一键构建云上高可用蛋白质结构预测平台

简介
Deepmind团队于2021年7月公开了Alphafold2算法源代码和相关论文,这一方案被认为可解决困扰生物学长达半个世纪的蛋白质折叠结构预测难题,其准确度高达92.4(百分制)。Alphafold2基于新颖的机器学习方法,以原子精度预测蛋白质结构,在大部分情况下表现出与实验相媲美的准确性,且大大优于其他方法。但截至目前,其官方的单机部署方式需要人工下载数据集并解压、处理输入输出数据以及执行任务脚本,无法实现弹性按需使用,不适用于大规模的蛋白质结构预测。
在本文的案例中,我们首先设计了基于API+HPC的任务调度逻辑,由Amazon Lambda作为无服务器后端,处理用户提交的任务请求并通过Amazon SQS消息队列服务对其进行解耦;然后将任务请求提交到Amazon Batch调用GPU计算实例,并分析Alphafold2算法的源代码结构进行分析,并将其优化为Amazon Batch可使用的容器镜像格式,存储于Amazon ECR托管容器存储库中;Alphafold2算法所使用的蛋白质数据库文件均位于Amazon Fsx for Lustre高性能分布式文件系统中;用户提交的任务过程信息使用Amazon Dynamodb作为NoSQL数据库存储,所有输入的氨基酸序列文件和输出的蛋白质结构预测文件均使用Amazon S3对象存储;算法科学家可使用基于NICE DCV的高性能远程桌面,通过goofys协议挂载Amazon S3目录,直接在云上可视化分析Alphafold2生成的蛋白质结构预测文件。最后,针对以上部署过程,通过Amazon CDK打包实现基础设施即代码化,方便客户一键部署。
注:本文所用代码目前托管于:
https://github.com/wttat/alphafold
https://github.com/wttat/af2-batch-cdk
整体架构
亚马逊云科技服务需求
Amazon API Gateway,可以帮助开发人员轻松创建、发布、维护、监控和保护任意规模的 API。
Amazon Lambda,几乎可以为任何类型的应用程序或后端服务运行代码,而且完全无需管理。
Amazon S3,对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能。
Amazon SQS, 消息队列服务,可以帮助分离和扩展微服务、分布式系统和无服务器应用程序。
Amazon DynamoDB,快速、灵活的 NoSQL 数据库服务,可在任何规模下实现个位数毫秒级的性能。
Amazon Batch,任意规模完全受管的批处理调度系统,让开发人员、科学家和工程师能够轻松高效地运行成千上万个批处理计算作业。
Amazon ECR,完全托管的容器注册表,在任何地方轻松存储、管理、共享和部署容器映像和构件。
Amazon SNS,完全托管的发布/订阅消息收发、SMS、电子邮件和移动推送通知。
Amazon EventBridge,大规模构建事件驱动型应用程序,涵盖亚马逊云科技、现有系统或 SaaS 应用程序
架构说明

API 的设计
为向算法科学家屏蔽底层GPU算力调度过程,提供一个统一易用的Alphafold2任务调度入口,我们使用API Gateway创建RESTful API,对外暴露单一URL接口,实现对Alphafold2服务的应用级封装。API Gateway为云原生托管API管理工具,对用户提交的任务查询或调度请求鉴权,通过后将其按照配置的路由发送到不同的Amazon Lambda后端。Amazon Lambda函数对请求进行解析,将任务信息写入数据库,并将任务参数投递到HPC集群。共有四个Amazon Lambda函数与API Gateway直接或间接相关联,包括身份鉴权函数、查询请求处理函数、调度请求处理函数以及HPC集群调度函数,此处我们将调度请求处理函数与HPC集群调度函数通过SQS消息队列服务进行解耦,从而提高了API架构的可用性。
API参数的所有接口如下,算法科学家可直接通过API的形式对Alphafold2任务进行操作。
GET / :查询所有任务信息。
GET /{id} :查询单条任务详细信息,包含最近的Cloudwatch log日志。
POST / :投递任务,任务信息包含在HTTP的body中。
DELETE /:删除所有已完成或失败的任务信息及其对应的Amazon S3资源(如有)。
DELETE /{id}:删除单条所有已完成或失败的任务信息及其对应的S3资源(如有)。
CANCEL /:取消所有正在运行的任务。
CANCEL /{id}:取消单条正在运行的任务。

注:ANY方法对应CANCEL方法。
云上 HPC 批处理平台
本次方案的云上HPC批处理平台共由四部分组成:
Amazon S3作为云原生的对象存储服务,拥有11个9的高持久性以及完善的安全和合规机制,因此我们使用Amazon S3持久化存储Alphafold2任务的输入输出文件,保障所有数据文件在云上的安全。在Amazon S3桶中,共有input和output两个文件夹,分别用于存放要预测的氨基酸序列文件和2.Alphafold2预测产生的蛋白质结构文件。用户可通过多种方式方便的检索、下载上述文件,同时可以选择Amazon S3中的多种存储类,降低云上存储成本。
为实现对Alphafold2优化镜像的统一托管,我们使用Amazon ECR作为容器镜像存储仓库,免去了用户自建容器镜像仓库的繁琐流程。我们对Alphafold2代码做了一定的优化,使其能够接受Amazon Batch作业的参数和环境变量输入,并且使其能够使用Amazon S3作为文件存储,并重新打包为Docker镜像,Amazon ECR支持与Amazon Batch无缝集成,将打包后Docker镜像上传至Amazon ECR后,即可以直接在Batch的作业定义中指定存储在Amazon ECR中的Alphafold2容器镜像地址进行拉取。
Alphafold2每次预测蛋白质结构均需要通过Multiple Sequence Alignment (多重序列比对, MSA),对已知蛋白质结构数据库进行扫描,目前数据集总容量约为2.2T。为了实现数据集的高性能共享访问,我们将其存储在FSx for Lustre上,使其能够被所有任务所同时访问并高速读取。Fsx for Lustre可提供百兆级别吞吐、百万级别IOPS以及稳定的亚豪秒延迟,从而满足Alphafold2在内的HPC计算工作负载。
为实现计算资源的弹性扩展、降低整体计算和运维成本,我们使用Amazon Batch搭建蛋白质结构预测HPC批处理集群,由Batch内置的调度器根据用户提交的蛋白质结构预测任务和资源需求自动化预置所需要的GPU计算资源。我们目前针对亚马逊云科技可提供的GPU实例类型,选择了p3.2xlarge、p3.8xlarge、p3.16xlarge以及p4d.24xlarge四种机型作为计算环境,用户可根据单条预测任务使用的GPU数量、任务并行度和成本综合考虑选择投递任务的作业队列,而无需关心其底层实例的部署以及环境的搭建。所有计算环境均可配置为在任务结束后即自动关闭所有计算实例节约成本。
任务信息数据存储
Amazon DynamoDB作为云原生的无服务器NoSQL数据库,无需预置服务器,按使用量付费,同时拥有一致性的毫秒级访问性能以及近乎无限的吞吐量和存储空间。本次方案使用DynamoDB存储Alphafold2过程中产生的任务信息,满足用户并发提交或查询任务时的性能需求,同时优化成本,简化数据库配置流程。在处理任务提交的Amazon Lambda函数中,使用了UUID算法随机生成每条任务的id,作为DynamoDB分区键,提高任务查询效率。
消息与结果通知
单机部署Alphafold2时,其运行过程的所有日志均位于Docker中,如果运行环节中出现任何问题,均需要手动登陆实例后,通过docker log等命令进行查看;同时任务完成后缺乏相关通知推送,无法及时获取其运行状态,造成计算资源的浪费。
我们使用Amazon S3的事件通知机制以及Amazon EventBridge服务,自动获取Amazon S3中压缩文件的上传文件事件以及Amazon Batch任务失败事件——分别对应Alphafold2任务的成功和报错,自动触发不同的Amazon Lambda函数处理相关事件,更新任务信息数据库,最后通过Amazon SNS——即亚马逊云科技云上托管的消息收发服务,通过邮箱或者短信等方式向算法科学家推送相关信息,实现Alphafold2作业信息的即时通知。消息通知中包含任务信息、所需时间、下载链接以及Amazon CLI命令。算法科学家无需登陆亚马逊云科技控制台,即可直接获取Alphafold2任务结果的下载方式。
便捷可视化终端
为满足算法科学家远程分析蛋白质结构的需求,我们使用NICE DCV远程桌面作为蛋白质结构便捷可视化终端,启动后可以直接通过浏览器或NICE DCV客户端,使用图形化界面远程访问。NICE DCV基于优化的NICE DCV协议,根据网络情况自适应调整传输带宽,同时可利用预装了NVIDIA T4显卡的Amazon G4实例,提高图形密集性软件的渲染性能,从而使算法科学家远程通过如Pymol或VMD等蛋白质三维结构可视化软件进行分析。
部署方法
初始化 Amazon CDK 环境
cdk bootstrap aws://{ACCOUNTID}/{REGION}

通过 Amazon CDK生成
Amazon CloudFormation 模板
cdk synth
![]()
一键部署所有资源
cdk deploy –all

需要手动确认,输入y回车即可,中间会输出一些过程信息,并且在邮箱中点击确认SNS订阅。



部署完成
约需要四个小时将所有数据下载并解压到FSx for Lustre,解压完成后,会收到电子邮件通知,此时即可根据使用说明,开始投递Alphafold2任务
算法科学家使用过程

完成上述方案构建后,算法科学家即可开始使用Alphafold2算法预测蛋白质结构。
总共可分别四个步骤:
1.上传氨基酸序列文件
通过Amazon CLI或者控制台将氨基酸序列文件上传到Amazon S3存储桶的input文件夹。

2.提交任务或查询任务进度
通过终端或者HTTP调试软件操作任务。本文以Postman调试软件为例,演示如何基于API提交、查询任务。取消和删除任务操作类似,可参考API Gateway中的路由设置进行提交。
首先编辑任务请求JSON文件,例:

可以参考:
https://github.com/wttat/af2-batch-cdk/blob/main/command.json
其中,
fasta 为本次预测的蛋白质名称,由用户自定义,必选;
file_name为氨基酸序列名称,必须与S3存储桶中的文件名称对应,必选;model_names为所使用的Alphafold2模型,共有model1-model5五个可选,缺省值为五个模型全部使用;
preset为使用的预设配置,full对应完整数据集,reduced对应压缩数据集,CASP14对应deepmind团队参赛时所使用的配置,缺省值为full;
max_template_date为扫描已知数据库中蛋白质结构文件的截止日期,缺省值为2020-05-14;
que为batch使用的作业队列,low对应batch的计算环境为p3.2xlarge实例,mid对应计算环境为p3.8xlarge实例,high对应计算环境为p3.16xlarge实例,p4对应计算环境为p4d.24xlarge实例,必选;
comment为用户自定义的注释语句,可选,缺省值为空;
gpu为使用GPU数量,并且成比例对应vCPU和内存,可选,缺省值为1。例:p3.8xlarge实例中共有4块NVIDIA Tesla V100显卡,32vCPU和244G内存,默认情况下,即gpu为1时,每个任务分配8vCPU、61G内存和一块V100显卡,可同时运行四个任务,如果gpu设置为2时,该任务分配到16vCPU、122G内存和两块V100显卡,此时p3.8xlarge实例剩下两块显卡,可分配给两个gpu为1的任务或者一个gpu为2的任务。
首先配置Headers,键为Authorization,值为用户自己定义的密钥。

(1)提交任务
将HTTP方法设置为post,URL填入API Gateway的URL,Body选择raw,格式为JSON,粘贴任务请求JSON文件,点击Send即可提交任务,后台即会根据选择的作业队列自动拉起对应的计算资源运行预测任务。API Gateway会返回每个预测任务对应的ID。

(2)查询任务
将方法修改为GET,即可查询所有任务信息。
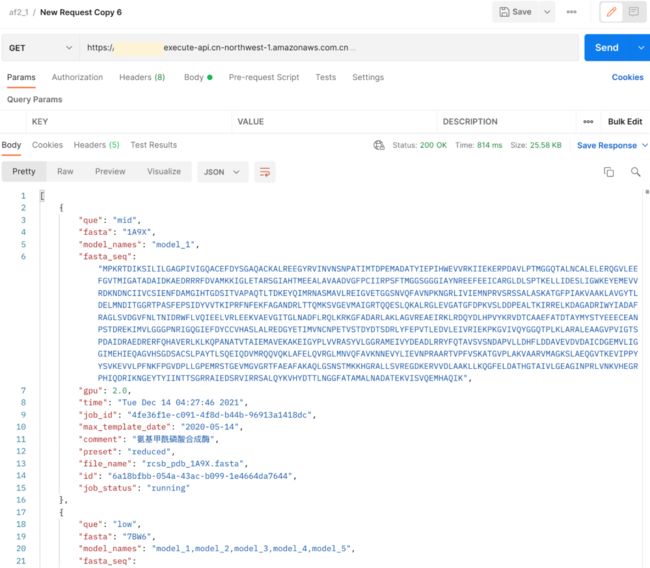
若想查询单条任务详细信息,则在URL后面加上对应任务的ID,可通过查询所有任务信息得到,也可以在提交任务后直接复制返回的ID。

其中job info为任务相关参数,job status为任务当前状态,若有日志产生,则会自动抓取最新的Amazon CloudWatch日志并返回。
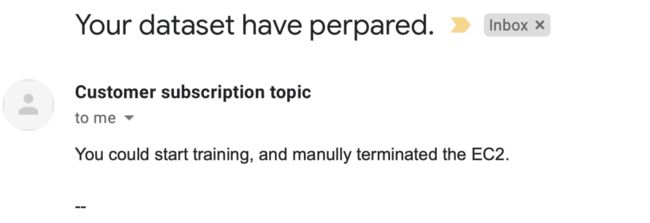
3.Email自动化发送任务结果
任务完成后,会收到邮件通知提醒,告知其对应预测任务已完成。邮件正文中,包括完成预测所需时间,即可根据使用的机器类型计算成本,以及所有文件的下载链接HTML文件,同时提供了Amazon cli命令行,用户可自行选择下载方式。

打开下载链接HTML后,即可根据需求自行选择下载整体压缩包或者pdb文件进行分析。

4.可视化分析
以pymol为例,连接到NICE DCV上后,安装并运行pymol:
wget https://pymol.org/installers/PyMOL-2.5.2_293-Linux-x86_64-py37.tar.bz2
tar -jxf PyMOL-2.5.2_293-Linux-x86_64-py37.tar.bz2
./pymol/pymol*左滑查看更多
打开桌面上Amazon S3文件夹,找到需要分析的蛋白质文件夹,将pdb文件拖拽到pymol中打开即可直接在云上分析蛋白质结构。

也可以自行安装VMD进行分析。
成本估算
(仅供参考)
我们基于P3实例和P4实例,测试了不同序列长度的氨基酸序列,经过Alphafold2算法预测其蛋白质结构所需时间,并且根据对应区域GPU实例单价,按比例换算为每条任务所需成本。可以看到:随着序列长度的增加,所需时间快速增加,主要是由于GPU推理时间占比显著增加;在序列长度超过1000时,一块V100会提示显存不足的问题,需要两块V100显卡才能跑完完整任务;在序列长度越长的情况下,P4实例挂载的A100显卡带来的性能提升越明显。
中国宁夏区域(cn-northwest-1):

美国弗吉尼亚北部区域(us-east-1):
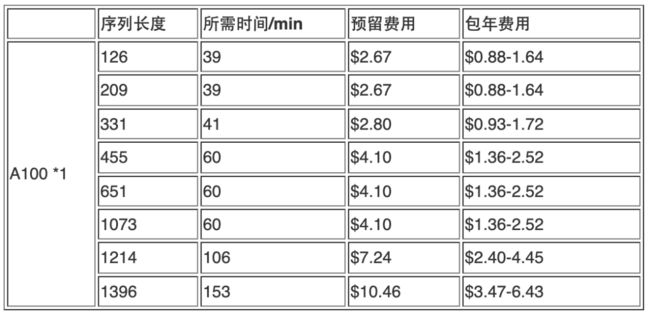
注:FSx for Lustre费用未考虑在内,需要按月收取。
优化方向
目前Alphafold2官方源代码还在不断优化迭代之中,还存在许多可以性能提升的方向。如:
前期扫描数据集的MSA过程只消耗CPU资源,并不占用GPU,因此可以据此将CPU和GPU运算过程接耦,拆分为两个子任务,降低成本;
通常情况下,我们只需要评分最好的模型,而Alphafold2算法目前的机制默认为完整推理五个模型,可以将其修改为只预测评分最高的模型。
MSA中多个模块可以CPU并行运行,提升扫描速度。
用户可以根据自己的需要,对其进行二次开发,自行修改并构建Alaphfold2镜像,只需将Amazon Batch作业定义中的容器镜像地址替换为用户指定的镜像地址即可。
总结
我们首先基于Amazon Batch的作业需求,容器化改造了Alphafold2镜像,使其能够接受来自Amazon Batch标准化的输入参数,并且将输出文件直接上传到Amazon S3上。接下来,使用根据负载可弹性扩展的GPU计算集群和高性能共享存储,可满足大规模高并发的预测需求。并且,基于Amazon Batch提供完善的集群资源调度机制,降低计算资源成本以及IT部门运维复杂度,实现秒级的成本监控。算法科学家基于Amazon API GW提交/查询/删除任务,无需接触亚马逊云科技资源,同于由于所有操作均基于API实现,因此可方便集成至现有工作流中。其次,基于Amazon SNS提供作业状态提醒机制,针对任务的成功和失败均有邮件提醒,并在任务成功的通知邮件集成了蛋白质结构文件的下载地址。基于Amazon CDK实现方案的灵活快速部署,用户可在半小时内将完整架构部署于自己的亚马逊云科技资源中,四个小时内预测服务即可上线使用。
参考
Amazon API Gateway官方文档:
https://docs.aws.amazon.com/zh_cn/apigateway/?id=docs_gateway
Amazon Lambda官方文档:
https://docs.aws.amazon.com/zh_cn/lambda/?id=docs_gateway
Amazon S3官方文档:
https://docs.aws.amazon.com/zh_cn/s3/?id=docs_gateway
Amazon SQS官方文档:
https://docs.aws.amazon.com/zh_cn/sqs/?id=docs_gateway
Amazon DynamoDB官方文档:
https://docs.aws.amazon.com/zh_cn/dynamodb/?id=docs_gateway
Amazon Batch官方文档:
https://docs.aws.amazon.com/zh_cn/batch/?id=docs_gateway
Amazon ECR官方文档:
https://docs.aws.amazon.com/zh_cn/ecr/?id=docs_gateway
Amazon SNS官方文档:
https://docs.aws.amazon.com/zh_cn/sns/?id=docs_gateway
AlphaFold官方代码:
https://github.com/deepmind/alphafold
本篇作者

吴桐
亚马逊云科技解决方案架构师
负责基于亚马逊云科技云计算方案的架构咨询和设计实现,目前在亚马逊云科技 Public Sector服务生命科学和医疗健康相关行业客户,具有丰富的解决客户实际问题的经验。

张强
亚马逊云科技解决方案架构师
在加入亚马逊云科技之前,拥有多年生物信息开发经验,熟悉传统工作流与HPC环境迁移至云原生技术的技术实现,目前服务于生命科学和医疗健康相关行业客户,如医学影像、基因组学、药物研发等,致力于提供有关HPC、无服务器、数据安全等各类云计算解决方案的咨询与架构设计。


听说,点完下面4个按钮
就不会碰到bug了!
