NLP-预训练模型-201806-NLG:GPT-1【Decoder of Transformer】【预训练:GPT使用单向语言模型;Fine-tuning:GPT、Task的参数一起训练】
预训练模型(Pretrained model):一般情况下预训练模型都是大型模型,具备复杂的网络结构,众多的参数量,以及在足够大的数据集下进行训练而产生的模型.
在NLP领域,预训练模型往往是语言模型,因为语言模型的训练是无监督的,可以获得大规模语料,同时语言模型又是许多典型NLP任务的基础,如机器翻译,文本生成,阅读理解等,常见的预训练模型有BERT, GPT, roBERTa, transformer-XL等.
OpenAI GPT 是在 Google BERT 算法之前提出的,与 BERT 最大的区别在于,
- GPT 采用了传统的语言模型进行训练,即使用单词的上文预测单词,
- BERT 是同时使用上文和下文预测单词。
- 因此,GPT 更擅长处理自然语言生成任务 (NLG),而 BERT 更擅长处理自然语言理解任务 (NLU)。
OpenAI 在论文《Improving Language Understanding by Generative Pre-Training》中提出了 GPT 模型,后面又在论文《Language Models are Unsupervised Multitask Learners》提出了 GPT2 模型。GPT2 与 GPT 的模型结构差别不大,但是采用了更大的数据集进行实验。
GPT 与 BERT 都采用 Transformer 模型
- GPT采用了Transformer 模型的Decoder部分;
- BERT采用了Transformer 模型的Encoder部分;
一、 GPT概述(Generative Pre-Training)【Decoder of Transformer】
一句话简介:GPT是2018年发掘的自回归模型,采用预训练和下游微调方式处理NLP任务;解决动态语义问题,word embedding 送入单向transformer中。
目前大多数深度学习方法依靠大量的人工标注信息,这限制了在很多领域的应用。此外,即使在可获得相当大的监督语料情况下,以无监督学习的方式学到的表示也可以提供显着的性能提升。到目前为止,最引人注目的证据是广泛使用预训练词嵌入来提高一系列NLP任务的性能。

GPT主要出论文《Improving Language Understanding by Generative Pre-Training》,GPT 是"Generative Pre-Training"的简称,从名字看其含义是指的生成式的预训练。
Transformer是一类可迁移到多种NLP任务的,基于Transformer的语言模型,GPT利用Transformer的结构来进行单向语言模型的训练。
GPT的基本思想同ULMFiT相同,都是在尽量不改变模型结构的情况下将预训练的语言模型应用到各种任务。不同的是:
- GPT主张用Transformer结构;
- 而ULMFiT中使用的是基于RNN的语言模型;
1、GPT在各个任务上的表现
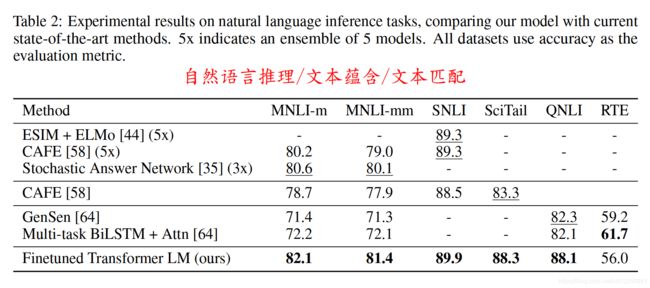

在GPT出来之时:效果是非常令人惊艳的,在 12 个任务里,9 个达到了最好的效果,有些任务性能提升非常明显。
2、ELMo/GPT/BERT 对比

- GPT其实跟ELMO非常相似,只是把语言模型直接迁移到具体的NLP任务中,因此,更容易进行迁移学习。
- GPT主要还是针对文本分类和标注性任务,如果对于生成任务,比如机器翻译等,则其结构也没法进行很好的迁移。
- 例如给定一个句子 [ u 1 , u 2 , . . . , u n ] [u_1, u_2, ..., u_n] [u1,u2,...,un],GPT 在预测单词 u i u_i ui 的时候只会利用 [ u 1 , u 2 , . . . , u ( i − 1 ) ] [u_1, u_2, ..., u_{(i-1)}] [u1,u2,...,u(i−1)] 的信息,而 BERT 会同时利用 [ u 1 , u 2 , . . . , u ( i − 1 ) , u ( i + 1 ) , . . . , u n ] [u_1, u_2, ..., u_{(i-1)}, u_{(i+1)}, ..., u_n] [u1,u2,...,u(i−1),u(i+1),...,un] 的信息。
- GPT 因为采用了传统语言模型所以更加适合用于自然语言生成类的任务 (NLG),因为这些任务通常是根据当前信息生成下一刻的信息。而 BERT 更适合用于自然语言理解任务 (NLU)。
- GPT 采用了 Transformer 的 Decoder,而 BERT 采用了 Transformer 的 Encoder。
- GPT如何实现单向语言模型:GPT 使用 Decoder 中的 Mask Multi-Head Attention 结构,在使用 [ u 1 , u 2 , . . . , u ( i − 1 ) ] [u_1, u_2, ..., u_{(i-1)}] [u1,u2,...,u(i−1)] 预测单词 u i u_i ui 的时候,会将 u i u_i ui 之后的单词 Mask 掉。
- GPT 预训练时利用上文预测下一个单词,BERT 是根据上下文预测单词,因此在很多 NLU 任务上,GPT 的效果都比 BERT 要差。但是 GPT 更加适合用于文本生成的任务,因为文本生成通常都是基于当前已有的信息,生成下一个单词。
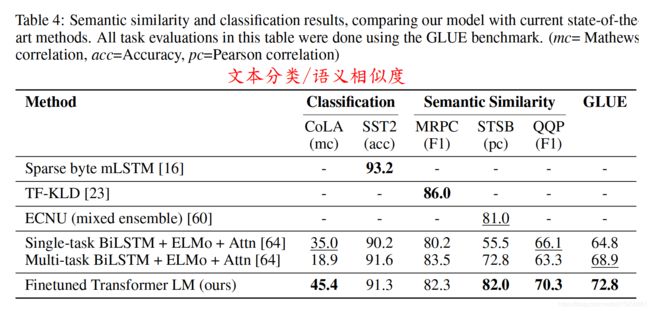
3、GPT 缺点
GPT 因为采用了传统自回归的语言模型,根据当前信息生成下一刻的信息。
- 给定一个句子 [ u 1 , u 2 , . . . , u n ] [u_1, u_2, ..., u_n] [u1,u2,...,un],GPT 在预测单词 u i u_i ui 的时候只会利用 [ u 1 , u 2 , . . . , u ( i − 1 ) ] [u_1, u_2, ..., u_{(i-1)}] [u1,u2,...,u(i−1)] 的信息,无法利用 [ u ( i + 1 ) , u ( i + 2 ) , . . . , u n ] [u_{(i+1)},u_{(i+2)}, ..., u_n] [u(i+1),u(i+2),...,un]的信息;
- 也就是说GPT无法利用全局信息;
- 所以GPT 更加适合用于文本生成的任务,因为文本生成通常都是基于当前已有的信息,生成下一个单词。
4、GPT的历史意义
虽然GPT在NLP 下游任务中表现的情况没有 Bert 模型好,但是在文本生成任务上表现出色。
二、GPT模型结构
GPT模型主要包含两个阶段:
- 第一个阶段,先利用大量未标注的语料预训练一个语言模型(无监督形式);
- 第二个阶段,根据具体的下游任务,例如 QA,文本分类等对模型进行微调,将其迁移到各种有监督的NLP任务,并对参数进行fine-tuning(监督模式);
1、第一阶段:GPT模型预训练(无监督)
1.1 Transformer总体架构
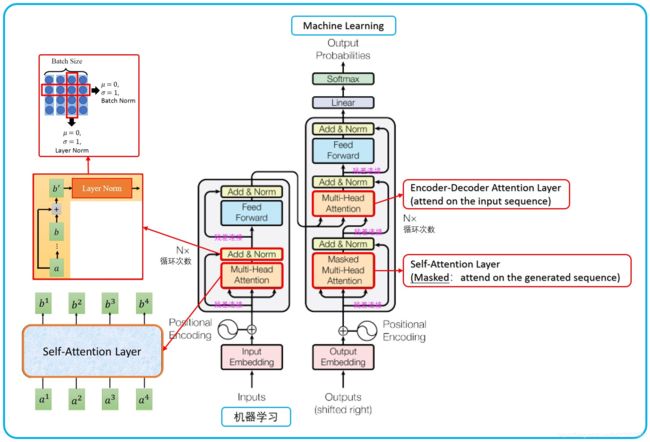
1.2 GPT 对 Transformer Decoder结构的改动
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,
- 原本的 Decoder 包含了一个 Multi-Head Attention 结构,一个 Masked Multi-Head Attention 结构
- GPT 只保留了 Masked Multi-Head Attention,如下图所示。

1.3 GPT 预训练
GPT 预训练的方式和传统的语言模型一样,通过上文,预测下一个单词;GPT 预训练的方式是使用 Mask LM。
给定一个没有标注的大语料,记每一个序列为 U = { u 1 , … , u n } \mathcal{U}=\left\{u_{1}, \dots, u_{n}\right\} U={u1,…,un},GPT通过最大化以下似然函数来训练语言模型:

- k k k 表示上下文窗口的大小,这里计算每个单词的预测概率时,只考虑左侧窗口大小的词汇信息;
- Θ Θ Θ 是 Nerual Network 的参数【下面式子中的 W e W_{e} We、 W p W_{p} Wp、以及Transformer Decoder结构中的参数】;
在GPT中,作者采用的是一个12层的Transformer Decoder作为语言模型的结构,其计算过程如下:
h 0 = U W e + W p 【 W o r d E m b e d d i n g 层 】 h l = t r a n s f o r m e r b l o c k ( h l − 1 ) ∀ l ∈ [ 1 , n ] 【 T r a n s f o r m e r D e c o d e r 层 】 P ( u ) = s o f t m a x ( h n W e T ) 【 线 性 层 + S o f t m a x 】 \begin{aligned} &h_0=UW_e+W_p \quad 【Word\ Embedding 层】 \\ &h_l=transformer_block(h_{l-1}) \quad ∀\ l ∈ [1, n] \quad 【Transformer\ Decoder 层】\\ &P(u)=softmax(h_nW_e^T) \quad 【线性层+Softmax】 \end{aligned} h0=UWe+Wp【Word Embedding层】hl=transformerblock(hl−1)∀ l∈[1,n]【Transformer Decoder层】P(u)=softmax(hnWeT)【线性层+Softmax】
- h 0 h_0 h0 代表 将要喂给 G P T GPT GPT 模型的 目标词汇的左侧窗口的句子序列的 Embedding(其中的参数 W e W_{e} We、 W p W_{p} Wp是模型要训练的参数);
- U = ( u i − k , … , u i − 1 ) U=\left(u_{i-k}, \ldots, u_{i-1}\right) U=(ui−k,…,ui−1) 表示目标词汇的左侧窗口的句子序列(词汇 t o k e n token token 序列集合);
- W e W_{e} We 表示 t o k e n token token 的 embedding矩阵;
- W p W_{p} Wp 表示 p o s i t i o n position position 的 embedding矩阵,在GPT中,作者对position embedding矩阵进行随机初始化,并让模型自己学习,而不是采用正弦余弦函数进行计算;
- n n n 表示Transformer的层数;
- Word Embedding 层的 W e W_{e} We 与 最后的 线性层的 W e T W_{e}^T WeT 设置为一样,减少模型参数量;
从GPT的计算公式来看,其实跟Transformer基本是一样的,只是对每个时间步,都只考虑左侧窗口大小的上下文信息。
1.4 GPT 中的 Mask
GPT 使用句子序列预测下一个单词,因此要采用 Mask Multi-Head Attention 对单词的下文遮挡,防止信息泄露。
例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。则预测 B 的时候,需要将 [B, C, D] Mask 起来。
Mask 操作是在 Self-Attention 进行 Softmax 之前进行的,具体做法是将要 Mask 的位置用一个无穷小的数替换 -inf,然后再 Softmax,如下图所示。
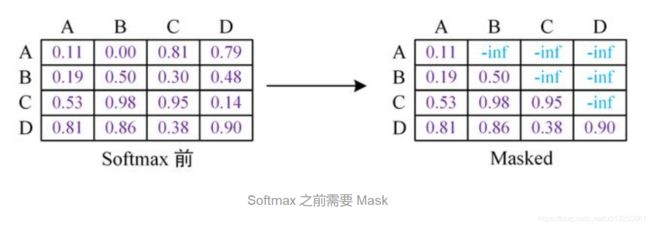
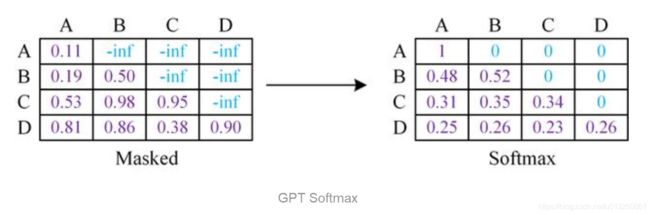
可以看到,经过 Mask 和 Softmax 之后,当 GPT 根据单词 A 预测单词 B 时,只能使用单词 A 的信息,根据 [A, B] 预测单词 C 时只能使用单词 A, B 的信息。这样就可以防止信息泄露。
1.5 ELMo与GPT区别
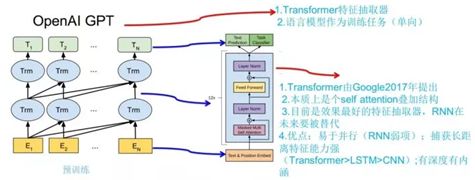
上图展示了 GPT 的预训练过程,其实和 ELMO 是类似的,主要不同在于两点:
- 特征抽取器不是用的 RNN/LSTM,而是用的 Transformer,上面提到过它的特征抽取能力要强于 RNN/LSTM,这个选择很明显是很明智的;
- ELMO使用上下文对单词进行预测,而 GPT 则只采用 Context-before 这个单词的上文来进行预测,而抛开了下文。
2、第二阶段:Fine-tuning(有监督)【语言模型GPT的参数不固定,依然是需要训练来微调的】
上面讲的是 GPT 如何进行第一阶段的预训练,那么假设预训练好了网络模型,后面下游任务怎么用?
当语言模型训练结束后,就可以将其迁移到具体的NLP任务中,假设将其迁移到一个文本分类任务中,记此时的数据集为 C \mathcal{C} C,对于每一个样本,其输入为 x 1 , … , x m x^{1}, \ldots, x^{m} x1,…,xm,输出为 y y y。
2.1 通过 “GPT预训练模型” 获取当前任务输入token序列的词向量
对于每一个输入,经过预训练后的语言模型 G P T GPT GPT 后,可以直接选取最后一层Transformer最后一个时间步的输出向量 h l m h_{l}^{m} hlm,
h l m = G P T ( x 1 , … , x m ) h_{l}^{m}=GPT(x^{1}, \ldots, x^{m}) hlm=GPT(x1,…,xm)
2.2 将当前任务输入token序列通过 GPT 获取的词向量送入下游任务
然后在其后面接一层全连接层,即可得到最后的预测标签概率:

其中, W y W_{y} Wy 为新引入的全连接层的参数矩阵。因此,可以得到在分类任务中的目标函数:
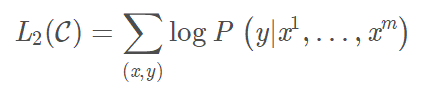
2.3 联合训练(Fine-tuning):“GPT预训练模型” + “下游模型”
在具体的NLP任务中,作者在fine-tuning时也把语言模型的目标引入到目标函数中,作为辅助函数,作者发现这样操作可以提高模型的通用能力,并且加速模型收敛,其形式如下:
![]()
其中, λ λ λ 一般取0.5。
可以发现,在fine-tuning阶段,此时新增的参数只有最后一层全连接层的参数 W y W_{y} Wy,这比ELMo算法要容易得多。
2.4 GPT预训练模型用于不同下游任务时的处理方式
不过,上面这个例子只是对于文本分类任务,如果是对于其他任务,比如文本蕴涵、问答、文本相似度等,那么GPT该如何进行微改呢?针对这几种情况,作者提出了以下的修改方法:
- 文本蕴涵:对于文本蕴涵任务,作者用一个“$”符号将文本和假设进行拼接,并在拼接后的文本前后加入开始符“start”和结束符“end”,然后将拼接后的文本直接传入预训练的语言模型,在模型再接一层线性变换和softmax即可。
- 文本相似度:对于文本相似度任务,由于相似度不需要考虑两个句子的顺序关系,因此,为了反映这一点,作者将两个句子分别与另一个句子进行拼接,中间用“$”进行隔开,并且前后还是加上起始和结束符,然后分别将拼接后的两个长句子传入Transformer,最后分别得到两个句子的向量表示 h l m h_{l}^{m} hlm,将这两个向量进行元素相加,然后再接如线性层和softmax层。
- 问答和常识推理:对于问答和常识推理任务,首先将背景信息与问题进行拼接,然后再将拼接后的文本依次与每个答案进行拼接,最后依次传入Transformer模型,最后接一层线性层得多每个输入的预测值。
具体的方法可以查看下图,可以发现,对这些任务的微改主要是新增线性层的参数以及起始符、结束符和分隔符三种特殊符号的向量参数。

GPT 论文给了一个改造施工图如上:
- 对于分类问题,不用怎么动,加上一个起始和终结符号即可;
- 对于句子关系判断问题,比如 Entailment,两个句子中间再加个分隔符即可;
- 对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;
- 对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。从上图可看出,这种改造还是很方便的,不同任务只需要在输入部分施工即可。
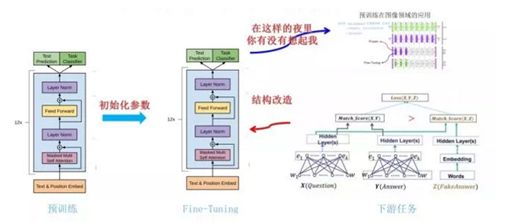
上图展示了 GPT 在第二阶段如何使用。
- 对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向 GPT 的网络结构看齐,把任务的网络结构改造成和 GPT 的网络结构是一样的。
- 在做下游任务的时候,利用第一步预训练好的参数初始化 GPT 的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了,这是个非常好的事情。再次,你可以用手头的任务去训练这个网络,对网络参数进行 Fine-tuning,【类似图像领域预训练的过程】
三、GPT-2【GPT升级版】
去掉了Fine-tuning层,模型会自动识别出任务类型;增加了数据集;增加了网络参数;调整了结构
四、GPT-3【GPT升级版】
参考资料:
原始论文:Improving Language Understanding by Generative Pre-Training
GPT原理介绍
自然语言处理中的语言模型预训练方法(ELMo、GPT和BERT)
OpenAI GPT 和 GPT2 模型详解
【NLP-14】GPT模型(Generative Pre-Training)
图解GPT-2(**)!
GPT-2
The Illustrated GPT-2 (Visualizing Transformer Language Models)
图解GPT-2(**)!
NLP: GPT模型和GPT2.0模型
上车!带你一文了解GPT-2模型(transformer语言模型可视化)
GPT-2通俗详解