3DSSD: Point-based 3D Single Stage Object Detector (阅读笔记)
3DSSD
- 文章贡献
- 模型介绍
-
- 混合采样(Fusion Sampling)
-
- 设计动机
- 挑战
- Feature-FPS
- Fusion Sampling
- 回归框预测网络
-
- Anchor-free 回归头
- 中心类别分配策略(3D Center-ness Assignment Strategy)
- Loss Function
- 实验部分
-
- 数据增强
- 消融实验
文章贡献
- 提出了一种基于点的轻量化、高效的三维单级目标检测器,命名为3DSSD。去掉了所有现有的基于点的方法中必不可少的FP层和细化模块,从而大大减少了框架的推理时间。
- 提出了一种新的SA层融合采样策略,以保留充分的前景实例内部点,为回归和分类保留了丰富的信息。
- 设计了一个精致的盒子预测网络,使得网络整体高效精确。
模型介绍
混合采样(Fusion Sampling)
设计动机
在以往基于点设计的模型基本是双阶段的,大多有SA模块和FP模块。SA层用于下采样点以提高效率并扩大接收域,FP层用于下采样过程中对下采样点扩大特征以恢复所有点。在第二阶段使用一个精炼模块来优化RPN网络产生的预测。
其中SA模块是必不可少的,但是FP模块和精炼模块可以有所改动来提高模型的推理速度。

挑战
SA模块使用D-FPS来选择点的子集成为下采样的代表点。当没有FP模块时,box预测网络将被这些仅存的具有代表性的点所引导。这种均匀的抽样方式使得大部分具有代表性的点都是背景点(因为背景点比前景点多)。使得诸多前景点被完全擦除,而不能被box预测网络所检测到。
且一些距离较远的目标将拥有更少的点,使得其更难被检测到。
points recall ——内部点在抽样的代表性点中仍存在的实例数量与实例总数之间的商。

但采样的代表点少时接近50%的实例被完全抹去。
应对这个在下采样时实例被抹去的问题,之前的大多工作都是采用FP模块来找回这些丢失的实例中的点,这样做也加大了计算量和推理时间。
Feature-FPS
作者发现语义信息能够很好的被深度神经网路所捕获到。因为来自不同对象的点的语义特征是截然不同的。
所以当FPS使用特征距离(feature distance)作为测度单位时,能够删除很多的背景点,保留更多的前景点,包括那些距离较远的前景点。
同时使用语义特征距离作为测度单位会产生一些问题,一个实例可能将保留多个点。如一辆车的轮子和车窗(因为特征有很大区别)。为了减少实例的冗余,作者同时使用空间距离和语义特征距离作为测度单位。
C ( A , B ) = λ L d ( A , b ) + L f ( A , B ) C(A,B)=\lambda L_d(A,b)+L_f(A,B) C(A,B)=λLd(A,b)+Lf(A,B)
其中 L d , 和 L f L_d,和L_f Ld,和Lf分别代表L2空间欧氏距离和特征距离 λ \lambda λ为平衡参数。
作者将这种采样方式命名为Feature-FPS(F-FPS),在表2中可以看出这种采样方式对实例点的采样有较好的改善。
Fusion Sampling
F-FPS的设计能够保留大量的实例中的点。但是由于所有的具有代表性的点数量 N m N_m Nm是固定的大小,使得许多背景点在下采样的过程中被丢弃,这样有利于后续的预测框回归,但对目标的分类是不利的(正负样例比例不均衡),即在SA模块的grouping阶段(用于从相邻点中获取信息来增强该点特征)中,背景点无法找到足够的周围背景点,使其无法扩大其感受野。从而模型很难对前景点和背景点做分类。
F-FPS比D-FPS拥有更高的recall和定位精度,但是F-FPS将更多的背景点当作前景点。
所以SA模块之后,不但需要收集更多的前景点也需要足够多的背景点。作者提出了融合采样(Fusion Sampling,FS)。
FS在SA模块中同时使用D-FPS和F-FPS。如使用这两种策略分别采样 N m / 2 N_m/2 Nm/2个点,然后继续通过这两组点进行grouping操作。
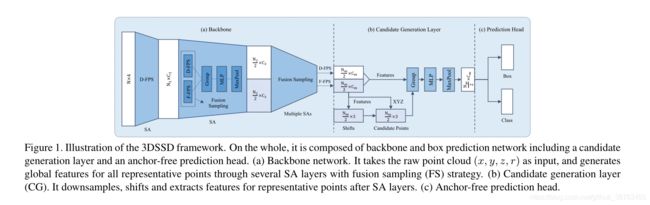
回归框预测网络
在得到混合采样的点的子集后,需要进行后续的预测。以往的基于点的方法(point-based)中大多需要在检测头(Detection Head)之前添加一层SA模块来提取特征(包含三个步骤——中心点选择、周围点提取、语义特征生成)
为了进一步降低计算成本,作者在预测头之前提出了一个SA模块的变体——候选生成层(candidate generation layer,CG)。只用F-FPS中的提取的点作为初始中心点(因为D-FPS提取的大多是背景点)。

如图2,与VoteNet相似,这些初始中心点在它们的相对位置的监督下移动到它们对应的实例中。
这些橘黄色的点为移动操作后的候选点(candidate points)。CG层使用这些点作为中心点。
为什么使用这些点而不是原始点作为中心点在后面讨论
接下去在F-FPS和D-FPS生成的所有点中寻找候选点一定范围内的点,将它们的归一化位置和语义特征连接起来作为输入,并使用MLP层提取特征用于之后的检测头的回归和分类如图1所示。
Anchor-free 回归头
作者设计的融合采样策略(fusion sampling)和CG层可以很好的替代耗时的FP模块和检测头的精细模块。
如果使用anchor来进行后续的操作,将涉及非常大量的anchor,如在nuScenes数据集中,有10种类别的数据和非常多的角度,至少需要设计20个anchor——10种不同尺寸,2个角度{0,180}。作者选择使用anchor-free方式。
回归头中预测每个候选点到对应实例的距离 ( d x , d y , d z ) (d_x,d_y,d_z) (dx,dy,dz)、实例大小 ( d l , d w , d h ) (d_l,d_w,d_h) (dl,dw,dh)以及角度。
因为没有初始的角度设置,作者使用Frustum pointnets for 3d object detection from RGB-D data 中的分类和回归公式的混合方式。
预定义 N a = 12 N_a=12 Na=12 个等分的角度bins,并将预测的目标分类到其中。残差参照bin值进行回归。
中心类别分配策略(3D Center-ness Assignment Strategy)
训练模型需要给候选点分配前景背景标签。以往的方式都是通过IoU阈值来实现,或者通过mask来分配每个像素点的标签。FCOS提出了一种连续中心标签,取代了原有的二元分类标签,进一步区分像素,产生了更好的性能。
由于激光点云的点都在目标表面,他们的中心标记将非常的小且相似,使其很难从其他点中得出好的预测。
所以作者使用调整后的候选点来完成这项任务。——靠近实例中心的候选点往往能够获得更准确的定位预测,也更容易标记其类别。
候选点的标签通过两个步骤产生:
- 确定其是否在一个实例的 l m a s k l_{mask} lmask内。——{0,1}取值范围
- 计算其中心与与其对应的实例的6个表面的距离
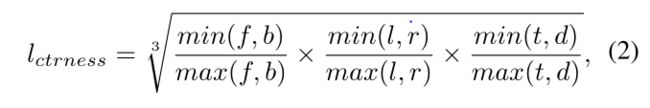
其中 f , b , l , r , t , d f,b,l,r,t,d f,b,l,r,t,d 分别代表前后左右上下表面的距离。 - 最终前后景分类标签由 l m a s k l_{mask} lmask和 l c t r n e s s l_{ctrness} lctrness的乘积决定。
Loss Function

包含分类损失、回归损失和偏移(shifting)损失。
其中 N c 和 N p N_c和N_p Nc和Np代表所有候选点数量和前景候选点数量。 s i 和 u i s_i和u_i si和ui分别为预测分类分数和中心类别标签并使用交叉熵损失 L c L_c Lc。回归损失 L r L_r Lr包含距离回归损失 L d i s t L_{dist} Ldist、尺寸回归损失 L s i z e L_{size} Lsize、角度回归损失(angle regression loss) L a n g l e L_{angle} Langle和角损失(corner loss) L c o r n e r L_{corner} Lcorner。
其中距离和尺寸回归损失使用 s m o o t h − l 1 smooth-l_1 smooth−l1 loss。
角度回归损失包含方向分类损失和残差(residual)预测损失:
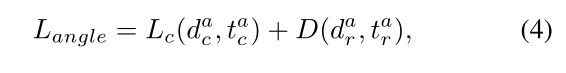
角(corner)损失为预测的8个角与ground truth的8个角的距离:
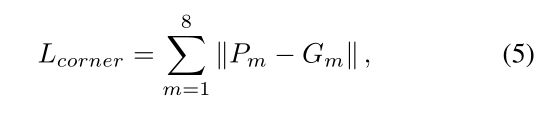
偏移损失用于CG层,使用 s m o o t h − l 1 smooth-l_1 smooth−l1 loss。 N p ∗ N^*_p Np∗是F-FPS中的前景点的总数。
角损失及预测box的8个角与ground truth 的8个角的偏差,Anchor free 方式的常用评价方式。
实验部分
分别在KITTI和nuScenes上进行了测试。

数据增强
使用与SECOND 相同的增强方法。每个点云都沿着X轴进行随机翻转,沿着Z轴进行随机旋转,并进行随机缩放。
消融实验
通过消融实验证明了FS模块、CG模块的偏移、3D中心分配的有效性。