cbow和skip-gram实现关键代码解析
源码地址: https://github.com/AlbertBJ/word2vecpy.git
这也是 我 fork别人的,觉得写得很棒,所以拜读了大神的代码,先对 关键点 进行说明:
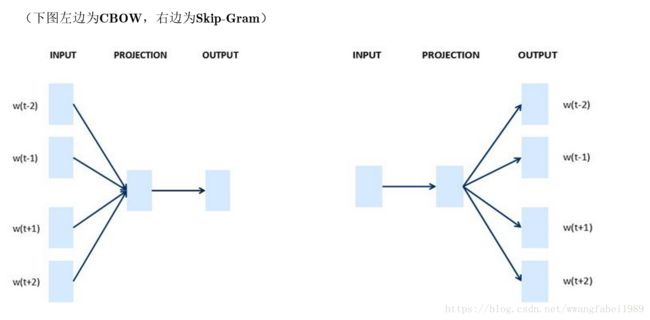
主要是 针对 train_process这个方法中 针对 负采样 计算方法:
# Randomize window size, where win is the max window size
# 下面4行代码,主要是 获得 目标词 的上下文词(滑动窗口大小为win,即获取 目标词 的 左右各 win各词)
current_win = np.random.randint(low=1, high=win+1)# 主要是利用随机的思想,每次都产生 上下文词 的 数量 为[1,win]
context_start = max(sent_pos - current_win, 0)# 这一步骤 主要是 针对 刚开始 的目标词 左边(以字典 索引,小于目标词索引的为左边,大于的 # 为右边)不足以 产生 current_win个 上下文,即 当不足时,上下文索引 从 0开始计算
context_end = min(sent_pos + current_win + 1, len(sent)) # 这一步 和上一步 目的一致,主要是 针对 目标词 右侧 不足以 产生current_win个上 # 下文
context = sent[context_start:sent_pos] + sent[sent_pos+1:context_end] # Turn into an iterator? 这一步 主要是 产生 上下文列表
# CBOW
if cbow:
# Compute neu1
neu1 = np.mean(np.array([syn0[c] for c in context]), axis=0) # 获得词嵌入向量,在此处 体现 cbow和skip-gram不同点,cbow是用周边上下文词求平均后,
# 再进行 与 目标词的 dot(此时的 目标词 包括 正样本以及负样本)
assert len(neu1) == dim, 'neu1 and dim do not agree'
# Init neu1e with zeros
neu1e = np.zeros(dim)
# Compute neu1e and update syn1 syn1为辅助向量
if neg > 0:
classifiers = [(token, 1)] + [(target, 0) for target in table.sample(neg)]
else:
classifiers = zip(vocab[token].path, vocab[token].code)
for target, label in classifiers:
z = np.dot(neu1, syn1[target]) # 利用平均后的上下文词 词向量 与 每一个 目标词 进行 dot ,syn1存储的是每个词的模型参数
p = sigmoid(z)
g = alpha * (label - p) # 计算二分类的梯度(z的梯度是label-p,具体推导可以看我的 一篇关于bp的博文)
neu1e += g * syn1[target] # 此处使用梯度上升方法,目的求得 概率最大化(g*syn1[target],更新embedding)
syn1[target] += g * neu1 # 利用梯度上升 更新 模型参数(g * neu1更新参数矩阵)
# Update syn0
for context_word in context: #更新 每一个 上下文对应 的词向量矩阵
syn0[context_word] += neu1e # 利用梯度 上升更新 词嵌入矩阵
# Skip-gram
else:
for context_word in context: # 循环上下文 词的个数
# Init neu1e with zeros
neu1e = np.zeros(dim)
# Compute neu1e and update syn1
if neg > 0:
classifiers = [(token, 1)] + [(target, 0) for target in table.sample(neg)]
else:
classifiers = zip(vocab[token].path, vocab[token].code)
for target, label in classifiers:
z = np.dot(syn0[context_word], syn1[target])
p = sigmoid(z)
g = alpha * (label - p)
neu1e += g * syn1[target] # Error to backpropagate to syn0
syn1[target] += g * syn0[context_word] # Update syn1 使用 上下文更新 syn1
# Update syn0
syn0[context_word] += neu1e
知乎: https://zhuanlan.zhihu.com/albertwang
微信公众号:AI-Research-Studio

