【实际操作】DenseFusion复现过程详解-LineMOD数据集
DenseFusion系列代码全讲解目录:【DenseFusion系列目录】代码全讲解+可视化+计算评估指标_Panpanpan!的博客-CSDN博客
这些内容均为个人学习记录,欢迎大家提出错误一起讨论一起学习!
最近在做DenseFusion的复现,由于刚接触这块,绕了很多弯路。源代码是在linux上面跑的,但我自己的电脑没部署linux环境,于是在Windows上面跑,但最后会报错一个c语言头文件问题,未能解决,果断放弃,转战Colab,但由于环境版本不匹配,最后也失败了。于是找导师要了服务器,最后运行成功,下面重新从头在linux上跑一下,记录整个过程。
首先,官方开源代码是Pytorch0.4.1,这对我的Cuda不兼容,我用的Pytorch1.0版本的,代码源如下:
Pytorch0.4.1版本链接
Pytorch1.0版本链接
其次,DenseFusion原论文里面用到了两个数据集,分别是YCB_Video数据集和LineMOD数据集,由于YCB_Video太大(两百多G),我只用了LineMOD数据集。
【YCB-Video数据集已发】
部署环境
在anaconda下创建一个叫densefusion的环境,指定python版本为3.6
conda create --name densefusion python=3.6激活densefusion环境
conda activate densefusion下载cuda10.0+Pytorch1.0
到Pytorch官网找到相应的命令下载,对应我的版本号为:
# CUDA 10.0
conda install pytorch==1.0.0 torchvision==0.2.1 cuda100 -c pytorch如果下载速度太慢就添加国内镜像下载CondaHTTPError问题的解决 - 我们都是大好青年 - 博客园
添加后将 -c pytorch去掉再执行
然后进入到python,输入以下代码查看torch版本和cuda版本以及cuda是否可用
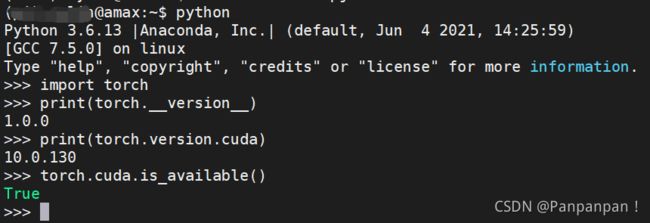
返回这个样子就代表部署好了,中途可能会遇到torch无法import的状况,可能是没有安装相应的版本号,或者缺少mlk库。运行过程中也会存在报错缺少某某库,直接pip install就行了。
数据集准备
首先将DenseFusion-Pytoch-1.0文件夹放在我的一个work文件夹里边,为了避免和我第一次实验的重复,重命名为DenseFusion,路径为/work/DenseFusion。进入该文件夹:
#可能需要修改文件权限,不然进不去
chmod -R 777 /work/DenseFusion
cd /work/DenseFusion官方说首先需要执行以下命令:

这个命令是下载三个东西,YCB_Video数据集、LineMOD数据集和trained checkpoints到指定位置,但我执行失败了,好像是网站有问题,也可能是数据集太大了。
但做实验的话我目前只需要LineMOD数据集,trained checkpoints目前还没用到。LineMOD数据集在网上可以找到自行下载,然后上传到/work/DenseFusion/datasets/linemod文件夹下边,上传需要一定的时间。
开始训练
这是官方给的训练步骤:

但我会报错:
AttributeError: module 'lib.knn.knn_pytorch' has no attribute 'knn'
原因是1.0版本的knn是需要编译的,不同环境编译出的模型都不一样,下面对模型进行编译。
首先进入到该文件夹下,执行build和install两个步骤:
cd /work/DenseFusion/lib/knn
python setup.py build
python setup.py install出现下面的样子就对了:
![]() 执行完之后会在lib/knn文件夹下面出现一个dist文件夹,里面是编译好的.egg文件,下面将这个文件解压:
执行完之后会在lib/knn文件夹下面出现一个dist文件夹,里面是编译好的.egg文件,下面将这个文件解压:
cd dist
unzip knn_pytorch-0.1-py3.6-linux-x86_64.egg #输入你自己的编译文件名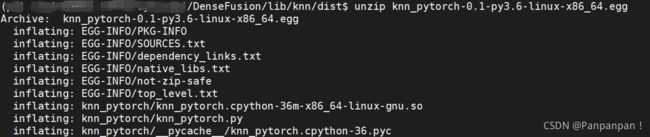
解压后会在dist文件夹里面生成两个文件夹:

进入knn_pytorch文件夹里面,将下面两个文件移动到/work/DenseFusion/lib/knn里面:
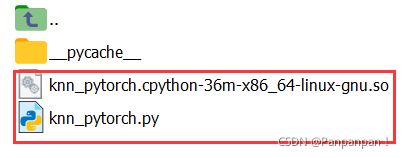
cd knn_pytorch
cp knn_pytorch.cpython-36m-x86_64-linux-gnu.so /work/DenseFusion/lib/knn
cp knn_pytorch.py /work/DenseFusion/lib/knn再返回到DenseFusion根目录执行./experiments/scripts/train_linemode.sh

开始训练了,这个步骤会很长,这里我为了快点跑通,将最大epoch调成2(可以在tools/train.py里面设置参数,源码里面是500次)

每次训练后会进行测试, 然后会保存最好的模型:

但我发现我的模型只有姿势估计部分的,没有refine的模型,原因是因为我迭代次数太少了,模型精度达不到要求,所以不会开始refine的步骤,于是我把开始refine的精度调整了一下,再开始训练,发现开始refine了,但最后报错:
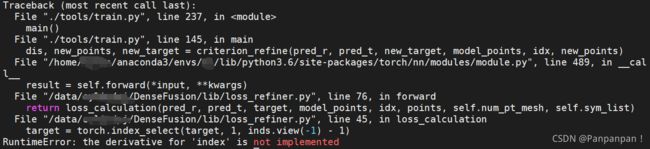
RuntimeError: the derivative for 'index' is not implemented
这是因为训练达到了我刚刚修改的损失值,于是要开始训练refine,只用将lib/loss_refiner.py的45行改成:
target = torch.index_select(target, 1, inds.view(-1).detach() - 1)加了.detach()就好了,然后重新训练。
开始测试
还是按照官网的步骤执行./experiments/scripts/eval_linemod.sh:

会报如下错误:

FileNotFoundError: [Errno 2] No such file or directory: 'trained_checkpoints/linemod/pose_model_9_0.01310166542980859.pth'
这是因为没有trained_checkpoints文件夹,但我没加入这个文件夹,而是用刚刚自己训练的模型,修改/experiments/scripts/eval_linemod.sh文件里面的代码,或者直接在命令行运行:
python3 ./tools/eval_linemod.py --dataset_root ./datasets/linemod/Linemod_preprocessed --model trained_models/linemod/pose_model_current.pth --refine_model trained_models/linemod/pose_refine_model_current.pth
其中 trained_models/linemod/pose_model_current.pth是刚刚训练保存下来的姿态估计模型,trained_models/linemod/pose_refine_model_current.pth是迭代自优化模型,然后就,成功了!
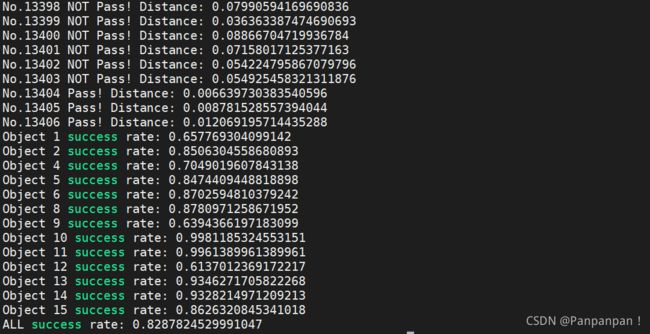
跑通了就好,精度啥的以后再说吧!
开始测试
执行./experiments/scripts/eval_linemod.sh会对训练的模型进行测试,当然是eval模式,test的部分在训练的过程中就已经进行了。
eval的时候可能还有以下错误:

直接添加参数Loder = yaml.FullLoader,即:
meta = yaml.load(meta_file,Loader=yaml.FullLoader)这里看看eval_linemod.sh文件里面的内容:
#!/bin/bash
set -x
set -e
export PYTHONUNBUFFERED="True"
export CUDA_VISIBLE_DEVICES=0
python3 ./tools/eval_linemod.py --dataset_root ./datasets/linemod/Linemod_preprocessed\
--model trained_checkpoints/linemod/pose_model_9_0.01310166542980859.pth\
--refine_model trained_checkpoints/linemod/pose_refine_model_493_0.006761023565178073.pth这里意思是执行eval_linemod.py程序,--dataset_root为linemod数据集路径,--model为保存的PoseNet模型,--refine_model为保存的PoseRefineNet模型,这里可以用trained_checkpoints里面已经训练好的模型,也可以用自己训练的模型,也就是保存在trained_models文件夹下的模型,改一下模型路径就好了。
主要参考两篇博客:
姿态估计0-02:DenseFusion(6D姿态估计)-源码训练测试,报错解决_江南才尽江南山,年少无知年少狂!-CSDN博客_densefusion训练
DenseFusion代码复现 - 木芯子 - 博客园