Java后端面试准备
自我介绍:
我的学制是两年,目前研一,接下来我列举两个我的项目经历;一个是运行环境智能云平台,技术栈采用spring boot + vue + mybatis 的前后端分离架构,这个项目有两个技术难点,第一个是需要采用分库分表的策略,需要手动编写两个数据库的连接配置;另一个是需要基于位操作来判断出设备的告警情况;另一个项目是大数据文件管理系统,我前期负责基于Ambari + HDP 搭建大数据平台,并制作docker镜像,目前负责springboot与elasticsearch的整合,开发数据智能检索模块;
推荐的笔记
高频问题
- 一致性哈希
零碎问题
- 项目内存或者 cpu 占用率过高如何排查
JVM
jvm
设计模式
更多
什么是单例模式?
答:单例模式是一种常用的软件设计模式,在应用这个模式时,单例对象的类必须保证只有一个实例存在,整个系统只能使用一个对象实例。
优点:不会频繁地创建和销毁对象,浪费系统资源。 使用场景:IO 、数据库连接、Redis 连接等。
什么是简单工厂模式?
答:简单工厂模式又叫静态工厂方法模式,就是建立一个工厂类,对实现了同一接口的一些类进行实例的创建。比如,一台咖啡机就可以理解为一个工厂模式,你只需要按下想喝的咖啡品类的按钮(摩卡或拿铁),它就会给你生产一杯相应的咖啡,你不需要管它内部的具体实现,只要告诉它你的需求即可。
优点:
工厂类含有必要的判断逻辑,可以决定在什么时候创建哪一个产品类的实例,客户端可以免除直接创建产品对象的责任,而仅仅“消费”产品;简单工厂模式通过这种做法实现了对责任的分割,它提供了专门的工厂类用于创建对象;
客户端无须知道所创建的具体产品类的类名,只需要知道具体产品类所对应的参数即可,对于一些复杂的类名,通过简单工厂模式可以减少使用者的记忆量;
通过引入配置文件,可以在不修改任何客户端代码的情况下更换和增加新的具体产品类,在一定程度上提高了系统的灵活性。
缺点:
不易拓展,一旦添加新的产品类型,就不得不修改工厂的创建逻辑;
产品类型较多时,工厂的创建逻辑可能过于复杂,一旦出错可能造成所有产品的创建失败,不利于系统的维护。

Java基础
1.八大基本数据类型
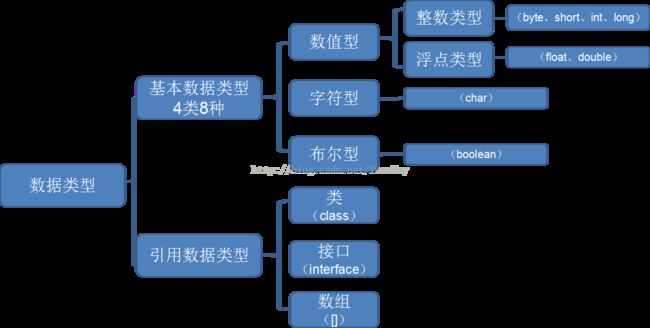
Java中的字符串String属于引用数据类型。因为String是一个类
2.多态:基于对象所属类的不同,外部对同一个方法的调用,实际执行的逻辑不同
父类类型 变量名 = new 子类对象
无法调用子类特有的功能
3.final 关键字
- 修饰类:表示类不可被继承
- 修饰方法:表示方法不可被子类覆盖(重写),但是可以重载(相同的函数名,但是参数个数或类型不同)
- 修饰变量:表示变量一旦被赋值就不可以更改它的值
修饰类变量时,声明的时候就需要赋值,或者静态代码块赋值
final static int a = 0;
static{
a = 1;
}
修饰成员变量的时候,声明的时候就需要赋值,或者代码块中赋值,或者构造器赋值
final int b = 0;
修饰局部变量,程序员必须显示的去进行赋值
4.为什么局部内部类和匿名内部类只能访问局部final变量
内部类和外部类处于同一个级别,内部类不会因为定义在方法中就会随着方法的执行完毕就被销毁,当外部类的方法结束时,局部变量也就销毁了,但是内部类的对象可能还存在。为了解决这个问题,就将局部变量复制了一份作为内部类的成员变量,为了保证两个变量的一致性,就将局部变量设置为final
成员变量:是定义在类中,方法体之外的变量。这种变量在创建对象的时候实例化。成员变量可以被类中方法、构造方法和特定类的语句块访问。
类变量:也声明在类中,方法体之外,但必须声明为static类型。
5.重载和重写的区别
- 重载:发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法的返回值和访问修饰符可以不同,发生在编译时
- 重写:发生在父子类中,方法名、参数列表必须相同,返回值小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private,则子类就不能重写该方法。
6.equals()和 == 的区别
- 出于安全性考虑,equals()更加安全,可以避免空指针异常的问题
- == 比较的是栈中地址值,基本数据类型是变量值,引用类型是堆中内存对象的地址,equals()也是不过可以自己进行重写
7.hashcode与equals
hashcode()的作用是获取哈希码,也称为散列码,哈希码的作用是确定该对象在哈希表中的索引位置,该方法定义在jdk的Object.java中,是一个native本地方法;如何hashcode值不同再去调用equals方法,这样就大大减少了equals的次数
- 如果两个对象相等,则hashcode一定相同。
- 两个对象有相同的hashcode,但是不一定相等
- equals方法被覆盖过,则hashcode方法也必须覆盖
- hashcode的默认行为是对堆上的对象产生独特值,如果没有重写hashcode,则该class的两个对象无论如何都不会相等
8.throw与throws的区别
throw 是语句抛出一个异常,一般是在代码块的内部,当程序出现某种逻辑错误时由程序员主动抛出某种特定类型的异常
当某个方法可能会抛出某种异常时用于throws 声明可能抛出的异常,然后交给上层调用它的方法程序处理
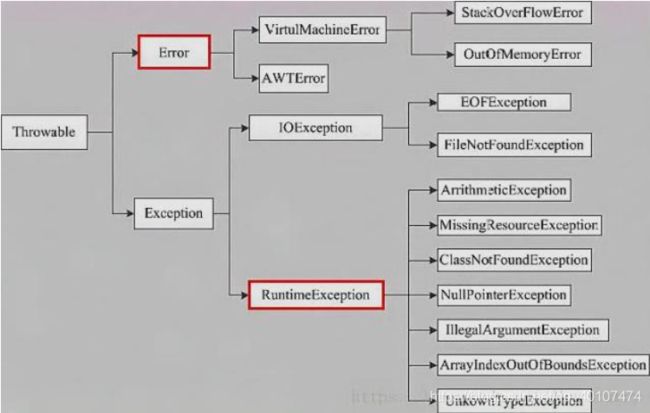
9.抽象方法(is a)与接口(like a)的区别
相同点:
- 抽象方法和接口都不能被实例化,但可以定义抽象类和接口类型的引用。
不同点:
-
一个类继承抽象类需要实现其中的抽象方法,否则该类还是需要被声明为抽象类,当一个类实现了接口,就必须实现其所有方法。
-
抽象类可以存在普通成员函数,而接口中只能存在public abstract方法
-
抽象类只能继承一个,而接口可以实现多个
-
接口相比于抽象类更抽象,抽象类中可以定义构造器,可以有抽象方法和实现方法,接口则没有构造方法,且方法全是抽象方法。
-
接口中的方法默认是public的,抽象类的方法没有限制
-
接口中定义的成员变量实际上都是常量(public static final),抽象类中的成员变量没有限制
-
抽象类不一定要有抽象方法,而有抽象方法的类必须声明为抽象类
-
从设计目的而言,接口的设计目的是对类的行为进行约束,提供一种机制,只约束了行为的有无,但不对如何实现进行行为限制,而抽象类的设计目的,是代码复用,先有子类后有派生的抽象类
10.List和Set的区别
- List:有序,可重复,按对象进入的顺序保存对象,允许多个null元素对象,可以使用迭代器取出所有元素,也可以使用下标
- Set:无序,不可重复,最多允许有一个null元素对象,只能使用迭代器取元素
11.ArrayList和LinkedList的区别
- ArrayList:基于动态数组,连续内存存储,适合下标访问(随机访问),扩容机制:因为数组长度固定,超出长度存数据时需要新建数组,然后将老数组的数据拷贝到新数组,使用尾插法并指定初始容量可以极大提升性能,甚至超过linkedList
- LinkedList:基于链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询
12.IO
NIO与BIO的比较

- BIO以流的方式处理数据,而NIO是以块的方式处理数据,块IO的效率比流IO高很多。
- BIO是阻塞的,NIO是非阻塞的
- BIO是基于字节流和字符流进行操作的,而NIO是基于通道和缓冲区操作的;数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中。Selector用于监听多个通道的事件,因此使用单线程可以监听多个客户端通道
- NIO是jdk1.4引入的一种新的IO,支持面向缓冲区的、基于通道的IO操作。NIO的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞。
- AIO:异步非阻塞,也是nio的改进版。每一个io操作都会有一个回调函数。线程不会去轮询。当某个io需要读取或写入数据时,便会执行回调函数,线程便在此处。
IO多路中的linux函数
select(max+1,读文件描述符集合,写文件描述符集合,异常文件描述符集合,超时时间)
- 会有一个1024位的bitmap去记录文件描述符的状态(rset)
- select将rset从用户态拷贝到内核态
- 有数据的时候FD被置位,select返回
- 缺点:1024位固定大小的bitmap,fdset不可重用,用户态到内核态的开销大,最后需要遍历O(n)
poll(pollfds,元素个数,超时时间)
struct pollfd{
int fd;
short events;
short revents; // 置位在这里,直接修改,解决了bitmap不可重用的问题
}
epoll (redis,nginx,NIO)
- 更加灵活,没有描述符的限制,使用一个文件描述符来管理多个描述符,epfd中有许多fd-events
- epfd是在用户态和内核态共享的
- 置位就是重排,进行返回,返回值为需要处理的个数
多线程
线程池:在一个应用程序中,我们需要多次使用线程,也就意味着,我们需要多次创建并销毁线程。而创建并销毁线程的过程势必会消耗内存。而在Java中,内存资源是及其宝贵的,所以,我们就提出了线程池的概念。
Executors:工具类,线程池的工厂类,用于创建并返回不同类型的线程池
ExecutorService:真正的线程池接口,常见子类ThreadPoolExecutor
ExecutorService是Java提供的用于管理线程池的类。该类的两个作用:控制线程数量和重用线程;具体的4种常用的线程池:
- Executors.newCacheThreadPool():可缓存线程池,先查看池中有没有以前建立的线程,如果有,就直接使用。如果没有,就建一个新的线程加入池中,缓存型池子通常用于执行一些生存期很短的异步型任务
- Executors.newFixedThreadPool(int n):创建一个可重用固定个数的线程池,以共享的无界队列方式来运行这些线程
- Executors.newScheduledThreadPool(int n):创建一个定长线程池,支持定时及周期性任务执行
- Executors.newSingleThreadExecutor():创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
AQS: 队列同步器,是用来构建锁或者其他同步组件的基础框架,它使用了一个int成员变量表示同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。基于volatile和CAS来实现
同步组件利用同步器进行锁的实现,它简化了锁的实现方式,屏蔽了同步状态管理、线程的排队、等待与唤醒等顶层操作,同步器提供了3个方法来修改和访问同步状态:
- getState():获取当前同步状态
- setState(int newState):设置当前同步状态
- compareAndSetState(int expect, int update):使用CAS设置当前状态,该方法能保证操作的原子性。
Runnable和Callable的区别和联系
- 1)Runnable提供run方法,无法通过throws抛出异常,所有CheckedException必须在run方法内部处理。Callable提供call方法,直接抛出Exception异常。
- 2)Runnable的run方法无返回值,Callable的call方法提供返回值用来表示任务运行的结果
- 3)Runnable可以作为Thread构造器的参数,通过开启新的线程来执行,也可以通过线程池来执行。而Callable只能通过线程池执行。
spring
IOC(Inversion Of Controll,控制反转)
是一种设计思想,就是将原本在程序中手动创建对象的控制权,交由给Spring框架来管理。IOC容器是Spring用来实现IOC的载体,IOC容器实际上就是一个Map(key, value),Map中存放的是各种对象。将对象之间的相互依赖关系交给IOC容器来管理,并由IOC容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。IOC容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
AOP(面向切面编程)
AOP(Aspect-Oriented Programming,面向切面编程)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可扩展性和可维护性。Spring AOP是基于动态代理的,如果要代理的对象实现了某个接口,那么Spring AOP就会使用JDK动态代理去创建代理对象;而对于没有实现接口的对象,就无法使用JDK动态代理,转而使用CGlib动态代理生成一个被代理对象的子类来作为代理。
CGLIB是一个强大的、高性能的代码生成库。其被广泛应用于AOP框架(Spring、dynaop)中,用以提供方法拦截操作。CGLIB代理主要通过对字节码的操作,为对象引入间接级别,以控制对象的访问。CGLIB相比于JDK动态代理更加强大,JDK动态代理虽然简单易用,但是其有一个致命缺陷是,只能对接口进行代理。如果要代理的类为一个普通类、没有接口,那么Java动态代理就没法使用了
AOP实现方式:
- 手动方式:spring采用 jdk 的动态代理Proxy
- 半自动方式:让spring 容器创建代理对象,从spring容器中手动的获取代理对象
- 全自动方式:从spring 容器获得目标类,如果配置aop,spring将自动生成代理
- 注解方式:Spring AOP基于注解的“零配置”方式实现
@Autowired 的作用是什么?
- @Autowired 是一个注释,它可以对类成员变量、方法及构造函数进行标注,让 spring 完成 bean 自动装配的工作。
- @Autowired 默认是按照类去匹配,配合 @Qualifier 指定按照名称去装配 bean。
BeanFactory和ApplicationContext有什么区别
- ApplicationContext是BeanFactory的子接口,ApplicationContext提供了更完整的功能,继承MessageSource,因此支持国际化
- 统一的资源文件访问方式
- 提供在监听器中注册bean事件
- 同时加载多个配置文件
- BeanFactory采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时才对该Bean进行实例化加载,而ApplicationContext是在容器启动时一次性创建了所有的Bean
- 相对于基本的BeanFactory,ApplicationContext唯一的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢
- BeanFactory通常以编程的方式创建,ApplicationContext还能以声明的方式创建,如使用ContextLoader
Spring Bean 的生命周期
- 解析类得到BeanDefinition
- 如果有多个构造方法,则要推断构造方法
- 确定好构造方法后,进行实例化得到一个对象
- 对对象中加了@Autowired注解的属性进行属性填充
- 回调Aware方法,比如BeanNameAware,BeanFactoryAware
- 调用BeanPostProcessor的初始化前的方法
- 调用初始化方法
- 调用BeanPostProcessor的初始化后的方法,在这里会进行AOP
- 如果当前创建的bean是单例的则会把bean放入单例池
- 使用bean
- spring容器关闭时调用DisposableBean中的destroy方法
Spring中的bean的作用域有哪些
- singleton:唯一bean实例,Spring中的bean默认都是单例的。
- prototype:每次请求都会创建一个新的bean实例。在每次注入时都会创建一个新的对象,
- request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。
- session:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP session内有效。
- application:bean被定义为在ServletContext的生命周期中,复用一个单例对象
SpringMVC工作原理
流程说明:
- 客户端(浏览器)发送请求,直接请求到DispatcherServlet。
- DispatcherServlet根据请求信息调用HandlerMapping,解析请求对应的Handler。
- 解析到对应的Handler(也就是我们平常说的Controller控制器)。
- HandlerAdapter会根据Handler来调用真正的处理器来处理请求和执行相对应的业务逻辑。
- 处理器处理完业务后,会返回一个ModelAndView对象,Model是返回的数据对象,View是逻辑上的View。
- ViewResolver会根据逻辑View去查找实际的View。
- DispatcherServlet把返回的Model传给View(视图渲染)。
- 把View返回给请求者(浏览器)。
如何实现一个IOC容器
- 配置文件、配置包扫描路径
- 递归包扫描获取.class文件
- 使用反射确定需要交给IOC管理的类
- 对需要注入的类进行依赖注入
spring boot的自动装配
数据库
数据库的四种隔离级别
- 读未提交:一个事务可以读取另一个未提交事务的数据
- 读提交:一个事务要等另一个事务提交后才能读取数据,解决脏读,大部分数据库采用这个
- 重复读:开始读取数据时,不再允许修改操作,解决不可重复读
- 序列化:事务串行化顺序执行,可以避免脏读、不可重复读、幻读
事务
- 原子性(Atomicity):原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency):事务前后数据的完整性必须保持一致。
- 隔离性(Isolation):事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
- 持久性(Durability):持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
B树和B+树
b-树的特点:
M为树的阶数,B-树或为空树,否则满足下列条件:
- 非叶子结点最多只有M个子节点;且M>2;
- 根结点的子节点数为[2, M];
- 除根结点以外的非叶子结点的子节点数为[M/2, M];
- 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字,根节点至少一个关键字);
b+树常应用于数据库和操作系统的文件系统中,不同点在于
- 关键字的数量不同,b+树有m个关键字,也有m个叶子节点。关键字只是用来存储索引。B树虽然也有m个子结点,但是其只拥有m-1个关键字。
- 存储的位置不同;B+树中的数据都存储在叶子结点上,也就是其所有叶子结点的数据组合起来就是完整的数据,但是B树的数据存储在每一个结点中,并不仅仅存储在叶子结点上。
- 分支结点的构造不同;B+树的分支结点仅仅存储着关键字信息和儿子的指针(这里的指针指的是磁盘块的偏移量),也就是说内部结点仅仅包含着索引信息。
- 查询不同;B树在找到具体的数值以后,则结束,而B+树则需要通过索引找到叶子结点中的数据才结束,也就是说B+树的搜索过程中走了一条从根结点到叶子结点的路径。
为什么说B+树比B 树更适合实际应用中操作系统的文件索引和数据库索引?
- B+树的磁盘读写代价更低:B+树没有指向关键字具体信息的指针。因此其内部结点相对B 树更小,次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了
- B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
计算机网络
OSI体系结构
- 物理层、数据链路层、网络层、运输层、 会话层、表示层、应用层
网络层知识点
网际协议IP:
1.地址解析协议ARP:是解决同一个局域网上的主机或路由器的IP地址和硬件地址的映射问题。
2.逆地址解析协议RARP:是解决同一个局域网上的主机或路由器的硬件地址和IP地址的映射问题。
3.网际控制报文协议ICMP:提供差错报告和询问报文,以提高IP数据交付成功的机会
4.网际组管理协议IGMP::用于探寻、转发本局域网内的组成员关系。
数据链路层——流量控制与可靠传输
停止-等待协议
(滑动窗口
后退N帧协议(GBN)
- 累计确认、接收方只按序接受、发送窗口为2的n次方-1,接受窗口为1
选择重传协议(SR)
- 对数据帧逐一确认、只重传出错帧、接收方有缓存
运输层知识点
用户数据报协议 UDP(User Datagram Protocol)
- UDP 是无连接的,即发送数据之前不需要建立连接。
- UDP 使用尽最大努力交付,即不保证可靠交付,同时也不使用拥塞控制
- UDP 是面向报文的
- UDP 支持一对一、一对多、多对一和多对多的交互通信
- UDP 的首部开销小,只有 8 个字节
传输控制协议 TCP(Transmission Control Protocol) - TCP 是面向连接的运输层协议
- 每一条 TCP 连接只能有两个端点(endpoint),每一条 TCP 连接只能是点对点的(一对一)
- TCP 提供可靠交付的服务
- TCP 提供全双工通信
- 面向字节流
三次握手 防止SYN洪泛攻击
- 第一次握手:主机 A 发送位码为 syn= 1,随机产生 seq number=1234567 的数据包到服务器,主机 B
由 SYN=1 知道, A 要求建立联机; - 第 二 次 握 手 : 主 机 B 收 到 请 求 后 要 确 认 联 机 信 息 , 向 A 发 送 ack number=( 主 机 A 的
seq+1),syn=1,ack=1,随机产生 seq=7654321 的包 - 第三次握手: 主机 A 收到后检查 ack number 是否正确,即第一次发送的 seq number+1,以及位码
ack 是否为 1,若正确, 主机 A 会再发送 ack number=(主机 B 的 seq+1),ack=1,主机 B 收到后确认
四次握手
- 1) 关闭客户端到服务器的连接:首先客户端 A 发送一个 FIN,用来关闭客户到服务器的数据传送,
然后等待服务器的确认。其中终止标志位 FIN=1,序列号 seq=u - 2) 服务器收到这个 FIN,它发回一个 ACK,确认号 ack 为收到的序号加 1。
- 3) 关闭服务器到客户端的连接:也是发送一个 FIN 给客户端。
- 4) 客户段收到 FIN 后,并发回一个 ACK 报文确认,并将确认序号 seq 设置为收到序号加 1。
首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
TCP可靠传输 快速重传
TCP是面向字节的,对每个字节进行编号,但并不是接收到每个字节都要发回确认,而是在发送一个报文段字节后才发回一个确认,所以TCP采用的是对报文段的确认机制。
流量控制:
TCP利用滑动窗口机制实现流量控制;如果滑动窗口值设置太小,会产生过多的ACK,如果过大,会由于传送的数据过多而使路由器变得拥挤,导致主机可能丢失分组。
- 1.发送端和接收端分别设定发送窗口和接收窗口。
- 2.三次握手的时候,客户端把自己的缓冲区大小也就是窗口大小发送给服务器,服务器回应是也将窗口大小发送给客户端,服务器客户端都知道了彼此的窗口大小。
- 3.比如主机A的发送窗口大小为5,主机A可以向主机B发送5个单元,如果B缓冲区满了,A就要等待B确认才能继续发送数据。
- 4.如果缓冲区中有1个报文被进程读取,主机B就会回复ACK给主机A,接收窗口向前滑动,报文中窗口大小为1,就说明A还可以发送1个单元的数据,发送窗口向前滑动,之后等待主机B的确认报文。
只有接收窗口向前滑动并发送了确认时,发送窗口才能向前滑动。
拥塞控制与流量控制的区别:
拥塞控制是让网络能够承受现有的网络的负荷,它是一个全局性的过程,涉及所有的主机、所有的路由器,以及与降低网络性能相关的所有因素。
流量控制往往是指点对点的通信量的控制,即接收端控制发送端,它所要做的是抑制发送端发送数据的速率,以便接收端来得及接收。
拥塞控制的四种算法:慢开始和拥塞避免、快重传和快恢复
应用层知识点
域名解析(dns)
- 递归查询(靠别人,本地域名服务器>根域名服务器>顶级域名服务器>权限域名服务器
- 递归与迭代相结合的查询(靠自己,本地域名服务器
Https和Http区别
WEB服务存在http和https两种通信方式,http默认采用80作为通讯端口,对于传输采用不加密的方式,https默认采用443,对于传输的数据进行加密传输;https=http+ssl,顾名思义,https是在http的基础上加上了SSL保护壳,信息的加密过程就是在SSL中完成的
对称加密与非对称加密
对称加密:只要A和B之间知道加解密的秘钥,任何第三方都无法获取秘钥S,采用对称加密进行通信存在秘钥协商过程的不安全性
非对称加密:私钥加密后的密文,只要是公钥,都可以解密,但是反过来公钥加密后的密文,只有私钥可以解密。私钥只有一个人有,而公钥可以发给所有的人。