目标检测模型的评价指标(Acc, Precision, Recall, AP, mAP, RoI)
目标检测模型的评价指标(Acc, Precision, Recall, AP, mAP, RoI)
对于一个目标检测模型的好坏,总的来说可以从以下三个方面来评估:
- 分类的精度如何。一般可以用准确度(Accuracy),精度(Precision),召回率(Recall Rate), PR 曲线,AP,mAP等
- 定位的精度如何。比如 IoU
- 运行的速度如何。比如 fps,一秒处理几张图。
严格说某些场合也会很在意模型的大小,这也是一个研究方向,比如 squeeze net, mobile net, shuffle net 等。所以除了上面三个维度,模型的大小也可以是一个评价维度。
1.基础知识
由于有些指标是统计指标,所以我们先回顾一下相关的统计学知识。
我们在做假设检验的时候会犯两种错误。
- 第一,原假设是正确的,而你判断它为错误的;
- 第二,原假设是错误的,而你判断它为正确的。
我们分别称这两种错误为第一类错误和第二类错误。也许不是很清晰,直接看下面的图(图片来自知乎)就一目了然了。

对于上面的两张图,我们的原假设是没有怀孕。对于第一张图,原假设是对的,但是却判断它为错误的。对于第二张图,原假设是错误的,但是却判断它为正确的。
这个问题如果放到混淆矩阵里面就更清楚了。
| 真实值(label)\ 预测值 | 正例 | 反例 |
|---|---|---|
| 正例 | TP | FN |
| 反例 | FP | TN |
2. 准确度(Accuracy, Acc)
准确度是所有预测中预测正确的比例。
A c c = T P + T N T P + F N + F P + F N Acc = \frac{TP + TN}{TP + FN + FP + FN} Acc=TP+FN+FP+FNTP+TN
3. 精确率(Precision)
精确率是指在所有检测出的目标中检测正确的概率。
P r e c i s i o n = T P T P + F P Precision = \frac{TP}{TP + FP} Precision=TP+FPTP
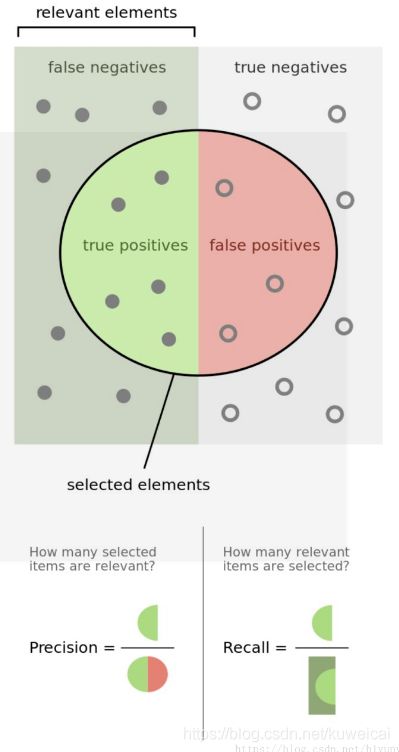
精确率是从预测的结果的角度来定义。精确率又称为查准率。需要注意的是, Precision 和 Accuracy 是不一样的,Accuracy 针对所有样本,而 Precision 仅针对检测出来(包括误检)的那一部分样本。
4. 召回率(Recall)
召回率是指所有的正样本中正确识别的概率。
R e c a l l = T P T P + F N Recall = \frac{TP}{TP + FN} Recall=TP+FNTP
召回率是从样本的角度出发的。召回率又称查全率。
也可以参考下面这这一幅图。
5. AP(Average Precision)
查准率和查全率是一对矛盾的度量,一般而言,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。我们从直观理解确实如此:我们如果希望好瓜尽可能多地选出来,则可以通过增加选瓜的数量来实现,如果将所有瓜都选上了,那么所有好瓜也必然被选上,但是这样查准率就会越低;若希望选出的瓜中好瓜的比例尽可能高,则只选最有把握的瓜,但这样难免会漏掉不少好瓜,导致查全率较低。通常只有在一些简单任务中,才可能使查全率和查准率都很高。所以为了更全面的衡量模型的性能提出了 AP。
在看 AP 之前先来看看 PR 曲线(Precision Recall Curve),即横轴为 Recall,竖轴为 Precision。

而 AP 表示的是检测器在各个 Recall 情况下的平均值,对应的就是 PR 曲线下的面积(AUC, Area Under Curve)。
从离散的角度来说 AP 可以表达如下式。
A P = ∑ P r i ∑ r AP = \frac{\sum{P_{r_i}}}{\sum{r}} AP=∑r∑Pri
其中 P r i P_{r_i} Pri 表示 PR 曲线上 r − i r-i r−i 所对应的 P P P 值, 而 ∑ r = 1 \sum{r} = 1 ∑r=1。
显然 AP 是针对某一个类别来说的,比如 马这一个单一类别。
6. mAP
AP 是针对单个类别的识别器,而 mAP 是从类别的维度对 AP 进行平均,因此可以评价多分类器的性能。
m A P = A P n u m _ c l a s s e s mAP = \frac{AP}{num\_classes} mAP=num_classesAP
mAP的大小一定在[0,1]区间,越大越好。该指标是目标检测算法中最重要的一个。
6.1 VOC mAP
VOC mAP 是我们常看到的一种 mAP 计算方式。上面说的是理论上的 mAP 的定义,但是在实际计算中,由于 PR 曲线并不是单调递减的,而是抖动的,所以对进行“平滑”操作。由于 VOC 在 2010 年更新了“平滑”的方式,所以这里说的是 2010 之后的计算方式。
在 IoU = 0.5 的情况下,针对每一个不同的 Recall 值(包括0和1),选取其大于等于这些 Recall 值时的 Precision 最大值,然后计算 PR 曲线下面积作为 AP 值,从而计算 mAP。结合下面表格就更清晰了。
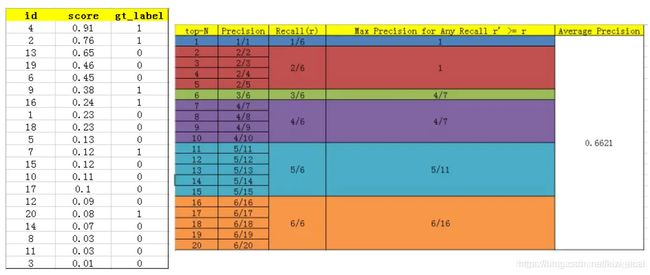
6.2 COCO mAP
跟 VOC mAP 类似,只是 COCO 数据集会统计不同 IoU 下的 mAP, 比如 0.5, 0.75, 0.95 等。
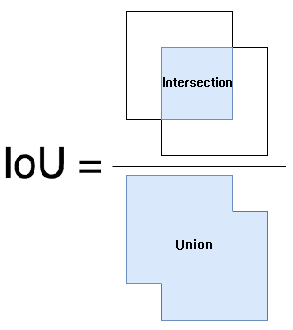
7. IoU(Intersection over Union)
IoU 计算的是 “预测的边框” 和 “真实的边框” 的交集和并集的比值。下面这幅图就可以很清晰的表达出 IoU 的概念了。
参考文献
目标检测 — 评价指标
目标检测之 IoU
模型评估常用指标