牛津大学最新 | LUMix:Mixup改进版,几行代码轻松涨点!
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
后台回复【LUMix】获取论文!!!
摘要
当使用噪声样本和正则化技术进行训练时,现代深度网络可以更好地泛化。Mixup[41]和CutMix[39]已被证明对数据增强有效,有助于避免过拟合。基于先前Mixup的方法线性地组合图像和标签以生成额外的训练数据。然而,如果目标没有占据整个图像,这是有问题的,很难正确分配标签权重,而且没有明确的标准来衡量它,如下图1所示。为了解决这个问题,在本文中,作者提出了LUMix,它通过在训练期间添加标签扰动来模拟这种不确定性。LUMix很简单,因为它只需几行代码即可实现,并且可以以最低的计算成本普遍应用于任何深度网络,如CNN和Vision Transformers。广泛的实验表明,LUMix可以持续提高ImageNet上具有广泛多样性和容量的网络的性能,例如,小模型DeiT-S的性能提高0.7%,大模型XCiT-L的性能提高0.6%。还证明,当在ImageNet-O和ImageNet-A上进行评估时,LUMix可以导致更好的鲁棒性。
介绍
现代深度网络,如ResNet[12]、ConvNeXt[23]、视觉transformer[8]经常过度参数化,这有助于实现良好的性能。最近在更好地训练深度网络方面的进展,通常需要大量的数据扩增和正则化技术来防止模型过拟合。其中,Mixup[41]和CutMix[39]被发现非常有用。
Mixup和CutMix首先采样随机因子λ∈[0,1]控制两个训练样本的比例,然后组合原始输入以生成通过线性插值的具有相应伪标签的新图像。然而,作者认为,这种置信度重新加权并不是最优的。如图1的(1)和(3)所示,当将两个图像的不同区域组合在一起时,很难估计一个图像的特征相对于另一图像的特征可感知的实际比例。同时,如图1(2)和(4)所示,新的crop可以遮挡原先图像上的辨别区域。标签在这种情况下,可能是误导性的,并在训练过程中带来错误的监督信号。这些问题也在最近的一些研究中发现,例如TransMix[2]、PuzzleMix[19]、ResizeMix[27]和SaliencyMix[33]。然而,这些方法要么利用额外的模型来纠正错误标签[2,19,33],要么简单地避免Mixup过程中引入的不确定性[27]。
在本文中,不同于以往试图摆脱Mixup过程带来的标签噪声,LUMix将对标签噪声进行建模。为此,两个术语被添加到原始标签Mixup的顶部。一是从深度网络的预测中产生的,判断输入中是否存在显著目标。另一个从均匀分布中随机采样添加到标签分布中以模拟Mixup过程中的标签不确定性。有趣的是,作者观察到这样一个简单的加法运算可以很好地执行与SOTA的基于Mixup的方法相当[2]。作者探索并揭示了在Mixup过程中引入的随机噪声也可能是导致改进的原因。
实验结果表明,对数据扩增的调整可以为许多不同的模型带来一致的改进。例如,LUMix可以帮助将DeiT-S的top-1精度提高0.7%,将ImageNet上的大型变体XCiT-L的图像分类精度提高0.6%。此外,当在三个不同的基准上进行评估时,LUMix还可以在几个具有挑战性的数据集(例如ImageNet-O和ImageNet-A)上获得更好的鲁棒性。通过在ImageNet上进行更好的预训练,作者还发现使用LUMix预训练的模型可以在Pascal VOC上获得更好的语义分割性能。
LUMix只需几行代码即可实现,几乎没有引入额外的计算。同时与TransMix[2]不同,TransMix[2]只能专门应用于视觉Transformer,LUMix也适用于CNN架构,例如ConvNext[23]和ResNet[13]。
首先,本文的贡献可以概括为两个方面:
作者提出了一种简单而有效的方法,以最小的计算成本进一步改进CutMix开销,进行了大量实验以验证作者的方法在不同任务的准确性和鲁棒性方面的有效性。
作者的方法表明,通过扰动对标签噪声进行建模也是提高网络性能的一种可行方法,这可能会激励更多未来的工作探索这个方向,并帮助了解基于Mixup的方法是如何工作的。
相关工作
Mixup及其变体 Mixup是一种在输入图像和标签空间(用一个相同的随机比例[41])中线性插值的数据增强技术。为了更好地概括,CutMix[39]使用复制粘贴中方法,以便原始图像的详细纹理可以保留。Manifold-Mixup[34]进一步Mixup应用到特征空间中以获得更好的性能。作为CutMix的扩展,Attentive CutMix[35]、SnapMix[18]、Resize CutMix[27]和saliency CutMix[13]引入了另一个模型,以在Mixup过程中提取前景显著目标,因为图像的背景部分与标签的相关性较小。作者认为这种操作可以在一定程度上缩小数据扩增范围,因为背景区域也可以在训练期间用作负样本。MoEx[21]和PatchUp[11]提出将特征归一化应用于图像Mixup,这在与CutMix结合时也很有效。StyleMix[15]应用了风格转换以使用Mixup图像的上下文。除了提高分类精度外,还有还有一些论文倾向于使用Mixup相关方法来提高网络的鲁棒性。例如,[42]和[31]发现,Mixup可以用于改善网络的Loss 校正和鲁棒性。并发工作RecursiveMix[38]多次迭代Mixup过程,以进一步提高性能,原则上,这应该是对作者工作的补充。最近的TransMix[2]也关注这个问题,但它选择根据视觉transformer[8]生成的注意力图来操纵标签空间。作者的工作与TransMix最相似,因为TransMix和作者的方法都专注于标签空间操作。然而,TransMix需要一个额外的注意力图来重新加权标签,以便它只能与基于Transformer的网络兼容,网络末端有一个类token。相反,LUMix是模型无关的,适用于CNN和基于Transformer的架构。
标签平滑 作者提出的方法也与标签平滑方法[25,30,40]相关,因为LUMix和标签平滑都是操作标签置信度。然而,LUMix在以下方面从根本上不同于标签平滑:
LUMix链接每个样本到标签sapce中的分布,但标签平滑将标签权重更改为固定数字。
LUMix公司仅扰动要Mixup的类,但标签平滑更改所有类的权重。LUMix帮助查找标签比标签平滑效果更好的分布。
标签平滑与LUMix互补。作者在第4节中证明,通过标签平滑训练的基线可以通过LUMix以明显的优势进一步改进。
LUMix
CutMix概述
LUMix基于CutMix。这里作者首先回顾一下CutMix流程,以便更好地理解它。给定两个来自训练数据集的输入图像、及其对应标签、,CutMix的目的是通过将两个真实样本Mixup在一起。Mixup过程可以公式化为:

其中,HW是一个二元掩码,其大小为图像H×W,1是一个与M形状相同的图,填充数字1,以及⊙ 是元素乘法。λ ∼ U(0,1)是Mixup标签中的比例。这里U(0,1)表示范围[0,1]的均匀分布。有时图像中的裁剪大小会超过图像的边界,在本例中,作者进一步剪裁,以使其能够很好地适应。λ在剪切操作发生时,应当重新计算。如(width,height)Crop为(,),则λ。
LUMix
如以上所述,CutMix和LUMix之间的差异在标签空间中。在这里,作者添加另一个随机因子λβαα至CutMix中采样的原始比例λ:
其中、是决定比率的超参数。
λ和λ在最终λ。λ的引入可以被视为模拟人类标注的一种方式,人类标注者也不确定应给予Mixup目标中的每一类什么置信度。对于λ,根据网络的预测得分计算,作者假设网络产生C类得分为,则λ计算为:

其中 A,B 表示输入样本 A,B 的有标签类的索引。由于网络的得分可以在一定程度上表明前景目标的存在,当 pA < λ 时,损失趋于较小,反之亦然。在这里引入 λ 等价于仅对目标类进行损失剪裁。这样,在执行 CutMix 数据增强时,如果Crop A 中没有有效目标,网络将受到较少的惩罚。λ 的引入要求网络预测是可靠的,然而,最近的一些论文[31,41]发现,当 λ 从 α > 0.4的 Β分布 β (α,α)中取样时,深度网络往往是不自信的。本文的所有实验也都是在 α = 0.8的情况下进行的。为了缓解这个问题,作者添加了一个新的正则化项 R,有助于更好地校准网络预测:
其中 L0是使用 SoftMax 或二元交叉熵软标签计算的损失值。η是控制正则化因子 R的影响的超参数:
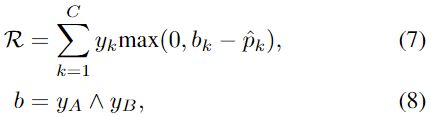
其中 b ∈{0,1} C 是一个二元向量。这里R类似Hinge loss,只惩罚正样本类。
PyTorch 风格的伪代码
下面的算法1提供了 LUMix 的伪代码。作者演示了本方法可以通过大约10行代码巧妙地实现。还强调,代码中使用的所有操作都是快速、简单的,并且得到了当前流行的深度学习库(如 PyTorch、 TensorFlow 和 Jax)的支持。

实验
分类任务实验结果
结果表明,LUMix 可以帮助改进下面表1中列出的所有模型。

这些模型在参数量(从22M 到189M)和 FLOPs (从4.5 G 到36.1 G)方面具有广泛的容量。作者注意到,所有这些基线都很强大,因为它们经过了大量数据增强和正则化技术的仔细调整。因此,LUMix 在这些模型上实现的改进是显著的。具体来说,对于像 Deit-S 这样的小模型,LUMix 可以在 ImageNet 上获得0.7% 的收益。对于像 XCiT-L 这样的大模型,LUMix 也可以带来0.6% 的收益。作者强调,令人惊讶的在于,在数据增强方面的这种微小 变化,以最小的成本开销,就可以显著提高各种模型体系结构的整体性能。
消融研究
LUMix 中各组分对 LUMix 的影响。LUMix 由 λ、 λ 和正则化 R 三个不同组分组成。作者在下表2中显示了将这些因素应用于 DeT-S 的相对效果。从表中可以发现,无论是λ或 λ 都可以导致显着的改善(+ 0.6%)在 ImageNet 上的最高准确度。对这种高度正则化的网络应用辅助Loss R 也可以使 top-1精度增益为0.1% 。除了产生更准确的预测,在以下部分中,作者进一步表明,通过与 LUMix 一起训练,可以更好地校准网络的预测,使网络可以更加鲁棒。

不同随机比的消融实验,如下表3所示,显示了不同随机比对 LUMix 中随机因子λ和 λ 应用 Deit-S 时的最高精度。作者注意到,当 时,正类的标签权重被完全随机重新分配。令人惊讶的是,当标签置信度完全随机化时,网络仅仅降低了0.1% 。添加一些随机性到标签空间可以显著提高最终性能,但调整比率 r1,r2只能导致增量0.1% 的增益。

迁移到下游任务
在本部分中,作者将在ImageNet上预训练好的模型迁移到下游任务,并对它们进行评估,下游任务包括语义分割和弱监督目标定位。作者验证了 LUMix 对 ImageNet 的改进可以进一步转移到其他下游任务。
语义分割 在语义分割任务中,通过解码器对编码器(如视觉Transformer)的特征图进行处理,生成分割图 ,其中 N 是语义类的个数。作者保留 DeT-S 作为分割编码器,采用无卷积的分割器[29]作为语义分割解码器。分段器[29]解码器是一种基于Transformer的解码器,即在[29,36]中引入的masked Transformer。所有的语义分割结果都是在 Pascal 上下文数据集上进行评估的。根据下表4,LUMix 比正常的预训练基线分别提高了0.6% mAcc 和0.9% mIoU。在多尺度测试方面有一致的改进。

弱监督目标分割和定位 除了语义分割之外,作者进一步评估了用作者的方法在两个弱监督任务上训练的模型(1) Pascal VOC 2012基准上的弱监督自动分割(WSAS)[10]和(2) ImageNet-1k 验证集上的弱监督目标定位(WOSL)[28] ,以显示它的有效性,结果如下表5所示。
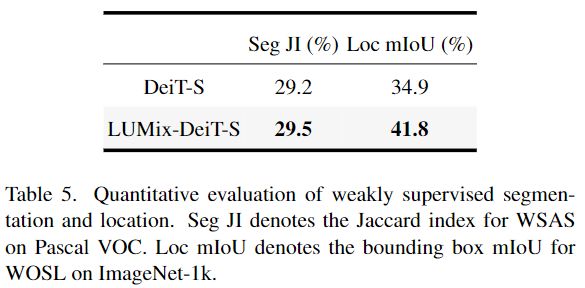
作者注意到这两个数据集中的边界框标签只能用于评估。作者在 ImageNet-1k 训练集上训练该模型,然后按照[26]的方法,通过将注意矩阵阈值化为二值注意力mask来评估注意力矩阵的质量。对于 WSAS,作者使用 PASCAL-VOC12上的真值和由 DeT-S 产生的二元注意力mask之间的 Jaccard 相似性来测量性能。至于 WOSL,由于注意力图本身可以用来定位目标,所以作者不需要使用基于 CAM 的方法。相反,作者可以直接从二元注意力mask中生成一个边界框作为预测,然后与真值进行比较。在这两个基准上,将把从 LUMix-DeT-S 或者普通的 DeT-S 生成的注意力mask与真值进行比较。评价分数可以定量地帮助作者了解 LUMix 是否对注意力图的质量有积极的影响。
鲁棒性分析
对遮挡的鲁棒性 作者按照[26]研究了在遮挡场景下 ViTs 的鲁棒性,其中部分或大部分图像内容缺失。具体来说,视觉Transformer将输入图像划分为14 × 14的空间网格,即分辨率为224 × 224的图像将进入196个patches。在这里,作者进行patches丢弃作为一种方式攻击输入,用0来mask原始图像的patches。例如,从输入中删除100个patches实际上会丢失大约一半的图像内容。在[26]之后,作者使用以下不同的设置来评估 ImageNet-1k 验证集上的分类准确性。
随机斑块丢弃随机选择输入图像的 M 个斑块并丢弃。
显著(前景)丢patches在高度显著的区域丢patches,以研究网络的鲁棒性。从 DINO [1]学习的注意图中提取出显著的斑块。
非显著(背景)patches丢失在图像的非显著区域中的patches。非显著区域的选择遵循与2中相同的方法。
如下表9所示,具有LUMix的DeiT-S比普通DeiT-S更抗遮挡,尤其是对于背景patches的丢弃。

空间洗牌的鲁棒性 通过对输入图像块进行重组洗牌,去除图像中的结构信息(空间关系) ,从而研究模型对空间结构的敏感性。具体来说,作者按照下面的[26]使用不同的网格大小随机改变图像patches。注意,洗牌网格大小为1意味着没有洗牌,而洗牌网格大小为196意味着所有patches token都被洗牌。下表7显示了与基线相比的一致性改进,LUMix-DeT-S 和 DeT-S 的所有洗牌网格大小的平均准确率分别为62.3% 和61.8% 。结果表明,LUMix 使得 Transformers 能够减少对位置嵌入的依赖,从而为分类保留最丰富的上下文信息。

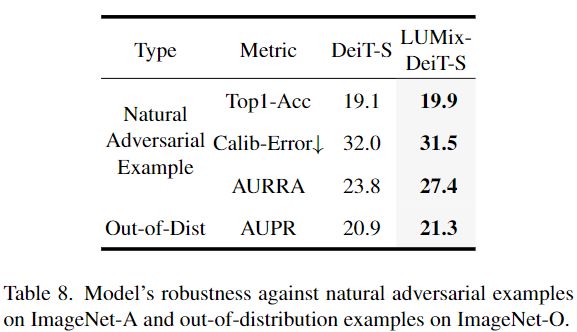
自然对抗性实验和分布外检测 作者分别使用ImageNet-Adversial (ImageNet-A)数据集[14]和ImageNet-O [14]数据集进行实验。
ImageNet-A收集7500个未经修改的、自然发生但“难”的图像。这些样本来自于一些具有挑战性的场景(如雾景、噪声和遮挡) ,这些场景会显著降低机器学习模型的识别性能。用于评估分类器对对手过滤示例的鲁棒性的度量包括top-1准确性,Calibration Error (CalibError)[14,20]和面积响应速率准确性曲线(AURRA)。校正误差衡量分类器如何能够可靠地预测它们的准确性。AURRA 是在[14]中介绍的一种不确定性估计度量。如下表8所示,在 LUMix 下训练的 DeT-S 在所有指标上都优于普通的 DeT-S。
ImageNet-O [14]是一个分布外检测数据集,它从不同于 ImageNet 训练分布的分布中收集2000张图像。未预见类别的异常情况应导致预测的可信度较低。指标是精确召回曲线(AUPR)下的面积[14]。下表显示,使用 LUMix 的 DeT-S 比 DeT-S 表现提升0.4% AUPR。
与其他Mixup变体的比较
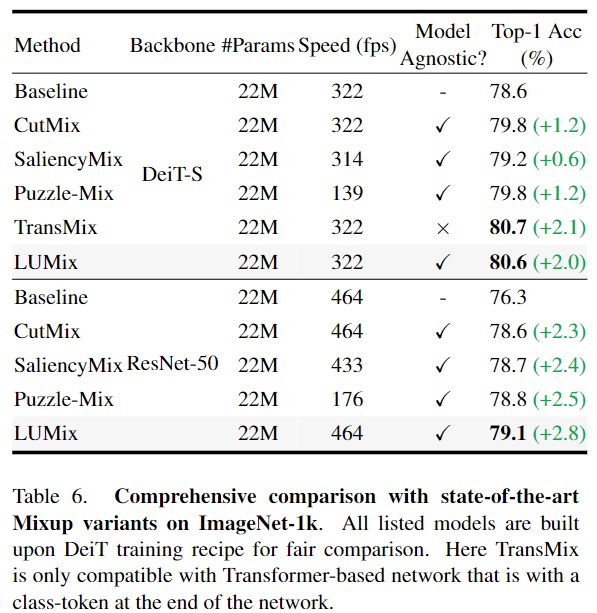
作者将LUMix方法和 ImageNet-1k 上其他基于 Mixup 的最新方法进行比较。为了公平比较,作者重新实现了下表6中报告的所有方法,并且在相同的训练配置下训练了一个 DeT-S,除了这些基于mixup的方法。除了 CutMix 之外,下表6中报告的基线是用作者的通用设置训练的。作者在batch size为128的 NVIDIA V100 GPU上测量每种方法的训练速度(吞吐量)。下表显示,LUMix 的性能优于除 TransMix 之外的所有其他 Mixup 方法。然而,Trans-Mix 仅与基于 Transformer 的网络兼容,而作者的 LUMix 是模型无关的,可以很好地推广到类似 ConvNeXt [23]和 ResNet [13]的 CNN 架构上。作者强调,这是至关重要的,因为大多数网络,即使是基于 Transformer 的网络,例如 Swin Transformer,都不包含类token来生成 TransMix 所需的注意力图。与其他基于模型无关的mixup方法相比,例如 Attenting-CutMix、 SaliencyMix 和 PuzzyMix,LUMix 在精度和速度的权衡方面优于所有这些方法。具体来说,LUMix 在 ImageNet 上的精度排名前一位,分别比 PuzzyMix 和 SaliencyMix 高出0.7% 和1.3% 。作者还比较了下表中的 LUMix 和其他基于 ResNet 的最先进的 Mixup 方法,从中作者可以得出结论,LUMix 在准确性和速度方面都优于这些方法。
讨论和分析
假设作者有一个训练数据集 D = ,,其中, 对于 D 中的所有数据样本都是 n 个有标签样本。P 是输入空间和目标空间之间的未知联合分布。作者可以用以,为中心的经验狄拉克三角分布 δ 来近似。

然而,可以有许多可能的估计 P,δ 只是其中之一。为了推广 δ,可以用邻近分布 ν,来代替 Dirac δ 分布 δ:

Mixup [41]本质上创建了一个新的邻域分布 μ ,它合成了新的数据样本对 x~,y~ 通过线性插值:
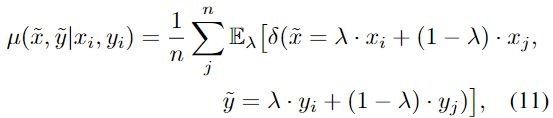
Mixup 的成功证明了这种线性归纳偏置有助于推广训练空间[41]。不像 Mixup 将 λ 平均分配给输入图像上的所有像素,CutMix 使用二元图将两个图像mixup在一起。然而,正如在第1节和最近的一些文章[2,19,33]中所讨论的,作者认为这可能会给 CutMix 带来问题,因为并非所有像素都是平等创建的。方程(1)中定义的二元mask,可以使生成的crop的语义与标签完全无关。这表明,对于 CutMix,两个输入的一些分布此原生内容可能被过滤掉,因此标签可能会产生误导。因此,在标签空间中加入一个随机因子,有助于缩小邻近分布与真实分布之间的差距。新的邻域分布 μ ′可用:

其中 τ ~ H 表示诱导到邻域分布中的所有随机因子,实际上包括前面定义的 λ 和 λ。这里的 H 是一个分布,它模拟了图像mixup过程中的随机噪声。将这种随机性引入标签空间验证了作者的观察,即基于mixup的方法应该考虑一定程度的模糊性,因为人类甚至很难估计他们对自己的不确定性有多不确定。
作者应该选择什么样的分布来抽样 λr ? 如上所述,在标签空间中引入随机因子有助于弥合原始邻近分布与真实分布之间的差距。然而,仍然存在一个问题,什么样的 λ 分布可以最大限度地帮助?或者,作者如何抽样λ使邻近分布更接近真分布?在本文中,作者尝试从两种不同的分布——正态分布 N (0,1)和 β 分布 β (α,α)——抽样λ。如下表10所示,作者研究了不同分布下采样λ 时 LUMix 的性能。请注意,Β分布 β (1,1)等同于单位均匀分布 u (0,1)。从下表中,作者得出结论,当λ 从 α = 2的 Β分布中取样时,作者的方法在 top-1精度方面效果最好。研究如何学习样本λ 的分布,以进一步帮助邻近分布获得更好的性能,是未来研究的热点。

二元交叉熵损失的兼容性 由于 Cut-Mix 引入了一个多分类问题,因此利用二元交叉熵(BCE)损失对网络进行监督可能更为合适。BCE 损失并不强迫每个类相互排斥,因此作者不需要重新加权每个类的目标置信度,这避免了如何估计每个类的不确定性的问题。作者在下表11中显示了使用 BCE 损失训练的 DeT-S 的 Top-1准确性,但是发现与在 SoftMax 交叉熵下训练的基线结果相比,它只能获得边际增益。

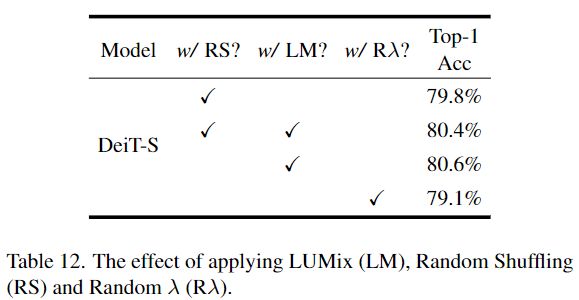
当与 LUMix 相结合,进一步减轻了训练标签的目标置信度时,该模型的表现甚至比基线结果更差。作者认为,与 SoftMax 交叉熵不同,在二元交叉熵中,对目标的正向类加入relaxed总是会导致较弱的惩罚,因为relaxed的目标置信度总是低于其原始值。增加mixup过程的随机性。在前面的章节中,作者已经证明了在标签空间中添加随机噪声可以帮助提高模型的性能。作者想知道是否增加更多的随机性到输入或标签空间可以带来进一步的改进。下表12展示了在输入图像上应用随机洗牌和随机 λ 时的情况。在这里,随机洗牌首先将图像分割成一组16 × 16的patches,然后对mixup图像进行随机洗牌。随机 λ 意味着作者对不同的patch应用不同的mixup比例 λ,每个 λ 都是从原始 Β分布中取样的。下从表12中作者可以得出结论,并非所有的随机性都能带来更好的性能。除了 LUMix 之外,随机洗牌和随机 λ 都会导致 ImageNet 的性能下降。由于随机洗牌和随机 λ 都在输入空间中操作,而 LUMix 在标签空间中执行,因此在标签空间中添加随机性可能更有希望在未来的工作中进行探索。
结论
在本文中,作者观察到基于mixup方法的标签空间应该考虑一定程度的模糊性,因为即使是人类也很难测量他们在估计图像mixup中每个图像的置信度时有多不确定。为了弥补原始伪标签和人工标注过程之间的差距,作者提出了简单地添加两个参数来模拟人工标注的 LUMix。LUMix 非常简单,只需要几行代码就可以实现。广泛的实验证明了 LUMix 的有效性。具体而言,在图像分类方面,LUMix 将 ImageNet-1k 上的 DeT-S 和 XCiT-L 的Top-1准确率分别提高了0.7% 和0.6% 。作者还表明,这种超优先级可以带到下游的任务,如语义分割。
虽然LUMix 是简单而有效的,可以导致许多不同的模型的重大改进。然而,作者承认,LUMix 没有得到任何理论证明的支持。作者做了很多调研来了解背后的原因,但没有一个能得出明确的结论。由于它的简单性和有效性,作者认为 LUMix 即使在没有理论证明的情况下也能在相应的领域引起相当大的关注。
参考
[1] LUMix: Improving Mixup by Better Modelling Label Uncertainty
往期回顾
高精地图新基线 | SuperFusion:多层次Lidar-Camera融合,nuScenes SOTA!
【知识星球】日常干货分享


【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
