图形驱动软件栈
图形驱动软件栈
HINZER,2022年,我在北京。芯片设计行业,GPU 固件和驱动开发,对嵌入式系统感兴趣。
1 说明背景
1.1 近来想法
做了一段时间的 GPU 固件和驱动开发,加上平时学习的一些零散的知识,最近打算整理,将这些做成一页文章。
- 梳理 GPU 的知识大纲(对标 GPU入门工程师)
- 了解 GPU 硬件工作机理
- 掌握 GPU 固件工作机理(对标 GPU固件工程师)
- 了解 GPU 驱动 和 GPU 固件的交互接口
- 掌握 GPU 驱动工作机理(对标 GPU驱动工程师)
- 了解 GPU 驱动 和 LIBDRM 的交互接口
1.2 几个概念
梳理的过程中遇到了几个术语,感觉还挺重要(因为自己之前经常混淆概念),也记录下。
1)GUI 和 多媒体: GUI 是图形用户界面(区别 TUI ,文本用户界面),它允许用户通过图标和音频与电子设备进行交互,多媒体 是 GUI 界面一部分内容。参考 wikipedia - Graphical_user_interface
2)图形和图像: 图形是计算机绘制而成的图像,图像是事物的视觉表示。例如,鼠标光标和菜单栏是图形,而摄像头采集的照片和视频是图像。参考 wikipedia - Graphics
3)合成和显示: 合成是(应用程序)将各个 buffer 数据合成一帧,然后写到 Frame Buffer,显示(驱动程序)是将 Frame Buffer 中的数据送往显示,刷新到屏幕。
2 全局视角
2.1 应用场景(了解)
GPU 作为加速图形绘制的芯片时,它主要面向的产品主要是会集中在 PC 和游戏两个市场。
2.2 大概原理(了解)
GPU 是加速绘图的处理器,关于它如何绘制一张图片。这里引入《说透芯片》中的一段文字:
在 GPU 处理图像,特别是 3D 图像的时候,倒不是一个像素一个像素处理的,而是把 3D 图形转换成可以在 2D 屏幕上展现出来的,由顶点构成的无数个三角形。然后,根据每个三角形的三个顶点,把这个三角形所覆盖区域换算成像素,然后再做颜色效果,基本上就得到了屏幕上的最终效果。下面是用 GPU 处理一个 3D 桌子图像的绘制示意图,你大概可以理解这个处理过程。

图片来源:https://static001.geekbang.org/resource/image/3d/76/3d0202b2d306e9dyyfeb3041f41a5276.jpeg
2.3 技术图景(了解)
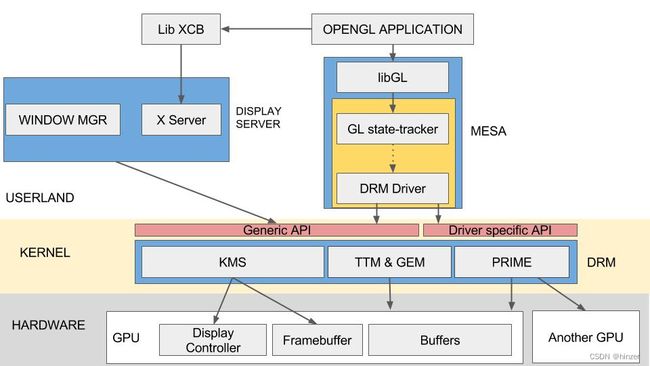
图片来源:https://www.studiopixl.com/assets/posts/2017-linux-stack.jpg
描述计算机在做图形渲染和图形显示的软件构图,这就提供了大概的技术图景,以下总结的技术栈有:
1)工具软件
- 编译器,例如 LLVM
- 调试器
2)系统开发
- 用户态驱动,例如 Xserver/Wayland
- 图形库,例如 Mesa3d
- 内核态驱动,例如 DRM
- 固件,例如 RTOS
3)硬件组成
- 命令处理器(Command Processor)
- 数据并行处理器(Data-Parallel Processor)
- 内存控制器(Memory Controller)
3 用户空间
3.1 OpenGL 和 libGL(了解)
一个简单的 OpenGL 应用程序,主要有三个步骤:创建窗户,准备顶点等数据,开始渲染。
int main(int argc, char** argv)
{
glutInit(&argc, argv);
glutInitWindowSize(300, 300);
glutCreateWindow("Hello world :D");
glClear(GL_COLOR_BUFFER_BIT);
glBegin(GL_TRIANGLE);
glVertex3f(0.0, 0.0, 0.0);
glVertex3f(0.5, 0.0, 0.0);
glVertex3f(0.0, 0.5, 0.0);
glEnd();
glFlush();
return 0;
}
当我们的 OpenGL 应用程序在 X11 环境中运行时,它将其图形输出到 X 服务器分配的窗口。而 3D 应用程序通过 libGL 调用 OpenGL 接口执行 3D 图形的渲染任务。
3.2 libXCB 和 XServer(了解)
Xserver 是显示服务器,它是一个真实的 Server,图形应用必须先连接到它才能发起请求,例如 创建一个窗口。
3.3 libGL 和 Mesa(了解)
3D 应用程序调用 OpenGL 接口,然后呢? 进入 Mesa 层的实现。首先认识 Mesa 是什么。简言之,Mesa 是对 OpenGL 规范的一个开源实现,而基于 OpenGL 的程序用于做 3D 图形的渲染。此外,Mesa 直接和底层的图形硬件进行交互,提供一种 3D 图形的硬件加速方案。
然后第二个问题,Mesa 如何进行图形渲染?通过 Shader 进行 GPU 指令处理和优化。简言之,Shader 是一段最终可以被 GPU 执行的程序,这段程序会参与图形渲染管线的过程,最终是在屏幕上看到的是图形和特效。参考 wikipedia - Shader
然后第三个问题,Mesa 如何处理 Shader 程序?Shader 是 GLSL 程序,经过 OpenGL 状态跟踪器转换成 TGSI 语言,经过 GPU 层转换成为 IR 指令。最终被 GPU 后端(JIT)即时翻译为平台指令。大致工作如下:
- OpenGL 状态跟踪器: 着色器被编译到 TGSI 并进行优化
- GPU 层: 把 TGSI 着色器转换成 GPU 可以理解的指令
- libDRM 和 WinSys: 我们使用这个接口将这些数据发送到内核
4 用户和内核
DRM 是目前 Linux 的主流图形显示框架。DRM 层为图形驱动提供了不同的服务,通过 libdrm 提供的应用程序接口驱动这些服务,libdrm 是包装大多数DRM ioctl 的库。这些服务包括 vblank 事件处理、内存管理、输出管理、帧缓冲区管理、命令提交和保护、挂起/恢复支持和 DMA 服务。参考 内核官方文档。
4.1 软件构图(了解)

图片来源:https://en.wikipedia.org/wiki/Direct_Rendering_Manager#/media/File:DRM_architecture.svg
其实从软件构图中,就可以进一步理解 DRM框架 的三个部分:
- libdrm: 对 DRM 框架的接口封装,向上层提供通用的API接口
- KMS: Kernel Mode Setting。主要体现更新画面和设置显示参数两个方面
- GEM: Graphic Execution Manager。提供内存管理方法,主要负责显示buffer的分配和释放。
4.2 驱动视角(待掌握)
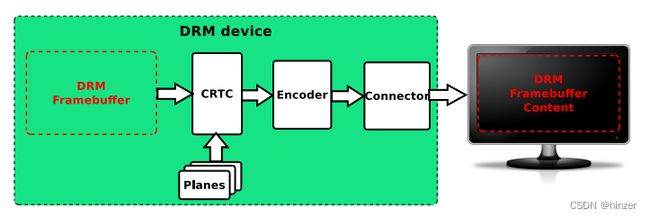
图片来源:https://events.static.linuxfound.org/sites/events/files/slides/brezillon-drm-kms.pdf
- Framebuffer: 单个图层的显示内容,唯一一个和硬件无关的基本元素
- PLANE: 硬件图层,有的Display硬件支持多层合成显示,但所有的Display Controller至少要有1个plane
- CRTC: 对显示buffer进行扫描,并产生时序信号的硬件模块,通常指Display Controller
- Encoder: 负责将CRTC输出的时序转换成外部设备所需要的信号的模块,如HDMI转换器或DSI Controller
- Connector: 连接物理显示设备的连接器,如HDMI、DisplayPort、DSI总线,通常和Encoder驱动绑定在一起
0)涉及元素
详细了解可参考 DRM 学习简介 | 何小龙 。
- KMS:
CRTC,ENCODER,CONNECTOR,PLANE,FB,VBLANK,property - GEM:
DUMB,PRIME,fence
1)KMS:显示流程
首先理解 Framebuffer 是内存中的缓冲区,用于存储像素。其实一个平面可以包含多个 framebuffers ,例如一个用来存储全图(plane),一个 64x64 硬件光标(plane),这些 framebuffers 可以在硬件上混合在一起,以生成最终的 framebuffer。
现在,我们有了一个存储图片的缓冲区,我们把它分配给一个 CRTC (阴极射线管控制器)。
最后一步,在屏幕上打印一些东西。将流编码转换为定义好的协议,屏幕使用标准端口连接,例如 HDMI 、DVI、VGA 等。
2)GEM:显存管理
如果产生 3D 图形的内容,在应用层通过 OpenGL 调用,落到内核层的驱动如何管理呢? 调用 libdrm 接口,然后呢? 进入内核态 DRM 的 GEM 实现
- 需要与图形硬件交互,发送数据和命令,到对应的缓冲区或硬件
- 需要分配和管理显存,例如 纹理,颜色,深度等 buffer
4.3 源码视角(了解)
其实要实现既定的功能,可以直接调用 DRM 框架封装的接口。下面将以模式设置为例,源码角度看一下这个控制流。
1)用户视角
- 打开DRM设备文件 :
open("/dev/dri/card0"); - 获取显卡资源句柄 :
drmModeGetResources(...); - 获取connectorId :
drmModeGetConnector(...); - 创建FrameBuffer :
drmModeAddFB(...); - 设置Crtc模式 :
drmModeSetCrtc(crtc_id, fb_id, connector_id, mode); - 资源清理工作 :
modeset_cleanup(...);
2)内核视角
然后看接口 drmModeSetCrtc() 到内核态的执行过程
- Libdrm层 :
drmModeSetCrtc -> DRM_IOCTL(fd, DRM_IOCTL_MODE_SETCRTC, &crtc); -> drmIoctl(fd, cmd, arg); -> ioctl(fd, request, arg); - Kernel层 :
... -> amdgpu_kms_compat_ioctl -> amdgpu_drm_ioctl -> drm_ioctl -> ... -> drm_mode_setcrtc -> __drm_mode_set_config_internal -> drm_atomic_helper_set_config -> drm_atomic_commit - 将修改提交到硬件:
drm_atomic_commit 会调用 atomic_commit 接口(设备驱动程序注册到 struct drm_mode_config 对象下的接口),这是厂商自己实现的函数,例如 amdgpu_dm_atomic_commit
5 内核和固件
GPU 设备驱动程序是系统内核态的一个模块(这个系统运行在 CPU 上),而 GPU 固件是一个独立的系统(这个系统运行在 GPU 上)。硬件上它们相当一个多核异构。其实这里我比较关心的是驱动和固件之间的交互,两者之间的关系。
5.1 工作流程(掌握)
通过系统启动时和运行时的两个场景,大概理解下驱动和固件之间的交互过程
- GPU 驱动初始化 GPU 固件,并启动固件
- 驱动准备好顶点数据,流水线配置,命令队列,写到内存或者显存上
- 通知 GPU 固件新的命令队列的位置
- CP 中的固件同步命令队列,解析执行,并配置状态数据,设置图形流水管理模块
- GPU 开始干活,进入图形流水线
5.2 交互途径(掌握)
主机和固件有两种交互途径
1)寄存器组
- CPU 和 GPU 固件可以共同访问的一组通用寄存器
- 软件设计上 : 寄存器类型由软件定义
- 硬件结构上 : CPU - SREGS - EC
2)命令队列
- GPU 固件驱动 DMA 来通过 SRAM 和 DRAM
- 软件设计上 : RingBuffer 数据结构,通信协议由软件定义
- 硬件结构上 : SRAM - DMA - DRAM
5.3 寄存器组设计(掌握)
以下内容不便详细展开
- 共享寄存器组
- 命令通讯协议
5.4 通信协议设计(掌握)
以下内容不便详细展开
- 软硬件机制
- 数据一致性
- 命令包协议
6 固件和硬件
GPU 内部集成一个命令处理器(其实是一个MCU),它相当于 CPU 的一个异构核。从软件的视角来看,在这个命令处理器上运行一个轻量级的操作系统,我们叫做固件,它的一个关键的用途在与内核驱动通信,控制GPU的流水线;从硬件的视角来看,这个 CP(命令处理器)能与 CPU 交互,与 GPU 交互。
引入一张 AMD R600 的微架构图,其中 Command Processor(CP)是集成在 R600 上的,其中 HOST 和 CP 交互的一个重要方式是通过 DMA 搬运 HOST 系统内存上的命令队列到CP里的内存空间中,其中 CP 完成命令解析和执行后,通过中断线 Interrupts 通知 HOST 侧,然后驱动程序会响应这个中断信号并执行处理函数。

6.1 固件软件设计(掌握)
以下内容不便详细展开
- 软件系统模型
- 命令解析模型
6.2 软件硬件接口(了解)
使用 NVIDIA 的 CUDA 框架可以让程序员直接在 GPU 上运行 C程序,这样的程序在 GPU 上以 CUDA 线程的形式存在,编译器和硬件将 CUDA 线程聚合成一个线程组,硬件上有一个多线程 SIMD 处理器与之对应,在 GPU 内部有多个多线程的 SIMD 处理器。这里引入《Computer Organization and Design ARM edition》章节 6.6 的一段文字:
NVIDIA decided that the unifying theme of all these forms of parallelism is the CUDA Thread. Using this lowest level of parallelism as the programming primitive, the compiler and the hardware can gang thousands of CUDA threads together to utilize the various styles of parallelism within a GPU: multithreading, MIMD, SIMD, and instruction-level parallelism. These threads are blocked together and executed in groups of 32 at a time. A multithreaded processor inside a GPU executes these blocks of threads, and a GPU consists of 8 to 32 of these multithreaded processors.
6.3 体系结构简介(了解)
使用 NVIDIA GPU 体系结构说明。我的理解是,硬件上来看一个 GPU 包含多个 多线程的SIMD处理器(同时 GPU 也包含有其他的控制模块,比如线程块调度器,可以设计整体上实现流水线级的并行),每一个 多线程的SIMD处理器 包含多个 SIMD 通道(同时 SIMD处理器 也包含有其他的控制模块,比如 SIMD线程调度器),对应 SIMD 指令线程的并行计算,达到数据级并行的效果。以下是 SIMD处理器 数据通路的简略图,参考至《Computer Organization and Design ARM edition》图片 6.9

编译器和硬件将 CUDA 线程聚合成一个 SIMD 线程组,通过 线程块调度器 将 SIMD线程组 分配给多线程的SIMD处理器,先经过 SIMD 处理器内部的 SIMD 线程调度器,将准备好的 SIMD 指令线程调度到 SIMD 处理器上执行,SIMD 指令执行时会经过 SIMD 通道,到达 SIMD 处理器内部的局部存储器或者外部的全局存储器。
6.4 图形流水线(了解)
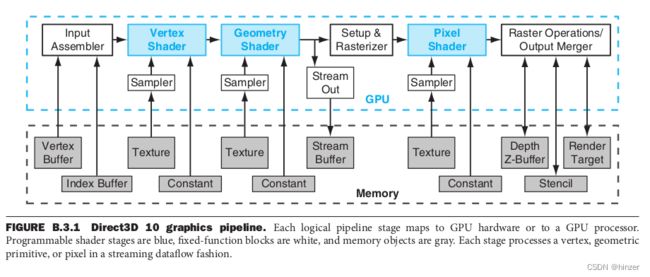
整体看 GPU 它是一个图形处理器,输入的指令和数据是 CPU 在系统内存或者显存上准备好的,进行图形处理后将结果写到系统内存或者显存地址空间。然后往下在深一层看 GPU 的工作原理,其实在 GPU 内部有多个硬件单元,构成一个多级图形流水线。大致过程如下
- 顶点数据: 用来为后面的顶点着色器等阶段提供处理的数据(顶点坐标、纹理坐标、顶点法线和顶点颜色等顶点属性)。
- 顶点着色器: 主要功能是进行坐标变换。
- 曲面细分: 是利用镶嵌化处理技术对三角面进行细分,以此来增加物体表面的三角面的数量,是渲染管线一个可选的阶段。
- 几何着色器: 将输入的点或线扩展成多边形,是渲染管线一个可选的阶段。
- 图元组装: 图元组装将输入的顶点组装成指定的图元。
- 光栅化: 是个离散化的过程,将3D连续的物体转化为离散屏幕像素点的过程。
- 片段着色器: 用来决定屏幕上像素的最终颜色。
- 测试混合阶段: 管线的最后一个阶段是测试混合阶段。
如果想要深入了解图形流水线的过程和步骤,我搞不太懂,不过可以参考《Computer Organization and Design ARM edition》附录 B.3.1。
7 参考资料
Computer Organization and Design ARM edition.pdf
r600isa.pdf
Linux GPU Driver Developer’s Guide — The Linux Kernel documentation
Introduction — Mesa 12.0 documentation
细说图形学渲染管线
说透芯片 | 极客时间
DRM架构介绍(一)| 阅码场
DRM学习简介 | 何小龙
Linux 图形栈一览:基于 DRM 和 Wayland | 泰晓科技
Linux graphic stack