李宏毅机器学习作业三
前言
项目三是训练一个简单的卷积神经网络,实现食物图片的分类。现在还没有完成,在这里做一个记录。第三个作业比前面两个难了不少,遇到了很多困难,首先还是去理解老师已经给出的代码。这里用了paddlepaddle的深度学习框架,代码里碰到很多不懂的api就去paddlepaddle官网找文档然后加了注释。现在代码已经理解了但是运行还有一些错误。


数据集分别为training、validation 以及 testing
training 以及 validation 中的照片名称格式为 [类别]_[编号].jpg,例如 3_100.jpg 即为类别 3 的照片(编号不重要)
四个步骤:
1.定义数据集
2.模型结构
3.模型训练
4.测试
一、定义数据集
在 paddle 中,我们可以利用 paddle.io 的 Dataset 及 DataLoader 来"包装"数据,使后续的训练及预测更为方便。 Dataset 需要 overload 两个函数:len 及 getitem len 必须要回传 dataset 的大小,而 getitem 则定义了当函数利用 [idx] 取值时,数据集应该要怎么回传数据。 实际上我们并不会直接使用到这两个函数,但是使用 DataLoader 在 enumerate Dataset 时会使用到,没有做的话会在运行阶段出现错误。
# Import需要的套件
import os
import cv2
import time
import numpy as np
import paddle
from paddle.io import Dataset, DataLoader
from paddle.nn import Sequential, Conv2D, BatchNorm2D, ReLU, MaxPool2D, Linear, Flatten
from paddle.vision.transforms import Compose, Transpose, RandomRotation, RandomHorizontalFlip, Normalize, Resize
# 分配CPU设备
place = paddle.CPUPlace()
paddle.disable_static(place)
print(paddle.__version__)# 在框架下不用open一个文件然后去读,而是聚成一个dataset基类,再定义一个业务类FoodDataset,然后在initial方法里面传入必要的一些组件
class FoodDataset(Dataset):
def __init__(self, image_path, image_size=(128, 128), mode='train'):
self.image_path = image_path #传递路径
self.image_file_list = sorted(os.listdir(image_path)) #os.listdir(path)返回指定的文件夹包含的文件或文件夹的名字的列表。
self.mode = mode
# training 时做 data augmentation
self.train_transforms = Compose([ #数据增强组件
Resize(size=image_size), #缩放
RandomHorizontalFlip(), #依据概率p对图片进行水平翻转,p默认0.5
RandomRotation(15), #中心旋转随机(-15,15)度
Transpose(), #矩阵转置
Normalize(mean=127.5, std=127.5) #归一化
])
# testing 时不需做 data augmentation
self.test_transforms = Compose([
Resize(size=image_size),
Transpose(),
Normalize(mean=127.5, std=127.5)
])
def __len__(self): #len方法:返回整个数据的样本数
return len(self.image_file_list)
def __getitem__(self, idx): #后面在引用实例化这个类的时候就可以通过枚举拿到训练数据
img = cv2.imread(os.path.join(self.image_path, self.image_file_list[idx])) #os.path.join()函数:连接两个或更多的路径名组件
if self.mode == 'train':
img = self.train_transforms(img) #训练时对图片进行增强
label = int(self.image_file_list[idx].split("_")[0]) #标签
return img, label
else:
img = self.test_transforms(img)
return img#定义超参,测试集,验证集
batch_size = 128
traindataset = FoodDataset('./food-11/training')
valdataset = FoodDataset('./food-11/validation')
train_loader = DataLoader(traindataset, places=paddle.CPUPlace(), batch_size=batch_size, shuffle=True, drop_last=True)
#DataLoader是paddle提供的一个api,返回一个迭代器,该迭代器根据 batch_sampler给定的顺序迭代一次给定的 dataset,把traindataset传给train_loader。
#shuffle (bool) - 是否需要在生成样本下标时打乱顺序,默认值为False。drop_last (bool) - 是否需要丢弃最后无法凑整一个mini-batch的样本。默认值为False。
val_loader = DataLoader(valdataset, places=paddle.CPUPlace(), batch_size=batch_size, shuffle=False, drop_last=True)
二、模型结构
卷积神经网络时常使用“Conv+BN+激活+池化”作为一个基础block,我们可以将多个block堆叠在一起,进行特征提取,最后连接一个Linear层,实现图片分类。
#定义模型结构
class Classifier(paddle.nn.Layer):
def __init__(self): #执行父类的构造方法。
super(Classifier, self).__init__() #super调用父类方法
# input 维度 [3, 128, 128]
self.cnn = Sequential( #声明一个容器,在这个容器里堆叠卷积层,pooling层,激活函数层
Conv2D(3, 64, 3, 1, 1), #[64, 128, 128],即输出是64*128*128维的图片
# 第一层卷积层和池化层的配置
# 第一个参数代表输入数据的通道数,例RGB图片通道数为3;
# 第二个参数代表输出数据的通道数,这个根据模型调整;
# 第三个参数是卷积核大小
# 第四个参数是stride,步长
# 第五个参数是padding,补1。padding: 设置在所有边界增加值为 0 的边距的大小(也就是在feature map 外围增加几圈 0 )
BatchNorm2D(64), #批归一化
ReLU(), #激活函数
MaxPool2D(2, 2, 0), # [64, 64, 64]
# 第一个参数是kernel_size,max pooling的窗口大小,
# 第二个参数是stride,max pooling的窗口移动的步长。默认值是kernel_size
# 第三个参数输入的每一条边补充0的层数,默认是0
Conv2D(64, 128, 3, 1, 1), # [128, 64, 64]
BatchNorm2D(128),
ReLU(),
MaxPool2D(2, 2, 0), # [128, 32, 32]
Conv2D(128, 256, 3, 1, 1), # [256, 32, 32]
BatchNorm2D(256),
ReLU(),
MaxPool2D(2, 2, 0), # [256, 16, 16]
Conv2D(256, 512, 3, 1, 1), # [512, 16, 16]
BatchNorm2D(512),
ReLU(),
MaxPool2D(2, 2, 0), # [512, 8, 8]
Conv2D(512, 512, 3, 1, 1), # [512, 8, 8]
BatchNorm2D(512),
ReLU(),
MaxPool2D(2, 2, 0), # [512, 4, 4] #最后变为512张4*4的图片
)
self.fc = Sequential(
Linear(512 * 4 * 4, 1024), #全连接层512*4*4,变为1维,1024是下一层的大小
ReLU(),
Linear(1024, 512),
ReLU(),
Linear(512, 11) #11个分类
)
def forward(self, x): #调用以上方法
x = self.cnn(x)
x = x.flatten(start_axis=1)
x = self.fc(x)
return x #得到结果# 查看模型结构
my_model = paddle.Model(Classifier())
my_model.summary((-1, 3, 128, 128))
#打印网络的基础结构和参数信息。参数可传可不传,这个元组是形容输入的数据的维度,-1是batchsize,是一个动态的不定值,3代表彩色的图,128代表长和宽。模型结构:
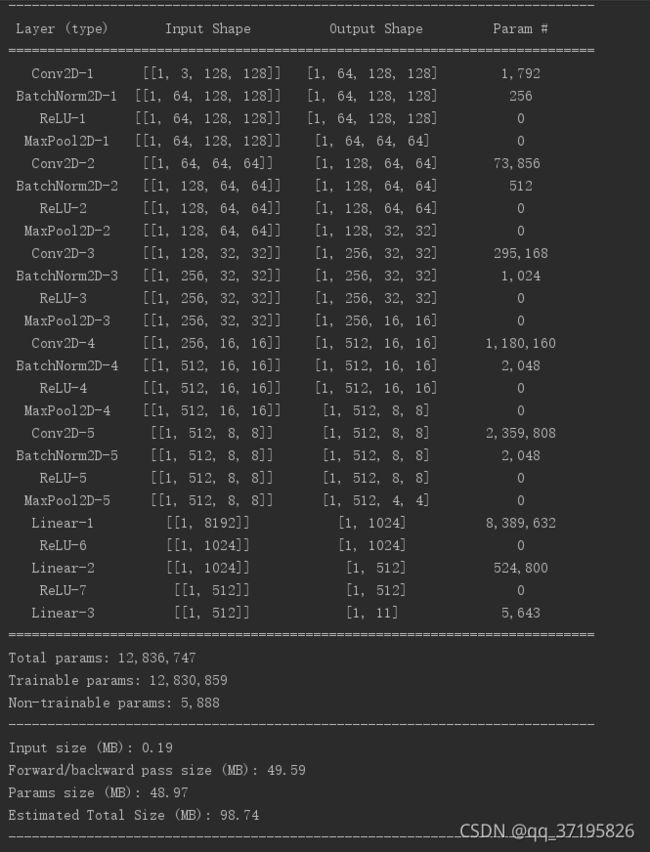
三、模型训练
使用训练数据集训练,并使用验证数据集寻找好的参数
#模型训练
epoch_num = 30#循环次数
learning_rate = 0.001#学习率
model = Classifier()
loss = paddle.nn.loss.CrossEntropyLoss() # 因为是分类任务,所以 loss 使用 CrossEntropyLoss
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=model.parameters()) # optimizer 使用 Adam,“Adam可以理解为加了Momentum 的 RMSpropprint('start training')
for epoch in range(epoch_num): #第一个循环是epoch,在epoch中取一个batch一个batch的数据
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
#模型训练
model.train()
for img, label in train_loader(): #前面封装好的loader
optimizer.clear_grad() #每次清一下梯度
pred = model(img) #把输入通过model方法,调用了forward方法,
step_loss = loss(pred, label) #算loss
step_loss.backward() #backward就是算梯度的意思
optimizer.step() #更新step
#算准确率和损失
train_acc += np.sum(np.argmax(pred.numpy(), axis=1) == label.numpy())
train_loss += step_loss.numpy()[0]
#模型验证
model.eval()
for img, label in val_loader():
pred = model(img)
step_loss = loss(pred, label)
val_acc += np.sum(np.argmax(pred.numpy(), axis=1) == label.numpy())
val_loss += step_loss.numpy()[0]
# 将结果打印出来
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % \
(epoch + 1, epoch_num, \
time.time() - epoch_start_time, \
train_acc / traindataset.__len__(), \
train_loss / traindataset.__len__(), \
val_acc / valdataset.__len__(), \
val_loss / valdataset.__len__()))!mkdir './food-11/train_val'
!cp ./food-11/training/* ./food-11/train_val/
!cp ./food-11/validation/* ./food-11/train_val/这里有个报错
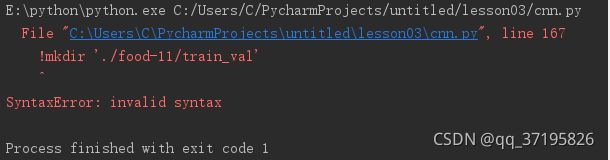
在网上搜了一下,mkdir的作用是创建目录./food-11/train_val
cp 命令好像是linux里的命令,使用 -r 参数可以将 packageA 下的所有文件拷贝到 packageB 中:
cp -r /home/packageA/* /home/cp/packageB/
traindataset = FoodDataset('./food-11/train_val')
train_loader = DataLoader(traindataset, places=paddle.CPUPlace(), batch_size=batch_size, shuffle=True, drop_last=True)epoch_num = 30
learning_rate = 0.001
model_best = Classifier()
loss = paddle.nn.loss.CrossEntropyLoss() # 因为是分类任务,所以 loss 使用 CrossEntropyLoss
optimizer = paddle.optimizer.Adam(learning_rate=learning_rate, parameters=model_best.parameters()) # optimizer 使用 Adam
print('start training...')
for epoch in range(epoch_num):
epoch_start_time = time.time()
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# 模型训练
model_best.train()
for img, label in train_loader():
optimizer.clear_grad()
pred = model_best(img)
step_loss = loss(pred, label)
step_loss.backward()
optimizer.step()
train_acc += np.sum(np.argmax(pred.numpy(), axis=1) == label.numpy())
train_loss += step_loss.numpy()[0]
# 将结果打印出来
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % \
(epoch + 1, epoch_num, \
time.time()-epoch_start_time, \
train_acc/traindataset.__len__(), \
train_loss/traindataset.__len__()))
报错
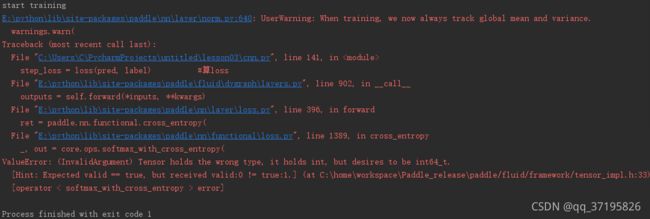
这个错误的原因应该是由于windows下,numpy对于int型数据默认的是int32类型,而 softmax_with_cross_entropy op要求是int64类型,导致不匹配报错。
这个是类似的问题和解决方案:
https://blog.csdn.net/qq_15821487/article/details/114835293
四、测试
用上面训练好的模型预测
#用刚刚训练好的模型预测
batch_size = 128
testdataset = FoodDataset('./food-11/testing', mode='test')
test_loader = DataLoader(testdataset, places=paddle.CUDAPlace(0), batch_size=batch_size, shuffle=False, drop_last=True)
prediction = list()
model_best.eval()
for img in test_loader():
pred = model_best(img[0])
test_label = np.argmax(pred.numpy(), axis=1)
for y in test_label:
prediction.append(y)
# 将结果写入CSV文件
with open('./predict.csv', 'w') as f:
f.write('Id,Category\n')
for i, y in enumerate(prediction):
f.write('{},{}\n'.format(i, y))
总结
很多api的用法卸载了注释里,写的很详细。现在对代码已经基本理解了,等把程序跑通之后再来更新。