MaskedFace-Net | 新冠疫情中的口罩检测(附论文及源代码)
计算机视觉研究院专栏
作者:Edison_G
戴口罩似乎是限制covid-19传播的一种解决方案。在这种情况下,有效的识别系统被期望用于检查人在被管制的区域是否戴口罩。因此,对于训练深度学习模型来检测戴口罩的人和不戴口罩的人,一个大量的戴口罩的人脸数据集是必要的。

长按扫描二维码关注我们
一、简要
目前,没有可用的大型戴口罩人脸图像数据集允许检查面部是否正确遮挡。事实上,由于不良行为或个人(如儿童、老年人)的原因,许多人没有正确地戴上口罩。由于这些原因,一些戴着口罩的活动打算让人们了解这个问题和良好的做法。

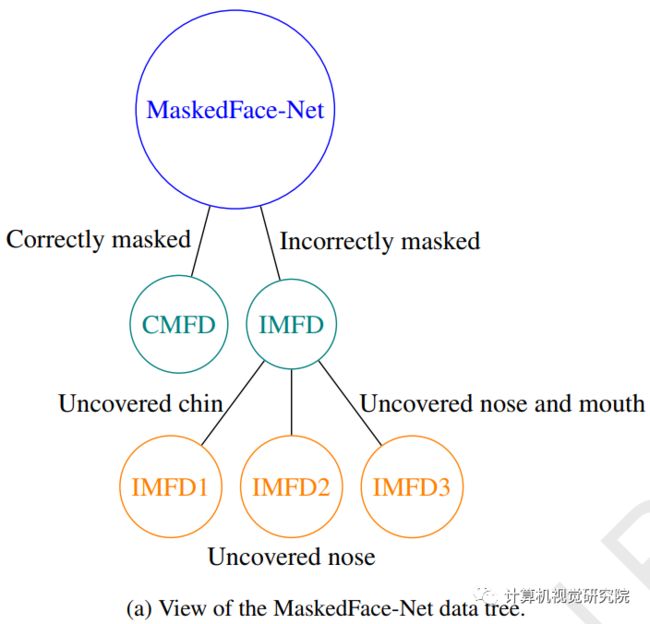
从这个意义上说,有研究者就提出了一种图像编辑方法和三种遮挡人脸检测数据集;即正确遮挡人脸数据集(CMFD)、错误遮挡人脸数据集(IMFD)及其全局遮挡人脸检测(MaskedFace-Net)的组合。现实的遮挡人脸数据集有两个目标:
i)检测他们是否有戴口罩;
ii)检测是否正确戴口罩(例如在机场入口或人群中)。
据我们所知,没有一个大的遮挡人脸数据集为检测是否戴口罩提供如此细粒度的分类。此外,这项工作在全球提出了应用的遮挡人脸对人脸形变模型,允许生成其他遮挡人脸图像。新提出的遮挡人脸数据集可以在https://github.com/cabani/MaskedFace-Net上找到。由NVIDIA公司在线公开提供的Flickr-Faces-HQ3 (FFHQ)数据集,已被用于生成MaskedFace-Net。
二、背景与动机
戴口罩似乎是限制covid-19传播的一种解决方案。在这种情况下,有效的识别系统被期望用于检查人在被管制的区域是否戴口罩。为了完成这项任务,训练深度学习模型需要大量的遮挡人脸数据集来检测。从这个意义上说,在文献中可以找到一些具有病毒相关遮挡的大型人脸图像数据集;例如:MAsked FAces dataset (MAFA)【Detecting masked faces in the wild with lle-cnns. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)】,the Real-World Masked Face Dataset (RMFD)【https://github:com/X-zhangyang/Real-World-Masked-Face-Dataset】和一个遮挡人脸识别数据集【Masked face recognition dataset and application. ArXiv:2003.09093】,其由Masked Face Detection Dataset (MFDD), Real-world Masked Face Recognition Dataset (RMFRD) and Simulated Masked Face Recognition Dataset (SMFRD) 组成。
三、应用及数据输出
人脸图像数据集(Flickr-Faces-HQ3 (FFHQ))被选为创建一个增强的遮挡人脸图像。实际上,FFHQ包含70000张高质量的人脸图像,PNG文件格式为1024×1024分辨率,并公开提供。FFHQ数据集在年龄、种族、视点、灯光和图像背景方面提供了许多多样性。它最初是作为生成式对抗性网络(GAN)的基准而创建的。
全局数据流程图如下图所示。
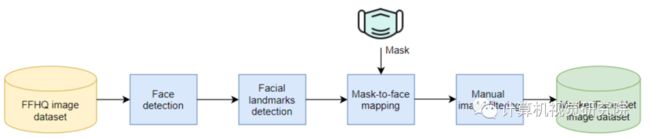
上图显示了用于生成“correctly/incorrectly masked face images MaskedFace-Net”数据集的图像编辑方法的主要阶段。特别是,MaskedFace-Net数据集是通过定义一个mask-toface deformable model创建的。

(a):depicts the structure of the generated MaskedFace-Net dataset.
(b):shows a pseudo-code of the mask-to-face deformable model applied for generating outputs (a) of the MaskedFace-Net dataset

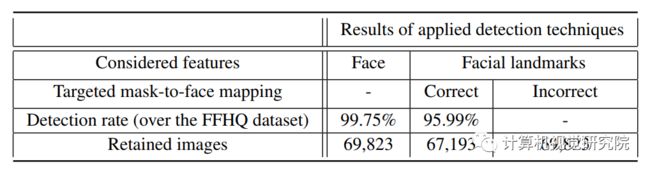
对于FFHQ【3】的每一个人脸图像(例如上图a所示),基于Haar特征的级联分类器被用于检测一个感兴趣的区域(检测人脸矩形)。然后,一个特定的关键点检测器“预测68个关键点【4】【5】”应用于感兴趣的检测区域,并允许自动检测68个面部结构的坐标(见图b所示的样本)。
【3】:“dataset of face images Flickr-Faces-HQ (FFHQ)” https://github:com/NVlabs/ffhq-dataset.
【4】:“Facial point annotations” https://ibug:doc:ic:ac:uk/resources/facial-point-annotations/.
【5】:“shape predictor 68 face landmarks.dat.bz2” https://github:com/davisking/dlib-models#shape_predictor_68_face_landmarksdatbz2.
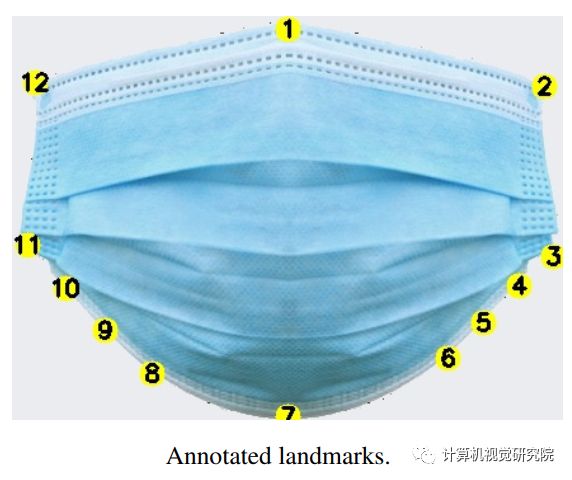
此外,还选择了广泛的face protection mask (single-use blue face protection mask)作为映射的参考图像(见下图中的示例)。对于后者,已经手动注释了12个关键点,用于描绘遮挡区域(多边形区域)。
在此阶段,针对目标情况定义了四种mask-to-face映射(见下图)即覆盖鼻子、嘴和下巴,口罩只覆盖鼻子和嘴,口罩只覆盖嘴和下巴,口罩只覆盖嘴以下。
对于每种类型的mask-to-face映射(CMFD、IMFD1、IMFD2或IMFD3),从自动检测到的68个位置中保留12个面部关键点的子集;然后与12个遮挡关键点匹配。通过这种方式,遮挡可以适合每个目标病例的面部的特定区域。因此,创建了一个mask-to-face deformable model来生成MaskedFace-Net。此外,每个目标情况最多可以有2个关键点(在12个关键点中),它们的位置在有限的周长内随机移位。因此,MaskedFace-Net也包含了各种各样的遮挡定位。
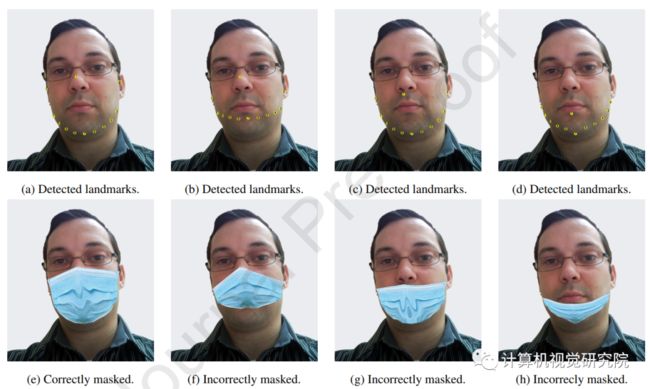
最后,应用了基于遮挡图像和人脸图像之间位置所定义的点对点对应关系变换来映射目标人脸区域上的口罩像素。图中显示每种类型的人脸位置实例和对应的口罩映射。
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
论文源码获取|回复“MF”获取论文及源代码