LHY机器学习笔记-4
文章目录
- lhy机器学习笔记-4
-
- 深度学习三个步骤
-
- 神经网络
-
- 完全连接前反馈神经网络 FC
- 矩阵运算
- 模型评价
- 选取最优函数
- Backpropagation
-
- 以单个神经元为例考虑
-
- forward pass
- backward pass
- summary
lhy机器学习笔记-4
深度学习三个步骤
神经网络 -> 模型评估 -> 选择最优函数
神经网络
神经网络可以有很多不同的连接方式,这样就会产生不同的结构(structure)
神经网络中的所有的 权重 和 偏置 构成了 神经网络的参数 θ
完全连接前反馈神经网络 FC
前馈(feedforward)也可以称为前向,从信号流向来理解就是输入信号进入网络后,信号流动是单向的,即信号从前一层流向后一层,一直到输出层,其中任意两层之间的连接并没有反馈(feedback),亦即信号没有从后一层又返回到前一层。

给定了一个网络结构,就定义了 一个 函数集(function set)

网络结构解析:(如上图)
输入层
隐含层(hidden layer)
输出层
前后两层之间的神经元是两两连接的 称为 全连接
Deep Learning 深度学习 Deep = Many hidden layers
矩阵运算
每一个隐含层的权重和偏置都用向量表示,w1、b1,w2、b2,…,wl、bl


整个神经网络运算就相当于一连串的矩阵运算
可以用GPU加速矩阵运算
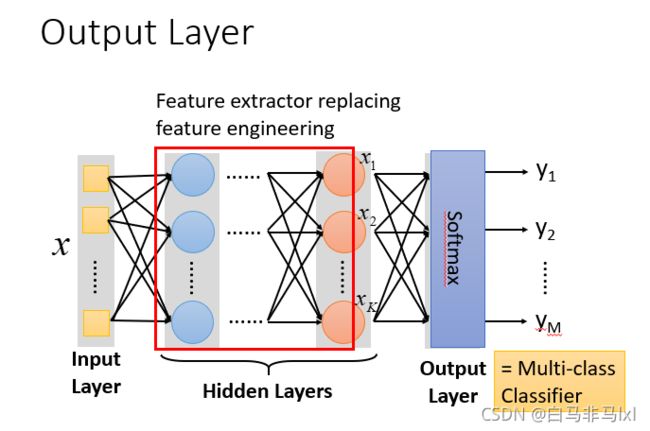
神经网络中的隐含层 是 一组 特征提取器 替代 人工的特征工程操作
output layer 为 多类的分类器
例子:手写数字识别
需自己设计隐含层:layer的数目、每个layer中神经元的数量
模型评价
交叉熵(cross entropy)函数来对 y 和\hat{y} 的损失进行计算
调整参数,让交叉熵越小越好
total loss:
L = ∑ n = 1 N C n L = \sum_{n=1}^N C^n L=n=1∑NCn
寻找 网络 参数 θ* 使得total loss 最小
选取最优函数
寻找方法:Gradient Descent

backpropagation 反向传播: 一个有效的方法去在神经网络中的计算 dL/dw
普遍性原理:
对于任何一个连续的函数,都可以用足够多的隐藏层来表示。
Backpropagation
反向传播(Backpropagation)是一个比较有效率的算法,让你计算梯度(Gradient) 的向量(Vector)时,可以有效率的计算出来
数学原理:chain rule (链式法则)
算法共分两部分:forward pass 和 backward pass
- 损失函数(Loss function)是定义在单个训练样本上的,也就是就算一个样本的误差,比如我们想要分类,就是预测的类别和实际类别的区别,是一个样本的,用L表示。
- 代价函数(Cost function)是定义在整个训练集上面的,也就是所有样本的误差的总和的平均,也就是损失函数的总和的平均,有没有这个平均其实不会影响最后的参数的求解结果。
- 总体损失函数(Total loss function)是定义在整个训练集上面的,也就是所有样本的误差的总和。也就是平时我们反向传播需要最小化的值。
L ( θ ) = ∑ n = 1 N C n ( θ ) L(\theta) = \sum_{n=1}^N C^n(\theta) L(θ)=n=1∑NCn(θ)
在利用梯度下降算法训练模型时,就是 让上述 总体损失函数对 模型中参数,比如权重和偏置求偏导
∂ L ( θ ) ∂ w = ∑ n = 1 N ∂ C n ( θ ) ∂ w \frac{\partial L(\theta)}{\partial w} = \sum_{n=1}^N \frac{\partial C^n(\theta)}{\partial w} ∂w∂L(θ)=n=1∑N∂w∂Cn(θ)
要计算上式,只需计算出每一个l^n,再求和,因此可以单独考虑每一个神经元
以单个神经元为例考虑
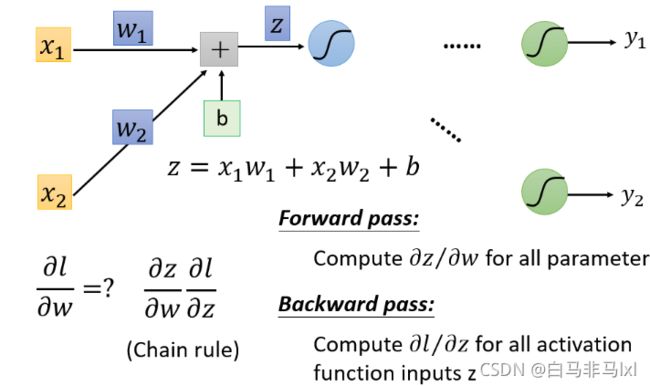
如上图,要计算 ∂ l ∂ w \frac{\partial l}{\partial w} ∂w∂l,只需分别计算两部分,forward pass 和 backward pass
forward pass
计算对所有参数的 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z
其值 等于 连接到这个权重上的 输入值
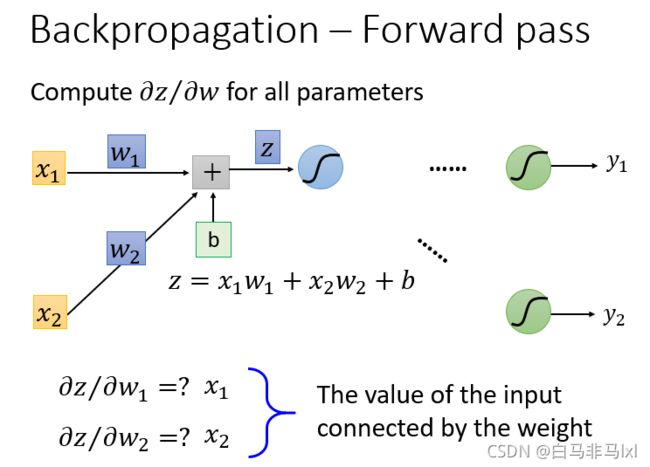
如上图中 偏导值 就是 x1 和 x2
backward pass

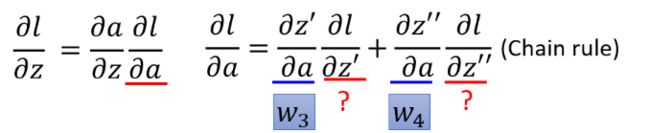
如上图,也利用链式法则对 其进行拆分求解
进一步,计算求解过程可分为两种情况
-
假设 ∂ l ∂ z ′ \frac{\partial l}{\partial z'} ∂z′∂l和 ∂ l ∂ z ′ ′ \frac{\partial l}{\partial z''} ∂z′′∂l是最后一层的隐藏层 也就是就是y1与y2是输出值,那么直接计算就能得出结果
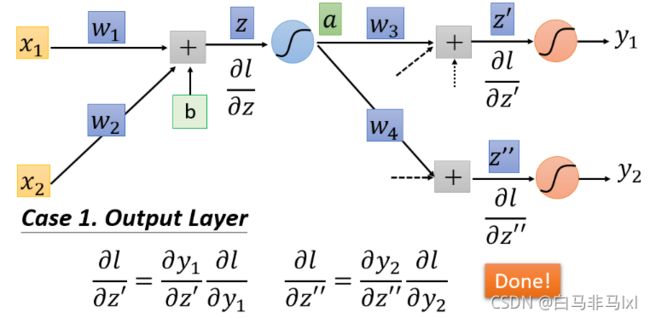
-
如果不是,那就需要递归地计算 ∂ l ∂ z \frac{\partial l}{\partial z} ∂z∂l 直到网络到达输出层

由于计算梯度的第二部分是要一层一层计算直到输出层,因此可以从后往前计算,称为backward pass
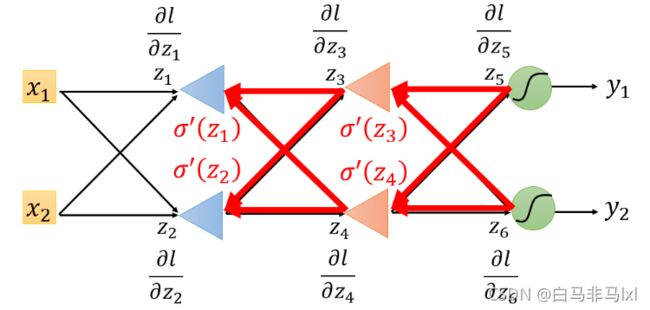
summary
目标是要求计算 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z (Forward pass的部分)和计算 ∂ l ∂ z \frac{\partial l}{\partial z} ∂z∂l ( Backward pass的部分 ),然后把 ∂ z ∂ w \frac{\partial z}{\partial w} ∂w∂z 和 ∂ l ∂ z \frac{\partial l}{\partial z} ∂z∂l 相乘,我们就可以得到 ∂ l ∂ w \frac{\partial l}{\partial w} ∂w∂l ,所有我们就可以得到神经网络中所有的参数,然后用梯度下降就可以不断更新,得到损失最小的函数
