MapReduce计算框架——初探MapReduce【14000字详解】
目录
零,学习目标
一,学习导入
二,讲解
(一)MapReduce核心思想
(二)MapReduce模型
(三)MapRudce编程实例——词频统计思路
1,Map阶段(映射阶段)
2,reduce阶段(归并阶段)
(四)MapReduce编程实例——词频统计实现
1,准备数据文件
(1)在虚拟机上创建文本文件
(2)上传文件到HDFS指定目录
2,创建Maven项目
3,添加相关依赖
4,创建日志属性文件
5,创建词频统计映射器类
知识点:java数据类型与hadoop数据类型对应关系
6,创建词频统计启动器类
7,运行词频统计驱动器类,查看结果
8,修改词频统计映射器类
9,修改词频统计器类
10,启动词频驱动器类,查看结果
11,创建词频统计归并器类
12,修改词频统计驱动器类
13,运行词频统计驱动器类,查看结果
14,修改词频统计归并器类
15,修改词频统计驱动器类
16,启动词频统计驱动器类,查看结果
17,采用多个Reduce做合并
(1)MR默认采用哈希分区HashPartitioner
(2)修改词频统计驱动器类,设置分区数量
18,打包上传到虚拟机
(1)利用Maven导包
(2)将jar包上传到虚拟机
(3)运行jar包,查看结果
(4)降低项目JDK版本,重新打包
(5)重新上传jar包到虚拟机
(6)运行jar包,查看结果
19,创建新词频统计驱动器类
20,重新打包上传虚拟机并执行
21、将三个类合并成一个类完成词频统计
22、合并分区导致的多个结果文件
23、统计不同单词数
零,学习目标
1,理解MapReduce核心思想
2,掌握MapReduce编程模型
3,理解MapReduce编程实例——词频统计
一,学习导入
由于MapReduce是Hadoop系统的另一个核心组件,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。因此,本文将针对MapReduce分布式计算框架进行详细讲解。
二,讲解
(一)MapReduce核心思想
1, MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果,这种思想来源于日常生活与工作时的经验,同样也完全适合技术领域。
2,MapReduce作为一种分布式计算模型,它主要用于解决海量数据的计算问题。使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段。
| 阶段 | 功能 |
| Map阶段 | 负责将任务分解,即把复杂的任务分解成若干个“简单的任务”来并行处理,但前提是这些任务没有必然的依赖关系,可以单独执行任务。 |
| Reduce阶段 | 负责将任务合并,即把Map阶段的结果进行全局汇总 |
MapReduce就是“任务的分解与结果的汇总”。即使用户不懂分布式计算框架的内部运行机制,但是只要能用Map和Reduce思想描述清楚要处理的问题,就能轻松地在Hadoop集群上实现分布式计算功能。

MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为,移动数据需要大量的网络传输开销。
(二)MapReduce模型
MapReduce是一种编程模型,用于处理大规模数据集的并行运算。使用MapReduce执行计算任务的时候,每个任务的执行过程都会被分为两个阶段,分别是Map和Reduce,其中Map阶段用于对原始数据进行处理,Reduce阶段用于对Map阶段的结果进行汇总,得到最终结果。

MapReduce函数
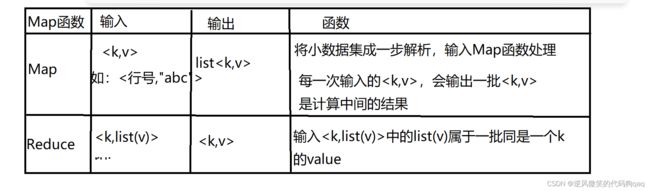
(三)MapRudce编程实例——词频统计思路
1,Map阶段(映射阶段)
键入键值对—>输出键值对
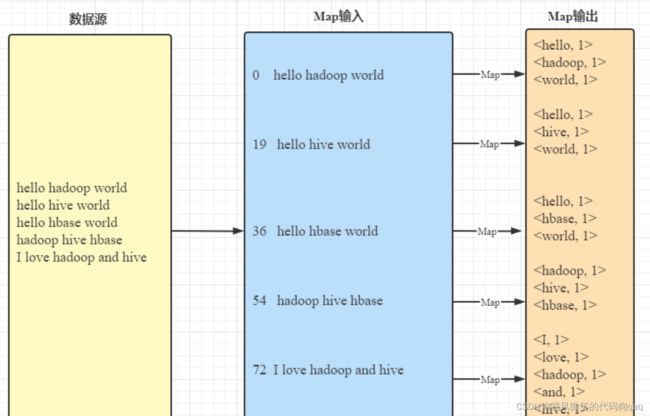
2,reduce阶段(归并阶段)
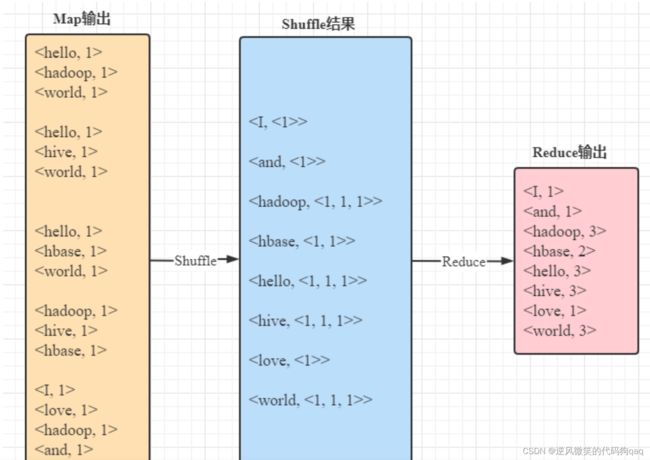
(四)MapReduce编程实例——词频统计实现
1,准备数据文件
(1)在虚拟机上创建文本文件
创建wordcount文件,在里面创建words.txt文件

(2)上传文件到HDFS指定目录
创建/wordcount/iput目录,执行命令:hdfs dfs -mkdir -p /wordcount/iput

将本地文件words.txt,上传到HDFS/wordcount/input目录

在Hadoop WebUI上查看上传文件

2,创建Maven项目
创建Maven项目-MRWordCount
单机【Finish】按钮
3,添加相关依赖
在pom.xml文件里添加相关的hadoop和junit依赖
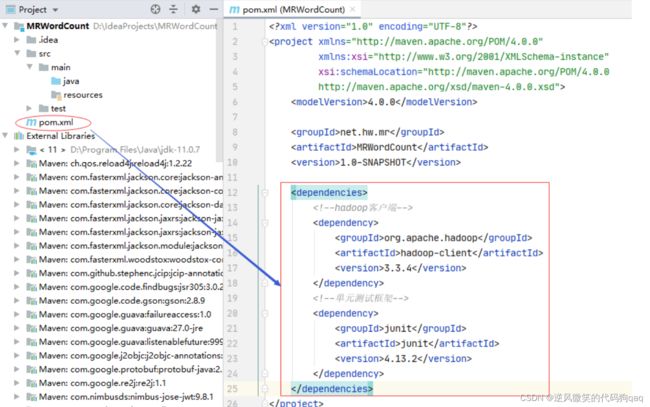
org.apache.hadoop
hadoop-client
3.3.4
junit
junit
4.13.2
4,创建日志属性文件
在resources目录里创建log4j.properties文件

log4j.rootLogger=INFO, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/wordcount.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
5,创建词频统计映射器类
创建net.hw,mr包,在包里创建WordCountMapper类

为了更好理解Mapper类的作用,在map()函数里暂时不进行文本分词处理,直接利用context输出
key和value.
package net.hw.mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 功能:词频统计映射器类
* 作者:逆风微笑的代码狗
* 日期:2022年12月16日
*/
public class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 直接将键值对数据传到下一个阶段
context.write(key, value);
}
}
Mapper<泛型参数1,泛型参数2,泛型参数3,泛型参数4>说明

知识点:java数据类型与hadoop数据类型对应关系

6,创建词频统计启动器类
在net.hw.mr包里创建WordCountDriver类
package net.hw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* 功能:词频统计驱动器类
* 作者:逆风微笑的代码狗
* 日期:2022年12月16日
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(WordCountDriver.class);
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(LongWritable.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(Text.class);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/wordcount/input");
// 创建输出目录
Path outputPath = new Path(uri + "/wordcount/output");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);
// 添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);
// 等待完成
job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
注意导包问题

import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
7,运行词频统计驱动器类,查看结果
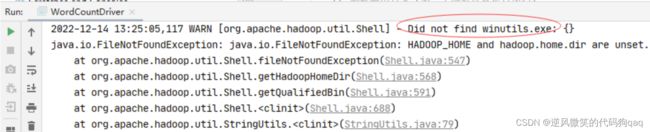
再次运行,会出现大量统计结果

8,修改词频统计映射器类
行首数字对于我们做单词统计没有任何用处,只需要拿到每一行内容,按空格拆分成单词,每个单词计数1,因此WordCountMapper的输出应该是单词和个数,于是,输出键类型为Text,输出值类型为IntWritable
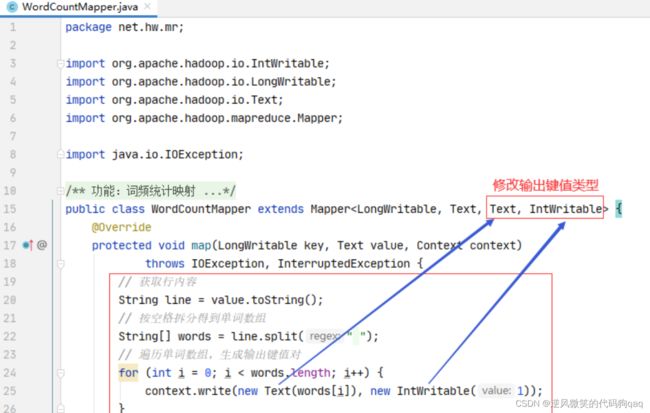
public class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行内容
String line = value.toString();
// 按空格拆分得到单词数组
String[] words = line.split(" ");
// 遍历单词数组,生成输出键值对
for (int i = 0; i < words.length; i++) {
context.write(new Text(words[i]), new IntWritable(1));
}
}
}
由于WoedCountMapper的键值类型发生变化,所以必须告诉WordCountMapper
9,修改词频统计器类

10,启动词频驱动器类,查看结果
观察输出结果,map阶段会按键排序输出

对于这样一组键值对,传递到reduce阶段,按键排序,其值构成迭代器
I <1>
and <1>
hadoop <1,1,1>
hbase <1,1>
hello <1,1,1>
hive <1,1,1>
love <1>
world <1,1,1>
11,创建词频统计归并器类
1,一个类继承Reducer,变成一个Reducer组件类。
2,Reducer组件会接收RMapper组件的输出结果。
3,第一个泛型对应的是Mapper输出key类型。
4,第二个泛型对应的是Mapper输出value类型。
5,第三个泛型和第四个泛型是Reducer的输出key类型和输出value类型。
6,Reducer组件不能单独存在,但是Mapper组件可以单独存在。
7,当引入Reducer组件后,输出结果文件内容就是Reducer的输出key和输出value。
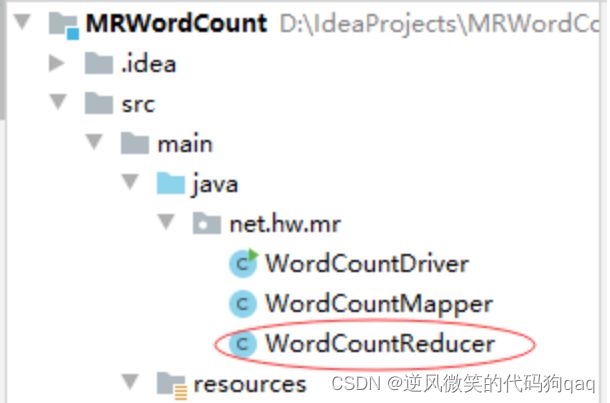
package net.hw.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 功能:词频统计归并器
* 作者:逆风微笑的代码狗
* 日期:2022年12月16日
*/
public class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// 定义整数数组列表
List integers = new ArrayList<>();
// 遍历输入值迭代器
for (IntWritable value : values) {
// 将每个值添加到数组列表
integers.add(value.get()); // 利用get()方法将hadoop数据类型转换成java数据类型
}
// 输出新的键值对,注意要将java字符串转换成hadoop的text类型
context.write(key, new Text(integers.toString()));
}
}
创建了词频统计归并器之后,我们一定要告知词频统计驱动器类
12,修改词频统计驱动器类
设置词频统计的Reducer类及其输出键类型和输出值类型(Text,Text)
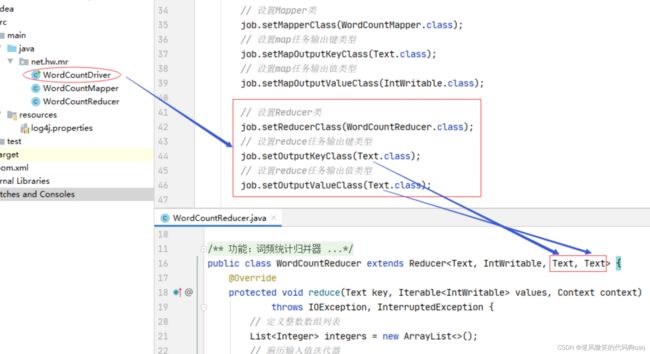
13,运行词频统计驱动器类,查看结果

现在我们需要修改词频统计归并器,将每个键(单词)的值迭代器进行累加,得到每个单词出现的总次数。
14,修改词频统计归并器类
输出键值类型改为IntWritble遍历值迭代器,累加得到单词出现次数

package net.hw.mr;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 功能:词频统计归并器
* 作者:逆风微笑的代码狗
* 日期:2022年12月16日
*/
public class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// 定义键出现次数
int count = 0;
// 遍历输入值迭代器
for (IntWritable value : values) {
count += value.get(); // 其实针对此案例,可用count++来处理
}
// 输出新的键值对,注意要将java的int类型转换成hadoop的IntWritable类型
context.write(key, new IntWritable(count));
}
}
由于修改了词频统计归并器的输出值类型(由Text类型改成了IntWritable类型),必须在词频统计驱动器类里进行设置
15,修改词频统计驱动器类
修改归并任务的输出值类型(IntWritable类型)

16,启动词频统计驱动器类,查看结果
此时,可以看到每个单词出现的次数

17,采用多个Reduce做合并
(1)MR默认采用哈希分区HashPartitioner
Mapper输出key.hash.code & Integer.MAX_VALUE % Reduce任务数量
 (2)修改词频统计驱动器类,设置分区数量
(2)修改词频统计驱动器类,设置分区数量
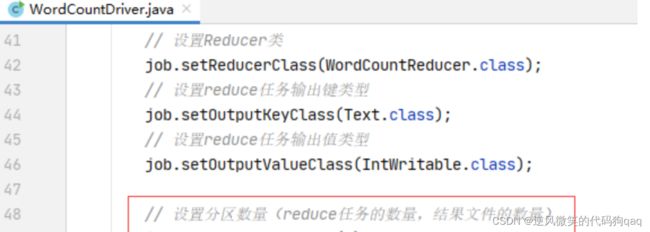
运行查看结果
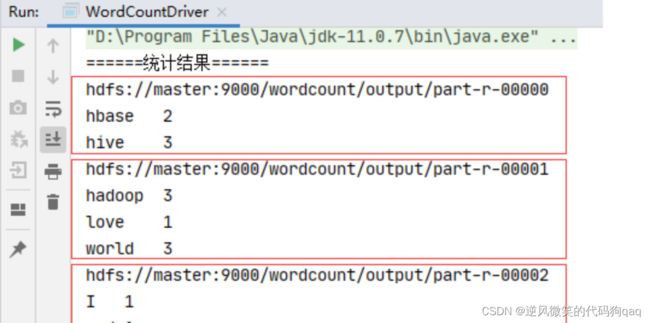
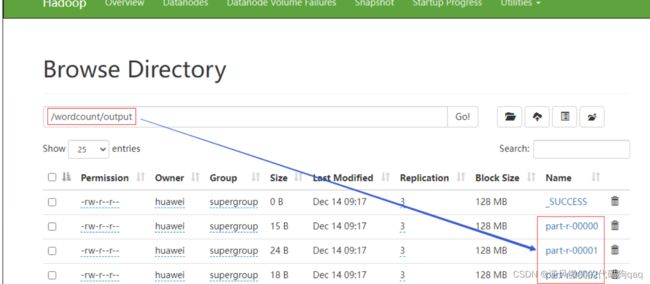
在 Hadoop WebUI界面上可以看到,产生了三个结果文件
18,打包上传到虚拟机
(1)利用Maven导包
打开Maven管理窗口,找到项目的lifeCycle下的package命令
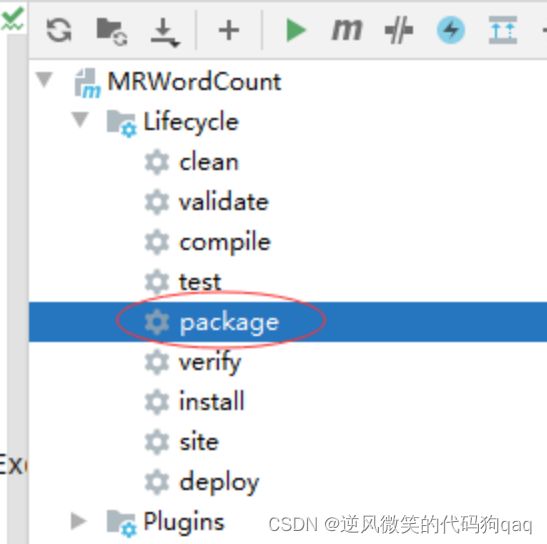
双击package命令,报错,maven插件版本不对
修改pom.xml添加maven插件,记得要刷新maven


再次打包,即可生成

(2)将jar包上传到虚拟机
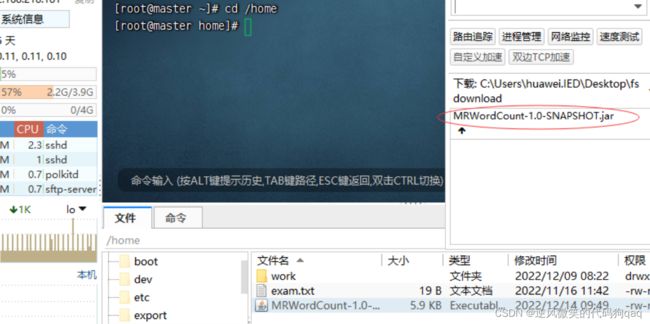
查看上传的jar包

(3)运行jar包,查看结果

(4)降低项目JDK版本,重新打包
修改JDK

修改语言级别

修改Java编译器版本

修改pom.xml文件

重新利用maven打包

(5)重新上传jar包到虚拟机
删除master虚拟机上的jar包

重新上传jar包
(6)运行jar包,查看结果
执行命令:看图


19,创建新词频统计驱动器类
由用户指定输入路径和输出路径,如果用户不指定,那么由程序来设置

package net.hw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.net.URI;
/**
* 功能:新词频统计驱动器类
* 作者:逆风微笑的代码狗
* 日期:2022年12月16日
*/
public class WordCountDriverNew {
public static void main(String[] args) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(WordCountDriverNew.class);
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Text.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置reduce任务输出键类型
job.setOutputKeyClass(Text.class);
// 设置reduce任务输出值类型
job.setOutputValueClass(IntWritable.class);
// 设置分区数量(reduce任务的数量,结果文件的数量)
job.setNumReduceTasks(3);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 声明输入目录
Path inputPath = null;
// 声明输出目录
Path outputPath = null;
// 判断输入参数个数
if (args.length == 0) {
// 创建输入目录
inputPath = new Path(uri + "/wordcount/input");
// 创建输出目录
outputPath = new Path(uri + "/wordcount/output");
} else if (args.length == 2) {
// 创建输入目录
inputPath = new Path(uri + args[0]);
// 创建输出目录
outputPath = new Path(uri + args[1]);
} else {
// 提示用户参数个数不符合要求
System.out.println("参数个数不符合要求,要么是0个,要么是2个!");
// 结束应用程序
return;
}
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);
// 添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);
// 等待完成
job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
}
}
20,重新打包上传虚拟机并执行
重新打包
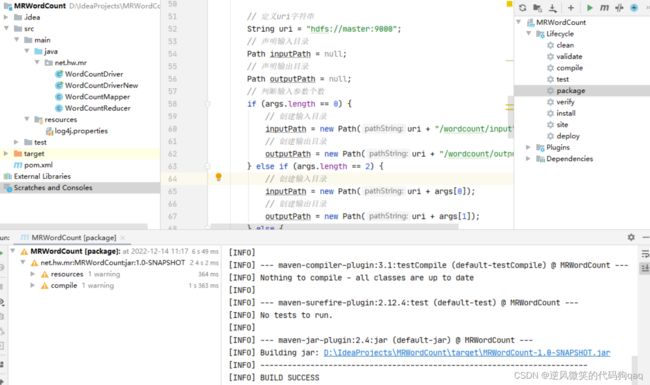
删除先前的jar包

上传新的单词文件
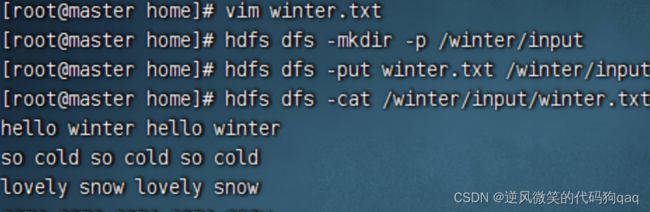
上传新的jar包

执行命令


执行命令


21、将三个类合并成一个类完成词频统计
在net.hw.mr包里创建wordconunt类
package net.hw.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.net.URI;
/**
* 功能:词频统计
* 作者:逆风微笑的代码狗
* 日期:2022年12月16日
*/
public class WordCount extends Configured implements Tool {
public static class WordCountMapper extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 获取行内容
String line = value.toString();
// 清洗所有英文标点符号(\p——属性[property],P——标点符号[Punctuation])
line = line.replaceAll("[\\pP]", "");
// 按空格拆分得到单词数组
String[] words = line.split(" ");
// 遍历单词数组,生成输出键值对
for (int i = 0; i < words.length; i++) {
context.write(new Text(words[i]), new IntWritable(1));
}
}
}
public static class WordCountReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
// 定义输出键出现次数
int count = 0;
// 历输出值迭代对象,统计其出现次数
for (IntWritable value : values) {
count = count + value.get();
}
// 生成键值对输出
context.write(key, new IntWritable(count));
}
}
@Override
public int run(String[] strings) throws Exception {
// 创建配置对象
Configuration conf = new Configuration();
// 设置数据节点主机名属性
conf.set("dfs.client.use.datanode.hostname", "true");
// 获取作业实例
Job job = Job.getInstance(conf);
// 设置作业启动类
job.setJarByClass(WordCountDriver.class);
// 设置Mapper类
job.setMapperClass(WordCountMapper.class);
// 设置map任务输出键类型
job.setMapOutputKeyClass(Text.class);
// 设置map任务输出值类型
job.setMapOutputValueClass(IntWritable.class);
// 设置Reducer类
job.setReducerClass(WordCountReducer.class);
// 设置reduce任务输出键类型
job.setOutputKeyClass(Text.class);
// 设置reduce任务输出值类型
job.setOutputValueClass(IntWritable.class);
// 设置分区数量(reduce任务的数量,结果文件的数量)
job.setNumReduceTasks(3);
// 定义uri字符串
String uri = "hdfs://master:9000";
// 创建输入目录
Path inputPath = new Path(uri + "/wordcount2/input");
// 创建输出目录
Path outputPath = new Path(uri + "/wordcount2/output");
// 获取文件系统
FileSystem fs = FileSystem.get(new URI(uri), conf);
// 删除输出目录(第二个参数设置是否递归)
fs.delete(outputPath, true);
// 添加输入目录(允许多个)
FileInputFormat.addInputPath(job, inputPath);
// 设置输出目录(只能一个)
FileOutputFormat.setOutputPath(job, outputPath);
// 等待完成
boolean res = job.waitForCompletion(true);
// 输出统计结果
System.out.println("======统计结果======");
FileStatus[] fileStatuses = fs.listStatus(outputPath);
for (int i = 1; i < fileStatuses.length; i++) {
// 输出结果文件路径
System.out.println(fileStatuses[i].getPath());
// 获取文件系统数据字节输入流
FSDataInputStream in = fs.open(fileStatuses[i].getPath());
// 将结果文件显示在控制台
IOUtils.copyBytes(in, System.out, 4096, false);
}
if (res) {
return 0;
} else {
return -1;
}
}
public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new WordCount(), args);
System.exit(res);
}
}
上传一个有标点符号的单词文件
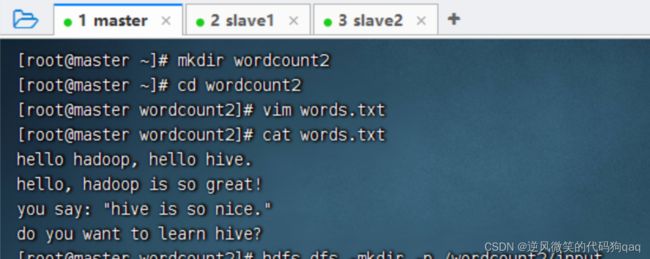
行程序,查看结果

先前为了打包上传能在虚拟机上运行jar包,将JDK版本降低到8,因此还得修改编译器配置文件

运行程序,查看结果

22、合并分区导致的多个结果文件
利用hadoop的-getmerge命令来完成

23、统计不同单词数
利用MR对多个文件进行词频统计,得到的一个或多个结果文件,多个结果文件可以合并成一个最终结果文件,比如part-r-final,然后利用Linux命令统计行数即可。
利用cat -nu命令
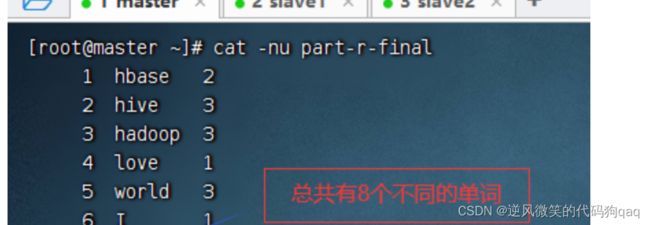
利用wc -l命令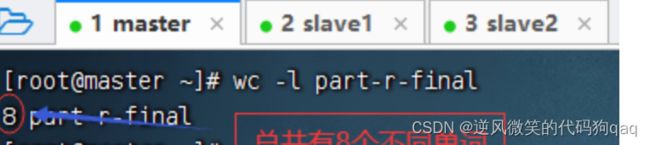
wc命令还有其他参数