import itk
import os
class GetLoader(Dataset):
def __init__(self, data_root):
super().__init__()
self.data_root = data_root
self.list_path_data = os.listdir(data_root)
def __getitem__(self, index):
name_i = self.list_path_data[index]
# print(name_i)
data = itk.array_from_image(itk.imread(os.path.join(self.data_root, name_i)))
# print(data.shape)
data = (data - data.min()) / (data.max() - data.min())
label_cls_str = name_i.split('_')[-1].split('.nii')[0]
labels = [1, 0] if label_cls_str == 'malignant' else [0, 1]
return torch.tensor(data[None, :]).float(), torch.tensor(labels).float()
def __len__(self):
return len(self.list_path_data)
if __name__=='__main__':
data_root = r"./database/val"
dataNII = GetLoader(data_root)
print(len(dataNII))
valid_loader = torch_data.DataLoader(dataNII, batch_size=2, shuffle=False, num_workers=4,
pin_memory=False)
print(len(valid_loader))
for i in range(len(dataNII)):
image2d, label2d = dataNII[i]
print('image size ......')
print(image2d.shape) # torch.Size([1, 32, 1, 64, 64])
print('label size ......')
print(label2d.shape) # torch.Size([2])
这么是一个比较简单的版本。有基础版本,那就会有升级版本。后面我们还可以改变输入数据形式,比如图像数据是3通道的,增加数据增强方式等等。这部分内容,我们放到增强篇进行详述。
2.2、GetLoader数据可视化
这里,我们现有基础版本上,查看下数据构建出来的样子,代码如下:
import matplotlib.pyplot as plt
if __name__=='__main__':
data_root = r"./data-channel_1/lidc/test"
dataNII = GetLoader(data_root)
print(len(dataNII))
valid_loader = torch_data.DataLoader(dataNII, batch_size=2, shuffle=False, num_workers=4,
pin_memory=False)
print(len(valid_loader))
for i in range(len(dataNII)):
image2d, label2d = dataNII[i]
print('image size ......')
print(image2d.shape) # (1, 32, 64, 64)
print('label size ......')
print(label2d.shape) # (2)
for j in range(image2d.shape[1]):
oneImg = image2d[0, j, :, :]
print(oneImg.shape)
plt.subplot(4, 8, j + 1)
plt.title(j)
plt.imshow(oneImg, cmap='gray')
plt.axis('off')
plt.show()
显示的图片序列信息如下,一个3维的图像是32张,每一张又是64*64的大小,铺开显示,就是下面这样:
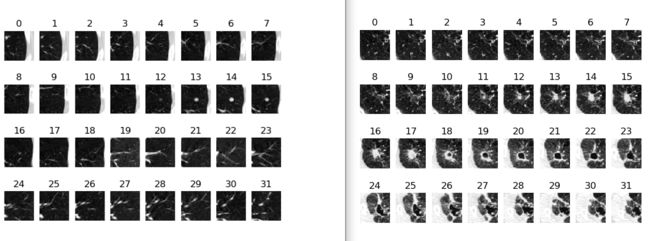
显示部分参考链接:pytorch 带batch的tensor类型图像怎么显示?
三、训练与评估
pytorch中,最为简答和最流程化的部分,就数训练了。主要遵循以下一个结构:
- 获取数据
- 获取模型
- 定义优化器
- 定义损失函数
- 循环epoch
- 循环一个epoch的多个batch
- 阶段性评估
- 保存模型
- 输出训练文档
上述精简版代码结构如下,之后我们在这个结构里面,进行填空就行:
def validation(valid_loader, path_ckpt):
return loss_avg, acc_sum
def train():
MAX_EPOCH = 70
ITR_PER_CKPT_VAL = 1
# 获取数据
train_data_retriever = GetLoader(data_train)
valid_data_retriever = GetLoader(data_val)
train_loader = torch_data.DataLoader()
valid_loader = torch_data.DataLoader()
# 获取模型
model = LeNet()
model.train()
model.to(device)
# 定义优化器
optimizer = torch.optim.SGD()
# 循环epoch
for i_epoch in range(1, MAX_EPOCH + 1):
loss_sum = 0
N = 0
# 循环一个epoch的batch
for step, (data, label) in enumerate(train_loader):
img = data.to(device)
targets = label.to(device)
outputs = model(img).squeeze(1)
# 定义损失函数
loss = F.cross_entropy(outputs, torch.max(targets, 1)[1]).to(device)
loss_sum += loss.detach().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_avg = loss_sum / len(train_loader)
print("[Epoch " + str(i_epoch) + " | " + "train loss = " + ("%.7f" % loss_avg) + "]")
# 保存模型
path_ckpt = r"./checkpoints/" + str(i_epoch) + ".pth.tar"
torch.save({"epoch": i_epoch, "model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict()}, path_ckpt)
# 阶段性评估
loss_val, acc_sum = validation(valid_loader, path_ckpt)
accuracy = acc_sum * 100 / len(valid_data_retriever)
print("[Epoch " + str(i_epoch) + " | " + "val loss = " + ("%.7f" % loss_val) + " accuracy = " + ("%.3f" % accuracy) + "%]")
if __name__=='__main__':
train()
如果你以前也做过pytorch的分类任务,那么你可以直接拿出来,在上面改就可以了。本文使用到的定义如下列表:
- 数据的获取第一章节已经介绍完毕
- 模型的定义在第二章节已经介绍完毕
- 优化器采用常用的
SGD - 损失函数使用交叉熵损失
cross_entropy
完整训练和验证代码如下:
import pandas as pd
import torch
from torch.utils import data as torch_data
from torch.nn import functional as torch_functional
import torch.nn.functional as F
from tensorboardX import SummaryWriter
from Dataset import GetLoader
from models.LeNet import LeNet3D
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def validation(valid_loader, path_ckpt):
model = LeNet3D()
model_ckpt = torch.load(path_ckpt)
model.load_state_dict(model_ckpt['model_state_dict'])
# model = torch.nn.DataParallel(model).to(device)
model.eval()
model.to(device)
loss_sum = 0
acc_sum = 0
for step, (data, label) in enumerate(valid_loader):
img = data.to(device)
# print(img.shape)
targets = label.to(device)
outputs = model(img).squeeze(1)
loss = F.cross_entropy(outputs, torch.max(targets, 1)[1]).to(device)
loss_sum += loss.detach().item()
prediction = torch.max(outputs, 1)[1]
pred_y = prediction.data.cpu().numpy()
target = torch.max(targets, 1)[1]
target_y = target.data.cpu().numpy()
acc_sum += sum((pred_y-target_y)==0)
loss_avg = loss_sum / len(valid_loader)
return loss_avg, acc_sum
def train():
MAX_EPOCH = 70
ITR_PER_CKPT_VAL = 1
data_train = './database/train'
data_val = './database/val'
train_data_retriever = GetLoader(data_train)
valid_data_retriever = GetLoader(data_val)
train_loader = torch_data.DataLoader(train_data_retriever, batch_size=8, shuffle=True, num_workers=4, pin_memory=False, worker_init_fn=_init_fn)
valid_loader = torch_data.DataLoader(valid_data_retriever, batch_size=1, shuffle=False, num_workers=4, pin_memory=False, worker_init_fn=_init_fn)
model = LeNet3D()
# model = torch.nn.DataParallel(model).to(device)
model.train()
model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
best_valid_score = 0
writer = SummaryWriter(comment='Linear')
for i_epoch in range(1, MAX_EPOCH + 1):
loss_sum = 0
N = 0
for step, (data, label) in enumerate(train_loader):
img = data.to(device)
# print(img.shape)
targets = label.to(device)
outputs = model(img).squeeze(1)
loss = F.cross_entropy(outputs, torch.max(targets, 1)[1]).to(device)
loss_sum += loss.detach().item()
# print('run ', step, loss_sum)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_avg = loss_sum / len(train_loader)
print("[Epoch " + str(i_epoch) + " | " + "train loss = " + ("%.7f" % loss_avg) + "]")
writer.add_scalar('scalar/train_loss', loss_avg, i_epoch)
if i_epoch % ITR_PER_CKPT_VAL == 0:
# Saving checkpoint.
path_ckpt = r"./checkpoints/" + str(i_epoch) + ".pth.tar"
torch.save({"epoch": i_epoch, "model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict()}, path_ckpt)
loss_val, acc_sum = validation(valid_loader, path_ckpt)
accuracy = acc_sum * 100 / len(valid_data_retriever)
print("[Epoch " + str(i_epoch) + " | " + "val loss = " + ("%.7f" % loss_val) + " accuracy = " + ("%.3f" % accuracy) + "%]")
writer.add_scalar('scalar/val_loss', loss_val, i_epoch)
writer.add_scalar('scalar/val_acc', accuracy, i_epoch)
if best_valid_score < accuracy:
path_ckpt_best = r"./checkpoints/best_acc.pth.tar"
torch.save({"epoch": i_epoch, "model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict()}, path_ckpt_best)
best_valid_score = accuracy
writer.close()
if __name__=='__main__':
train()
到这里,从数据到网络,再到整合到一起的训练和验证过程,都完成了。从整个结构上来说,还是比较简单的。亮点就在于这是一个3维的模型,和3维的训练任务。拿二维的思路套在三维这里,是同样适用的。
对上述的代码部分没有逐一的进行介绍,不懂和感兴趣的,可以直接去我的博客主页,查看相关实战项目,有对这块部分拆解的文章,欢迎查看。
如果需要应用,直接改写validation部分即可。这里就不赘述了,后面我们就讲述到的,相信你自己也能改写的比较好。
四、总结
尽管已经完成了3为分类任务的整个过程,从数据的处理,到模型的构建,再到训练和评估。但依旧存在诸多问题,主要体现在以下几点:
- LeNet3D模型结构较为简单
- 图像灰度图像,数据处理部分没有数据增强
目前想到要改进的就这么两点,也是我在下一篇增强篇里面,着重添加的部分。其中网络部分的模型,前面我已经添加了一个GitHub的链接,可以直接引用过来,替换LeNet3D,亲测有效。
图像增强部分,引入水平、垂直方向翻转、随机旋转、加噪声、滤波、归一化等等,希望通过这些数据增强的实战,能够自己也写几个符合自己数据集的数据增强方式,这是目的。